Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Game playing Kecerdasan Buatan Pertemuan 5 IT-EEPIS

2
Kenapa mempelajari games?
Kriteria menang atau kalah jelas Dapat mempelajari permasalahan Menyenangkan Biasanya mempunyai search space yang besar (misalnya game catur mempunyai nodes dalam search tree dan 1040 legal states)
")
3
Seberapa hebat computer game player?
Catur: Deep Blue mengalahkan Gary Kasparov pada tahun 1997 Gary Kasparav vs. Deep Junior (Feb 2003): seri Checkers: Chinook adalah juara dunia Go: Computer player adalah sangat tangguh Bridge: computer players mempunyai “Expert-level”
: seri. Checkers: Chinook adalah juara dunia. Go: Computer player adalah sangat tangguh. Bridge: computer players mempunyai Expert-level")
4
Permainan Catur Deep Blue
Deep Blue adalah sebuah komputer catur buatan IBM. Deep Blue adalah komputer pertama yang memenangkan sebuah permainan catur melawan seorang juara dunia (Garry Kasparov) dalam waktu standar sebuah turnamen catur. Kemenangan pertamanya (dalam pertandingan atau babak pertama) terjadi pada 10 Februari 1996, dan merupakan permainan yang sangat terkenal. Namun Kasparov kemudian memenangkan 3 pertandingan lainnya dan memperoleh hasil remis pada 2 pertandingan selanjutnya, sehingga mengalahkan Deep Blue dengan hasil 4-2.
 dalam waktu standar sebuah turnamen catur. Kemenangan pertamanya (dalam pertandingan atau babak pertama) terjadi pada 10 Februari 1996, dan merupakan permainan yang sangat terkenal. Namun Kasparov kemudian memenangkan 3 pertandingan lainnya dan memperoleh hasil remis pada 2 pertandingan selanjutnya, sehingga mengalahkan Deep Blue dengan hasil 4-2.")
5
Permainan Catur Deep Blue
Deep Blue lalu diupgrade lagi secara besar-besaran dan kembali bertanding melawan Kasparov pada Mei Dalam pertandingan enam babak tersebut Deep Blue menang dengan hasil 3,5-2,5. Babak terakhirnya berakhir pada 11 Mei. Deep Blue menjadi komputer pertama yang mengalahkan juara dunia bertahan. Komputer ini saat ini sudah "dipensiunkan" dan dipajang di Museum Nasional Sejarah Amerika (National Museum of American History), Amerika Serikat.
, Amerika Serikat.")
6
Permainan Catur Deep Blue

7
Garry Kasparov and Deep Blue. © 1997,
GM Gabriel Schwartzman's Chess Camera, courtesy IBM.

8
Ratings of human and computer chess champions

10
January/February 2003

11
Ciri umum pada game 2 pemain Kesempatan pemain bergantian
Zero-sum: kerugian seorang pemain adalah keuntungan pemain lain Perfect information: pemain mengetahui semua informasi state dari game Contoh: Tic-Tac-Toe, Checkers, Chess, Go, Nim, Othello Tidak mengandung probabilistik (seperti dadu) Game tidak termasuk Bridge, Solitaire, Backgammon, dan semisalnya
 Game tidak termasuk Bridge, Solitaire, Backgammon, dan semisalnya.")
12
Bagaimana bermain game?
Cara bermain game: Pertimbangkan semua kemungkinan jalan Berikan nilai pada semua kemungkinan jalan Jalankan pada kemungkinan yang mempunyai nilai terbaik Tunggu giliran pihak lawan jalan Ulangi cara diatas Key problems: Representasikan “board” atau “state” Buatlah next board yang legal Lakukan evaluasi pada posisi

13
Evaluation function Evaluation function atau static evaluator digunakan untuk mengevaluasi nilai posisi yang baik Zero-sum assumption membolehkan untuk menggunakan single evaluation function untuk mendeskripsikan nilai posisi f(n) >> 0: posisi n baik untuk saya dan jelek untuk lawan f(n) << 0: posisi n jelek untuk saya dan baik untuk lawan f(n) near 0: posisi n adalah posisi netral/seri f(n) = +infinity: saya menang f(n) = -infinity: lawan menang
 >> 0: posisi n baik untuk saya dan jelek untuk lawan. f(n) << 0: posisi n jelek untuk saya dan baik untuk lawan. f(n) near 0: posisi n adalah posisi netral/seri. f(n) = +infinity: saya menang. f(n) = -infinity: lawan menang.")
14
First three levels of tic-tac-toe state space reduced by symmetry

15
The “most wins” heuristic

16
Heuristically reduced state space for tic-tac-toe

17
Consider this position
We are playing X, and it is now our turn. X = Computer, O = opponent

18
Let’s write out all possibilities
X move Each number represents a position after each legal move we have.

19
Now let’s look at their options
O move Here we are looking at all of the opponent responses to the first possible move we could make.

20
Now let’s look at their options
Opponent options after our second possibility. Not good again…

21
Now let’s look at their options
Struggling…

22
More interesting case Now they don’t have a way to win on their next move. So now we have to consider our responses to their responses.

23
Our options We have a win for any move they make.
So the original position in purple is an X win.

24
Finishing it up… They win again if we take our fifth move.

25
Summary of the Analysis
So which move should we make? ;-)
")
26
+ + + Game Nim Diawali serangkaian batang
Setiap pemain harus memecah serangkaian batang menjadi 2 kumpulan dimana jumlah batang di tiap kumpulan tidak boleh sama dan tidak boleh kosong + + +

27
A variant of the game nim
A number of tokens are placed on a table between the two opponents A move consists of dividing a pile of tokens into two nonempty piles of different sizes For example, 6 tokens can be divided into piles of 5 and 1 or 4 and 2, but not 3 and 3 The first player who can no longer make a move loses the game For a reasonable number of tokens, the state space can be exhaustively searched

28
State space for a variant of nim
Note that state is repeated. We can simplify the structure by drawing a general graph.

29
State space for a variant of nim

30
Search techniques for 2-person games
The search tree is slightly different: It is a two-ply tree where levels alternate between players Canonically, the first level is “us” or the player whom we want to win. Each final position is assigned a payoff: win (say, 1) lose (say, -1) draw (say, 0) We would like to maximize the payoff for the first player, hence the names MAX & MINIMAX
 lose (say, -1) draw (say, 0) We would like to maximize the payoff for the first player, hence the names MAX & MINIMAX.")
31
Minimax John von Neumann pada tahun 1944 menguraikan sebuah algoritma search pada game, dikenal dengan nama Minimax, yang memaksimalkan posisi pemain dan meminimalkan posisi lawan

32
The search algorithm The root of the tree is the current board position, it is MAX’s turn to play MAX generates the tree as much as it can, and picks the best move assuming that Min will also choose the moves for herself. This is the Minimax algorithm which was invented by Von Neumann and Morgenstern in 1944, as part of game theory. The same problem with other search trees: the tree grows very quickly, exhaustive search is usually impossible.

33
Special technique MAX generates the full search tree (up to the leaves or terminal nodes or final game positions) and chooses the best one: win or tie To choose the best move, values are propogated upward from the leaves: MAX chooses the maximum MIN chooses the minimum This assumes that the full tree is not prohibitively big It also assumes that the final positions are easily identifiable We can make these assumptions for now, so let’s look at an example
 and chooses the best one: win or tie. To choose the best move, values are propogated upward from the leaves: MAX chooses the maximum. MIN chooses the minimum. This assumes that the full tree is not prohibitively big. It also assumes that the final positions are easily identifiable. We can make these assumptions for now, so let’s look at an example.")
34
MAX A MIN B C D E F G MAX 1 1 -3 4 1 2 -3 4 -5 -5 1 -7 2 -3 -8
= terminal position = agent = opponent

35
2 7 1 8 2 7 1 8 2 7 1 8 2 7 1 8 MAX MIN Jalan yang dipilih
oleh Minimax Static evaluator value MAX MIN

36
Minimax applied to a hypothetical state space (Fig. 4.15)
")
37
Asumsi MIN bermain dulu Evaluation function: 0 MIN menang
1 MAX menang

38
Complete State Space for Nim

39
1 7 6-1 5-2 4-3 5-1-1 4-2-1 3-2-2 3-3-1 MIN MAX 1 1 1 1 1 1 1

40
1 1 1 1 1 1 1 1
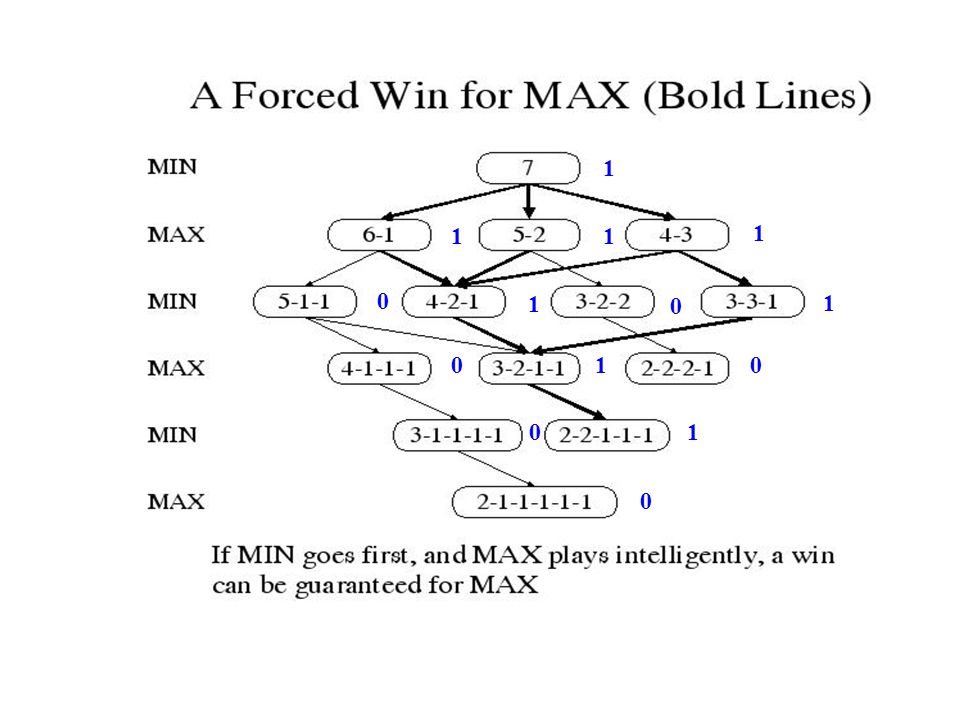
41
Minimax for Tic Tac Toe In our tic tac toe example,
player 1 is 'X’ player 2 is 'O’ the only three scores we will have are +1 for a win by 'X', -1 for a win by 'O', 0 for a draw.

42
Minimax for Tic Tac Toe (ex 1)
")
43
Minimax for Tic Tac Toe (ex 2)
MIN -1 -1 +1 MAX +1 -1 -1 +1 +1

44
Special technique Use alpha-beta pruning
Basic idea: if a portion of the tree is obviously good (bad) don’t explore further to see how terrific (awful) it is Remember that the values are propagated upward. Highest value is selected at MAX’s level, lowest value is selected at MIN’s level Call the values at MAX levels α values, and the values at MIN levels β values
 don’t explore further to see how terrific (awful) it is. Remember that the values are propagated upward. Highest value is selected at MAX’s level, lowest value is selected at MIN’s level. Call the values at MAX levels α values, and the values at MIN levels β values.")
45
The rules Search can be stopped below any MIN node having a beta value less than or equal to the alpha value of any of its MAX ancestors(MIN node β≤α) Search can be stopped below any MAX node having an alpha value greater than or equal to the beta value of any of its MIN node ancestors (MAX node α≥β)
 Search can be stopped below any MAX node having an alpha value greater than or equal to the beta value of any of its MIN node ancestors (MAX node α≥β)")
46
Example with MAX MAX α ≥ 3 MIN β=3 β≤2 MAX 3 4 5 2 (Some of) these
MAX node α>β MAX α ≥ 3 MIN β=3 β≤2 MAX 3 4 5 2 (Some of) these still need to be looked at As soon as the node with value 2 is generated, we know that the beta value will be less than 3, we don’t need to generate these nodes (and the subtree below them)
 these. still need to be. looked at. As soon as the node with. value 2 is generated, we. know that the beta value will be. less than 3, we don’t need. to generate these nodes. (and the subtree below them)")
47
Example with MIN MIN β ≤ 5 MAX α=5 α≥6 MIN 3 4 5 6 (Some of) these
MIN node β<α MAX α=5 α≥6 MIN 3 4 5 6 (Some of) these still need to be looked at As soon as the node with value 6 is generated, we know that the alpha value will be larger than 6, we don’t need to generate these nodes (and the subtree below them)
 these. still need to be. looked at. As soon as the node with. value 6 is generated, we. know that the alpha value will be. larger than 6, we don’t need. to generate these nodes. (and the subtree below them)")
48
A B C MAX <=6 D E MIN 6 >=8 H I J K MAX 6 5 8 = agent = opponent

49
A B C MAX D E F G MIN H I J K L M MAX >=6 6 <=2 6 >=8 2 6 5 8
1 = agent = opponent

50
A B C MAX D E F G MIN H I J K L M MAX >=6 6 2 6 >=8 2 6 5 8 2 1
= agent = opponent

51
Alpha-beta Pruning A B C MAX D E F G MIN H I J K L M MAX 6 6 2
beta cutoff D E F G MIN 6 >=8 alpha cutoff 2 H I J K L M MAX 6 5 8 2 1 = agent = opponent

52
Alpha-beta pruning α≥3 MAX node α>β MIN node β<α β≤3 β≤0 β≤2 α=3
α≥5 α=0 α=2

53
Alpha-beta pruning

Presentasi serupa


>")
>")


>")


>")


>")
 Andika Noviantoro(126) Wahyu Iman. E(101) Qhoirul Wibisono(143) Zulfrizal F(119)>")


>")


