Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
http://www.jonathansarwono.info Video II
Regresi Linier dengan Variabel Laten dalam Konteks SEM oleh: Jonathan Sarwono Video II

2
Pendahuluan Variabel laten ialah variabel yang tidak terobservasi yang menyebabkan variasi dalam data dan / atau hubungan yang nyata antara variabel-variabel yang diobservasi atau variabel manifest / indikator. Pada bagian berikut ini kita akan mendiskusikan lebih lanjut mengenai analisis regresi dalam kaitannya dengan variabel-variabel laten. Pada video I kita sudah belajar mengenai analisis regresi menggunakan variabel-variabel yang diobservasi. Sebagai pengingat untuk pembaca variabel-variabel laten di latihan sebelumnya tercakup dalam variabel error Pada latihan berikut ini kita akan menggunakan data yang dihasilkan dalam riset oleh Rock, dkk. (1977), yang merupakan riset untuk memperbaiki riset yang dilakukan oleh Warren, White, dan Fuller (1974) sebagaimana sudah kita diskusikan di bab sebelumnya. Dalam latihan di bab ini masing-masing pengujian dipisah menjadi dua secara acak dan masing-masing bagian tersebut kemudian dinilai secara terpisah. Di bawah ini adalah semua variabel masukan yang baru
, yang merupakan riset untuk memperbaiki riset yang dilakukan oleh Warren, White, dan Fuller (1974) sebagaimana sudah kita diskusikan di bab sebelumnya. Dalam latihan di bab ini masing-masing pengujian dipisah menjadi dua secara acak dan masing-masing bagian tersebut kemudian dinilai secara terpisah. Di bawah ini adalah semua variabel masukan yang baru.")
3
Variabel Penjelasan Performance1 Sub test dengan menggunakan 12 pertanyaan untuk Role Performance Knowledge1 Sub test dengan menggunakan 13 pertanyaan untuk Knowledge Knowledge2 Value1 Sub test dengan menggunakan 15 pertanyaan untuk Value Orientation Value2 Satisfaction1 Sub test dengan menggunakan 5 pertanyaan untuk Role Satisfaction Satisfaction2 Sub test dengan menggunakan 6 pertanyaan untuk Role Satisfaction Past_training Tingkat pendidikan formal

4
Data yang akan kita gunakan bernama Warren9v
Data yang akan kita gunakan bernama Warren9v.wk1, untuk mendapatkan semua varian dan kovarian sampel. Datanya sebagai berikut:: Untuk mengeluarkan data tersebut agar dapat dianalisis lakukan cara seperti di bawah ini: Pilih File > Data File > File Name Cari Lokasi File di C > Program Files > SPSS Inc > AMOS Files of Types pilih Excell Pilih User Guide > Pilih Warren9v > OK Klik OK File Warren9v sudah aktif di AMOS

5
Model A Pembahasan akan kita mulai dengan membuat model A. Di bawah ini akan kita buat diagram jalur yang menghadirkan suatu model dengan 8 sub- test Keterangan untuk gambar lingkaran elips tambahan yang berisi variabel- variabel knowledge, value, satisfaction, dan performance merupakan variabel- variabel yang tidak terobservasi (variabel laten) yang kemudian diukur secara tidak langsung menggunakan 8 pengujian belah dua (split half test)
 yang kemudian diukur secara tidak langsung menggunakan 8 pengujian belah dua (split half test)")
6
Model Pengukuran Model pengukuran adalah bagian yang menganalisis spesifikasi bagaimana semua variabel yang diobservasi tergantung pada semua variabel yang tidak diobservasi, atau disebut juga sebagai variabel laten. Model di bawah ini mempunyai empat sub model pengukuran yang berbeda Pada gambar di samping, kita membuat sub-model untuk variabel knowledge dengan menjadikan dua sub bagian pengujian lain, yaitu knowledge1 dan knowledge2. Nilai-nilai untuk kedua sub pengujian belah dua ini (knowledge1 dan knowledge2), dihipotesiskan untuk tergantung pada satu variabel yang tidak diobervasi secara langsung yang mendasari knowledge. Menurut model tersebut, nilai-nilai dari dua sub pengujian tersebut masih juga tetap belum sesuai karena masih adanya pengaruh error3 dan error4, yang merupakan perwakilan dari kesalahan pengukuran dalam dua sub-pengujian tersebut. Dalam konteks SEM, knowledge1 dan knowledge2 disebut sebagai indikator dari variabel laten knowledge. Model pengukuran untuk knowledge membentuk suatu pola yang diulangi tiga kali lagi dalam diagram jalur sebelumnya
, dihipotesiskan untuk tergantung pada satu variabel yang tidak diobervasi secara langsung yang mendasari knowledge. Menurut model tersebut, nilai-nilai dari dua sub pengujian tersebut masih juga tetap belum sesuai karena masih adanya pengaruh error3 dan error4, yang merupakan perwakilan dari kesalahan pengukuran dalam dua sub-pengujian tersebut. Dalam konteks SEM, knowledge1 dan knowledge2 disebut sebagai indikator dari variabel laten knowledge. Model pengukuran untuk knowledge membentuk suatu pola yang diulangi tiga kali lagi dalam diagram jalur sebelumnya.")
7
Model Struktural Model struktural adalah bagian yang menunjukkan bagaimana semua variable laten saling berhubungan satu dengan yang lain. Pada diagram jalur di bawah ini ditunjukkan model struktural untuk variabel laten yang ada Identifikasi Untuk melakukan identifikasi, kita memerlukan untuk memperbaiki unit pengukuran dari masing-masing variabel yang tidak diobservasi dengan menggunakan pengendalian yang sesuai pada semua parameter yang ada. Untuk melakukan ini caranya kita mengulangi lagi sebanyak 13 kali dengan tahapan yang sama seperti yang digunakan untuk satu variabel yang tidak diobervasi seperti dalam contoh sebelumnya, yaitu temukan satu anak panah dengan satu arah yang menjauhi dari masing-masing variabel yang tidak diobervasi tersebut di diagram jalur kemudian perbaiki bobot regresi yang bersangkutan dengan nilai berapa saja, misalnya 1. Maka jika ada lebih dari satu anak panah satu arah yang menjauhi variabel tersebut, maka setiap variabel yang lain akan sama juga.

8
Membuat Spesifikasi Model
Untuk membuat spesifikasi model, kita dapat melakukan dengan seperti di bawah ini: Mengubah Orientasi Area Gambar Untuk mengubah orientasi area gambar langkah-langkahnya ialah: Pilih View> Interface Properties. Di kotak dialog Interface Properties, klik Page Layout tab. Di Orientation group, klik Landscape. Klik Apply

9
Membuat Diagram Jalur Untuk memulai membuat diagram jalur, salah satu caranya ialah dengan cara menggambar model pengukuran terlebih dahulu. Di bawah ini kita akan menggambarkan model pengukuran untuk salah satu variabel laten, knowledge, dan kemudian menggunakan sebagai pola untuk ketiga variabel lainnya. Lakukan hal sebagai berikut: Gambar lingkaran elips untuk variabel yang tidak diobservasi knowledge, seperti di bawah ini Caranya ialah pilih perintah Diagram > Draw Indicator Variable. Klik dua kali bagian dalam lingkaran. Setiap klik akan menciptakan satu indikator untuk variabel knowledge Dengan cara seperti itu kita akan dapat melipatgandakan beberapa kali suatu variabel yang tidak diobservasi untuk menciptakan beberapa indikator, yang dilengkapi dengan variabel unik atau error. Amos Graphics akan mempertahankan spasi diantara semua indikator kemudian akan menyisipkan pengendalian secara otomatis

10
Melakukan Rotasi Indikator-Indikator
Dalam kondisi standar (default) maka lingkaran elips untuk knowledge akan seperti itu; sekalipun demikian kita dapat mengubah lokasinya dengan cara melakukan rotasi sebagai berikut: Pilih Edit > Rotate. Klik lingkaran elips knowledge. Setiap kali kita melakukan klik lingkaran elips knowledge, maka secara otomtasi indikator-indikator akan berotasi 90° searah jarum jam. Jika kita lakukan sebanyak tiga kali, maka hasilnya akan seperti di bawah ini: Membuat Duplikasi Model-Model Pengukuran Setelah kita membuat satu model pengukuran tersebut di atas, maka sekarang kita lanjutkan untuk membuat model-model pengukuran untuk variabel-variabel value dan satisfaction. Caranya ialah: Pilih Edit > Select All. Pilih Edit > Duplicate. Klik bagian mana saja dari model pengukuran tersebut, kemudian tarik kopiannya ke bagian bawah bentuk aslinya. Ulangi untuk membuat model pengukuran ketiga.
 maka lingkaran elips untuk knowledge akan seperti itu; sekalipun demikian kita dapat mengubah lokasinya dengan cara melakukan rotasi sebagai berikut: Pilih Edit > Rotate. Klik lingkaran elips knowledge. Setiap kali kita melakukan klik lingkaran elips knowledge, maka secara otomtasi indikator-indikator akan berotasi 90° searah jarum jam. Jika kita lakukan sebanyak tiga kali, maka hasilnya akan seperti di bawah ini: Membuat Duplikasi Model-Model Pengukuran. Setelah kita membuat satu model pengukuran tersebut di atas, maka sekarang kita lanjutkan untuk membuat model-model pengukuran untuk variabel-variabel value dan satisfaction. Caranya ialah: Pilih Edit > Select All. Pilih Edit > Duplicate. Klik bagian mana saja dari model pengukuran tersebut, kemudian tarik kopiannya ke bagian bawah bentuk aslinya. Ulangi untuk membuat model pengukuran ketiga.")
11
Jika semua proses benar, maka diagram jalur akan nampak seperti di bawah ini:
Tahap berikutnya ialah membuat kopian keempat untuk performance, dan letakkan di sebelah kanan aslinya seperti di bawah ini. Caranya ialah Pilih Edit > Reflect. Reposisi untuk dua indikator performance menjadi sebagai berikut:

12
Memberi Nama Variabel Untuk memberi nama variable, Lakukan klik kanan untuk masing-masing obyek kemudian pilih Object Properties dari pop-up menu Di kotak dialog Object Properties, klik Text tab, kemudian masukkan nama ke dalam kotak teks Variable Name. Cara lainnya ialah pilih View >Variables in Dataset kemudian tarik nama-nama variabel ke dalam semua obyek di diagram jaluir tersebut Melengkapi Model Struktural Untuk melengkapi model struktural kita memerlukan langkah-langkah sebagai berikut: Gambar tiga jalur kovarian yang menghubungkan knowledge, value, dan satisfaction. Gambar anak panah satu arah dari masing-masing predictor laten, knowledge, value, dan satisfaction, ke variabel dependen laten, performance. Tambahkan variabel error9 yang tidak terobservasi sebagai suatu predictor untuk performance. Caranya ialah pilih Diagram > Draw Unique Variable. File masukan grafis Amos yang berisi diagram jalur ini bernama Ex05-a.amw.

13
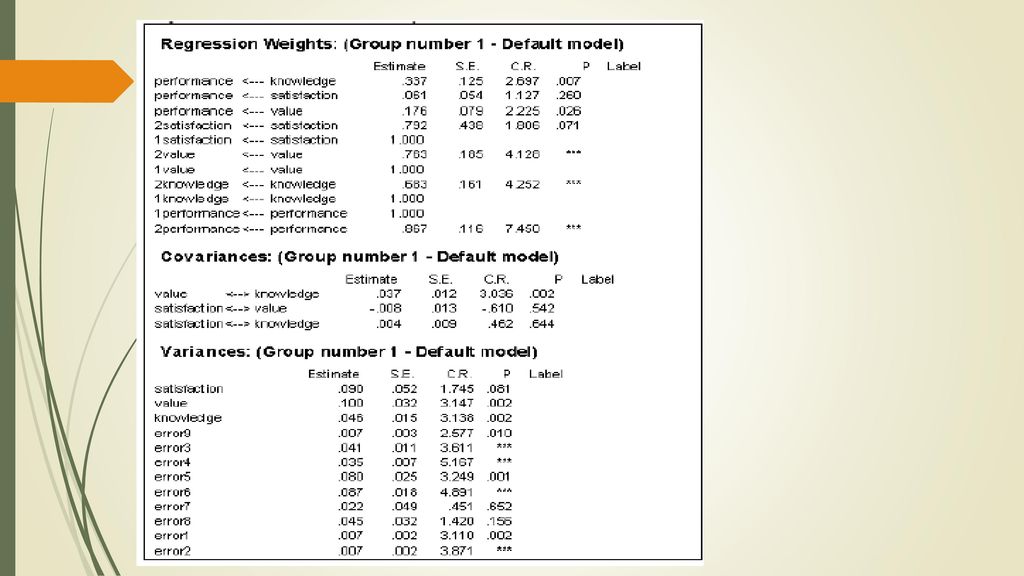
Hasil untuk Model A Untuk melihat hasil analisi langkah-langkahnya sebagai berikut: Setelah selesai lakukan analisis sebagai berikut: Analyse > Calculate Estimates Dapat juga dilakukan dengan cara meng –klik gambar kotak dengan warna hijau dan arah anak panah ke bawah. Untuk melihat hasil analisis dalam bentuk diagram beserta nilai – nilanya klik gambar kotak dengan warna hijau dan arah anak panah ke atas. Untuk melihat keluaran dalam bentuk teks, caranya View > Text Output Setelah keluaran kotak dialog AMOS Output, kemudian Pilih Estimates Untuk melihat semua masukan dalam satu kotak dialog. Untuk melihat keluaran berikut ini Pilih Notes For Models Hasil untuk model A seperti di samping ini. Keluaran berikut ini akan digunakan untuk konfirmasi penghitungan derajat kebebasan (DK) (degree of freedom / DF):
 (degree of freedom / DF):")
14
Jika signifikansi / probabilitas < 0,05 H0 ditolak
Jika signifikansi / probabilitas > 0,05 H0 diterima Karena nilai signifikansi / probabilitas keluaran di atas sebesar 0,737 (probability level) > 0,05 H0 diterima; maka H0 diterima artinya model sesuai dengan teori (model sudah benar). Selanjutnya kita dapat mengatakan bahwa estimasi-estimasi parameter dipengaruhi oleh pengendalian-pengendalian identifikasi. Untuk melihat keluaran di bawah ini caranya: Untuk melihat keluaran dalam bentuk teks, caranya View > Text Output Pilih Estimates
 > 0,05 H0 diterima; maka H0 diterima artinya model sesuai dengan teori (model sudah benar). Selanjutnya kita dapat mengatakan bahwa estimasi-estimasi parameter dipengaruhi oleh pengendalian-pengendalian identifikasi. Untuk melihat keluaran di bawah ini caranya: Untuk melihat keluaran dalam bentuk teks, caranya. View > Text Output. Pilih Estimates.")
16
Penafsiran keluaran di atas sama sebagai berikut:
Untuk Bobot Regresi (Regression Weights) mempunyai maksud sebagai berikut: Jalur dari variabel knowledge ke performance sebesar 0,337 dengan nilai probabilitas sebesar 0,007. Penafsirannya variabel knowledge mempengaruhi performance sebesar 0,337 dengan probabilitas sebesar 0,007 < 0,05 dengan demikian pengaruh tersebut bersifat signifikan. Jalur dari variabel satisfaction ke performance sebesar 0,061 dengan nilai probabilitas sebesar 0,260. Penafsirannya variabel satisfaction mempengaruhi performance sebesar 0,061 dengan probabilitas sebesar 0,260 > 0,05 dengan demikian pengaruh tersebut bersifat tidak signifikan Jalur dari variabel value ke performance sebesar 0,176 dengan nilai probabilitas sebesar 0,026. Penafsirannya variabel value mempengaruhi performance sebesar 0,176 dengan probabilitas sebesar 0,026 < 0,05 dengan demikian pengaruh tersebut bersifat signifikan Jalur dari variabel satisfaction ke satisfaction2 sebesar 0,792 dengan nilai probabilitas sebesar 0,071. Penafsirannya variabel satisfaction mempengaruhi satisfaction2 sebesar 0,792 dengan probabilitas sebesar 0,071 > 0,05 dengan demikian pengaruh tersebut bersifat tidak signifikan Jalur dari variabel satisfaction ke satisfaction1 sebesar 1. Maksudnya variabel satisfaction berpengaruh terhadap satisfaction1 sebesar 1 Jalur dari variabel value ke value2 sebesar 0,763. Maksudnya variabel value berpengaruh terhadap value2 sebesar 0,763 Jalur dari variabel value ke value1 sebesar 1. Maksudnya variabel value berpengaruh terhadap value1 sebesar 1 Jalur dari variabel knowledge ke value2 sebesar 0,683. Maksudnya variabel knowledge berpengaruh terhadap knowledge2 sebesar 0,683 Jalur dari variabel knowledge ke value1 sebesar 1. Maksudnya variabel knowledge berpengaruh terhadap knowledge1 sebesar Jalur dari variabel performance ke performance1 sebesar 1. Maksudnya variabel performance berpengaruh terhadap performance1 sebesar 1 Jalur dari variabel performance ke performance2 sebesar 0,867. Maksudnya variabel performance berpengaruh terhadap performance2 sebesar 0,867
 mempunyai maksud sebagai berikut: Jalur dari variabel knowledge ke performance sebesar 0,337 dengan nilai probabilitas sebesar 0,007. Penafsirannya variabel knowledge mempengaruhi performance sebesar 0,337 dengan probabilitas sebesar 0,007 < 0,05 dengan demikian pengaruh tersebut bersifat signifikan. Jalur dari variabel satisfaction ke performance sebesar 0,061 dengan nilai probabilitas sebesar 0,260. Penafsirannya variabel satisfaction mempengaruhi performance sebesar 0,061 dengan probabilitas sebesar 0,260 > 0,05 dengan demikian pengaruh tersebut bersifat tidak signifikan. Jalur dari variabel value ke performance sebesar 0,176 dengan nilai probabilitas sebesar 0,026. Penafsirannya variabel value mempengaruhi performance sebesar 0,176 dengan probabilitas sebesar 0,026 < 0,05 dengan demikian pengaruh tersebut bersifat signifikan. Jalur dari variabel satisfaction ke satisfaction2 sebesar 0,792 dengan nilai probabilitas sebesar 0,071. Penafsirannya variabel satisfaction mempengaruhi satisfaction2 sebesar 0,792 dengan probabilitas sebesar 0,071 > 0,05 dengan demikian pengaruh tersebut bersifat tidak signifikan. Jalur dari variabel satisfaction ke satisfaction1 sebesar 1. Maksudnya variabel satisfaction berpengaruh terhadap satisfaction1 sebesar 1. Jalur dari variabel value ke value2 sebesar 0,763. Maksudnya variabel value berpengaruh terhadap value2 sebesar 0,763. Jalur dari variabel value ke value1 sebesar 1. Maksudnya variabel value berpengaruh terhadap value1 sebesar 1. Jalur dari variabel knowledge ke value2 sebesar 0,683. Maksudnya variabel knowledge berpengaruh terhadap knowledge2 sebesar 0,683. Jalur dari variabel knowledge ke value1 sebesar 1. Maksudnya variabel knowledge berpengaruh terhadap knowledge1 sebesar. Jalur dari variabel performance ke performance1 sebesar 1. Maksudnya variabel performance berpengaruh terhadap performance1 sebesar 1. Jalur dari variabel performance ke performance2 sebesar 0,867. Maksudnya variabel performance berpengaruh terhadap performance2 sebesar 0,867.")
17
Bagian Kovarian • Jalur antara variabel knowledge dan performance sebesar 0,037 dengan probabilitas sebesar 0,002. Artinya korelasi antara variabel knowledge dan performance sebesar 0,037 dan signifikan karena nilai probabilitas sebesar 0,002 < 0,05. • Jalur antara variabel satisfaction dan value sebesar -0,008 dengan probabilitas sebesar 0,542. Artinya korelasi antara variabel satisfaction dan value sebesar -0,008 dan tidak signifikan karena nilai probabilitas sebesar 0,542 > 0,05. • Jalur antara variabel satisfaction dan knowledge sebesar 0,004 dengan probabilitas sebesar 0,644. Artinya korelasi antara variabel satisfaction dan knowledge sebesar 0,004 dan tidak signifikan karena nilai probabilitas sebesar 0,644 > 0,05. Dari keluaran di atas kita ketahui bahwa estimasi-estimasi baku (standardized estimates), sebaliknya, tidak dipengaruhi oleh pengendalian-pengendalian identifikasi. Untuk menghitung estimasi baku dilakukan tahapan sebagai berikut: • Pilih View > Analysis Properties. • Di kotak dialog Analysis Properties > klik Output tab. • Aktifkan kotak cek (v) pada pilihan Standardized Estimates. Kemudian untuk melihat hasilnya • View > Text Output. • Pilih Estimates
, sebaliknya, tidak dipengaruhi oleh pengendalian-pengendalian identifikasi. Untuk menghitung estimasi baku dilakukan tahapan sebagai berikut: • Pilih View > Analysis Properties. • Di kotak dialog Analysis Properties > klik Output tab. • Aktifkan kotak cek (v) pada pilihan Standardized Estimates. Kemudian untuk melihat hasilnya. • View > Text Output. • Pilih Estimates.")
18
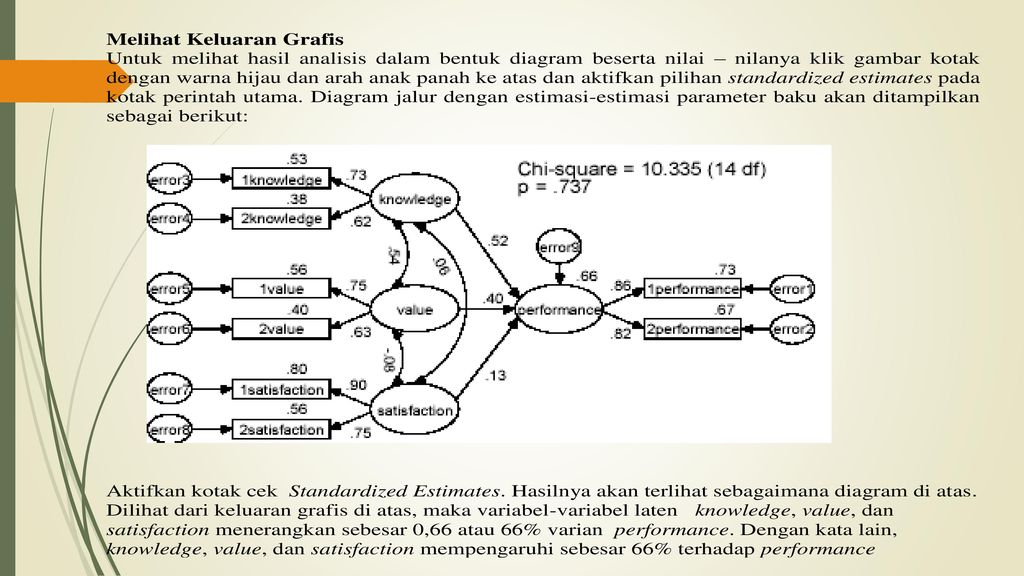
Keluaran di atas mempunyai maksud sebagai berikut:
Bobot Regresi: Jalur knowledge ke performance nilai estimasi sebesar 0,516. Artinya pengaruh variabel knowledge ke performance adalah sebesar 0,516 Jalur satisfaction ke performance nilai estimasi sebesar 0,130. Artinya pengaruh variabel satisfaction ke performance adalah sebesar 0,130 Jalur value ke performance nilai estimasi sebesar 0,398. Artinya pengaruh variabel value ke performance adalah sebesar 0,130 Jalur satisfaction ke satisfaction2 nilai estimasi sebesar 0,747. Artinya pengaruh variabel satisfaction ke satisfcation2 adalah sebesar 0,747 Jalur satisfaction ke satisfaction1 nilai estimasi sebesar 0,896. Artinya pengaruh variabel satisfaction ke satisfcation1 adalah sebesar 0,896 Jalur value ke value2 nilai estimasi sebesar 0,633. Artinya pengaruh variabel value ke value2 adalah sebesar 0,633 Jalur value ke value1 nilai estimasi sebesar 0,745. Artinya pengaruh variabel value ke value1 adalah sebesar 0,745 Jalur knowledge ke knowledge2 nilai estimasi sebesar 0,618. Artinya pengaruh variabel knowledge ke knowledge2 adalah sebesar 0,618 Jalur knowledge ke knowledge1 nilai estimasi sebesar 0,728. Artinya pengaruh variabel knowledge ke knowledge1 adalah sebesar 0,728 Jalur performance ke performance1 nilai estimasi sebesar 0,856. Artinya pengaruh variabel performance ke performance1 adalah sebesar 0,856 Jalur performance ke performance2 nilai estimasi sebesar 0,819. Artinya pengaruh variabel performance ke performance2 adalah sebesar 0,819 Korelasi Korelasi antara value dan knowledge sebesar 0,542 Korelasi antara satisfaction dan value sebesar -0,084 Korelasi antara satisfaction dan knowledge sebesar 0,064

20
Model B Kita berasumsi bahwa Model A sudah benar dengan mempertimbangkan hipotesis tambahan untuk yang menyebutkan bahwa indikator knowledge1 dan knowledge2 merupakan pengujian paralel. Didasarkan pada hipotesis yang diuji secara pararel, maka regresi indikator knowledge1 terhadap variabel laten knowledge harus sama dengan regresi indikator knowledge2 pada variabel knowledge. Juga semua variabel error yang berhubungan dengan indikator knowledge1 dan knowledge2 harus mempunyai varian yang sama. Dengan demikian untuk indikator-indikator value1 dan value2 merupakan pengujian paralel. Namun demikian kita tidak dapat mengatakan dsama dengan indikator-indikator satisfaction1 dan satisfaction2. Didasarkan pengujian tersebut hasilnya indikator satisfaction2 20% lebih panjang dari satisfaction1. Dengan demikian dapat diasumsikan bahwa bobot regresi untuk indikator satisfaction2 pada variabel satisfaction harus sebesar 1,2 kali bobot regresi indikator satisfaction1 pada variabel satisfaction. Dengan diberi varian yang sama, maka bobot regresi untuk error8 Mempunyai bobot regresi yang sama dengan error7. Untuk memodifikasi model A menjadi model B yang kita perlukan ialah dengan mengubah dua bobot regresinya dari 1 menjadi 1,2.

23
Di bawah ini kita tampilkan diagram jalur untuk nilai estimasi-estimasi baku dan R2

24
Kesimpulan Pengujian Model B Dibandingkan dengan Model A
Pada bagain ini kita mencoba membandingkan kedua model yang sudah kita buat sebelumnya. Perbandingan ini ditujukan untuk melihat kecocokan model dengan data yang lebih baik. Apakah model A lebih baik dari B? Dari angka-angka yang kita peroleh ternyata model B lebih baik atau lebih cocok dengan data dibandingkan dengan model A. Salah satu bukti ialah nilai chi square model A sebesar 10,335 < dari nilai chi square model B yaitu sebesar 26,967. Sebagimana kita ketahui bahwa nilai ini digunakan sebagai patokan kecocokan model dengan data. Semakin besar nilai chi square, maka semakin sesuai model dengan data yang kita buat. Sekalipun demikian kita dapat memilih hanya melakukan analisis satu model saja apakah itu model A ataupun model B.

25
Daftar Pustaka Anderson, Sweeny and William.(2011). Statistics for Business and Economics. South Western: Cengage Learning. Arbuckle, J. (1997), Amos Users’ Guide Version 3.6, Chicago IL: Smallwaters Corporation. Arbuckle James L. Amos™ 16.0 User’s Guide Byrne, Barbara. M.(2001). Structural Equation Modeling With AMOS, Basic Concepts, Applications, and Programming. New Jersey: Lawrence Erlbaum Associates Publishers. Cramer, Duncan and Howitt, Dennis. (2006) The Sage Dictionary of Statistics. London: Sage Publication Gujarati, Damodar. N. (2003). Basic Econometrics. New York: MacGraw Hill Gujarati, Damodar. N. (2006). Essentials of Econometrics. New York: MacGraw Hill Hair, Joseph F. et al. (2010). Multivariate Data Analysis: A Global Perspective. New Jersey: Pearson Prentice Hall Johnson, Richard A. and Wichern, Dean W.(2002). Applied Multivariate Statistical Analysis. New Jersey: Prentice Hall
, Amos Users’ Guide Version 3.6, Chicago IL: Smallwaters Corporation. Arbuckle James L. Amos™ 16.0 User’s Guide. Byrne, Barbara. M.(2001). Structural Equation Modeling With AMOS, Basic Concepts, Applications, and Programming. New Jersey: Lawrence Erlbaum Associates Publishers. Cramer, Duncan and Howitt, Dennis. (2006) The Sage Dictionary of Statistics. London: Sage Publication. Gujarati, Damodar. N. (2003). Basic Econometrics. New York: MacGraw Hill. Gujarati, Damodar. N. (2006). Essentials of Econometrics. New York: MacGraw Hill. Hair, Joseph F. et al. (2010). Multivariate Data Analysis: A Global Perspective. New Jersey: Pearson Prentice Hall. Johnson, Richard A. and Wichern, Dean W.(2002). Applied Multivariate Statistical Analysis. New Jersey: Prentice Hall.")
Presentasi serupa


>")

>")

>")


 UNTUK MENGATASI ASUMSI NON- NORMAL MULTIVARIAT.>")









>")

