Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Konsep dasar dan metoda penggunaannya dalam penelitian
Statistika Konsep dasar dan metoda penggunaannya dalam penelitian

2
Tujuan : Untuk memajukan pemikiran yang tertib, runut dan jelas, terutama yang berhubungan dengan pengumpulan dan interpretasi data numerik, serta menyediakan sejumlah teknik statistika yang mempunyai kegunaan yang luas dalam penelitian. Melakukan penyajian, peringkasan dan pencirian data Statistika adalah cara berpikir perihal ketidakpastian.

3
Penelitian : Penyelidikan terencana untuk mendapatkan fakta baru, untuk memperkuat atau menolak hasil hasil percobaan terdahulu. Penyelidikan demikian ini akan membantu pengambilan keputusan

4
Pertanyaan yang harus dijawab :
Untuk setiap perhitungan statistik, selalu muncul pertanyaan mengenai ketelitiannya, berapa angka yang masih dapat dipercaya sebagai akhir dari serangkaian perhitungan yang kita lakukan

6
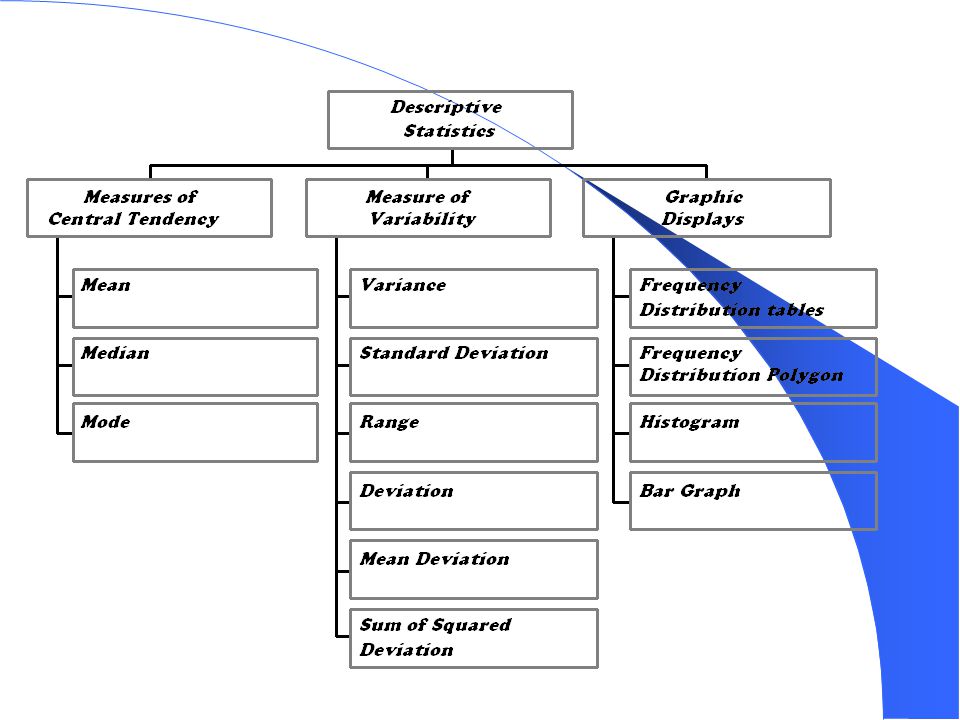
Aplikasi Statistik dibagi menjadi dua bagian :
Statistik Deskriptif Menjelaskan / menggambarkan berbagai karakteristik data seperti mean, std dev, variansi dan sebagainya Statistik Induktif (Inferensi) Membuat berbagai inferensi terhadap sekumpulan data yang berasal dari suatu sampel. Tindakan inferensi tersebut seperti melakukan perkiraan, peramalan, pengambilan keputusan dan sebagainya.
 Membuat berbagai inferensi terhadap sekumpulan data yang berasal dari suatu sampel. Tindakan inferensi tersebut seperti melakukan perkiraan, peramalan, pengambilan keputusan dan sebagainya.")
7
Dalam prakteknya kedua bagian statistik tersebut digunakan bersama-sama, umumnya dimulai dengan statistik deskriptif lalu dilanjutkan dengan berbagai analisis statistik untuk inferensi.

10
Elemen Statistik. 1. Populasi Sekumpulan data yang mengidentifikasikan suatu fenomena yang tergantung dari kegunaan dan relevansi data yang dikumpulkan. 2. Sampel Sekumpulan data yang diambil / diseleksi dari suatu populasi. (sampel adalah bagian dari populasi).
.")
11
4. Pengukuran Reabilitas dari Statistik Inferensi.
Suatu keputusan, perkiraan atau generalisasi tentang suatu populasi berdasarkan informasi yang terkandung dari suatu sampel 4. Pengukuran Reabilitas dari Statistik Inferensi. Tujuan dari statistik pada dasarnya adalah melakukan deskripsi terhadap data sampel, kemudian melakukan inferensi terhadap populasi data berdasar pada informasi (hasil statistik deskriptif) yang terkandung dalam sampel. Catatan : Karena sampel yang diambil hanya sebagian dari populasi, dapat terjadi bias dalam kesimpulannya. Sebagai konsekuensi dari kemungkinan timbulnya berbagai bias dalam inferensi, perlu diukur reabilitas dari setiap inferensi yang telah dibuat.
 yang terkandung dalam sampel. Catatan : Karena sampel yang diambil hanya sebagian dari populasi, dapat terjadi bias dalam kesimpulannya. Sebagai konsekuensi dari kemungkinan timbulnya berbagai bias dalam inferensi, perlu diukur reabilitas dari setiap inferensi yang telah dibuat.")
12
Tipe Data Statistik. Data Kualitatif a. Nominal Mis gender, tgl lahir dsb yang untuk mudahnya dapat dikategorikan dengan angka. (level sama) b. Ordinal Misal selera, dsb (level tidak sama)
 b. Ordinal. Misal selera, dsb (level tidak sama)")
13
Tipe Data Statistik. Data Kuantitatif a. Data Interval Data yang memiliki jangkauan Mis pengukuran suhu, Cukup panas antara – 80 derajat C, Panas antara 80 – 110 C, dan Sangat panas antara 110 – 140 C b. Data Rasio. Data dengan tingkat pengukuran ter “tinggi” diantara jenis lainnya. Sehingga dapat dilakukan operasi matematika. Mis jumlah barang, berat badan dsb.

14
Statistik Deskriptif Bagian ini lebih berhubungan dengan pengumpulan dan peringkasan data, serta penyajian hasil peringkasan tersebut. Penyajian tabel dan grafik misalnya 1. Distribusi Frekuensi 2. Histogram, Pie chart dsb Dua ukuran penting yang sering digunakan dalam pengambilan keputusan adalah : 1. Mencari Central Tendency (mean, median, modus) 2. Mencari Ukuran Dispersi (std deviasi, variansi) Ukuran lain yang sering digunakan adalah Skewness dan Kurtosis untuk mengetahui kemiringan data.
 2. Mencari Ukuran Dispersi (std deviasi, variansi) Ukuran lain yang sering digunakan adalah Skewness dan Kurtosis untuk mengetahui kemiringan data.")
15
Statistical Notation Variabel biasanya ditulis sbg “x” dan “y”
Untuk populasi dinotasikan dg huruf besar “N” (“N” for populations and “n” for samples) Sigma ( ) mewakili operasi penjumlahan
 Sigma ( ) mewakili operasi penjumlahan.")
16
Statistical Notation X y xy x+1 x2 2 3 6 3 4 3 5 15 4 9 6 8 48 7 36

17
Statistical Notation S x = 2 + 3 + 6 + 4 = 15 S y = 3 + 5 + 8 + 2 = 18
Sx indicates that scores on variable “x” are to be added; Sy indicates that scores on variable “y” are to be added In the previous table, S x = = 15 S y = = 18 S x S y = 15*18 = 270

18
Statistical Notation S xy indicates that the 2 variables (x and y) are to be multiplied together, then summed. S xy = (2*3) + (3*5) + (6*8) + (4*2) = 77 ( = 77) Note that S xy (does not equal) S x S y (77 vs. 270)
 + (3*5) + (6*8) + (4*2) = 77. ( = 77) Note that S xy (does not equal) S x S y (77 vs. 270)")
19
S(x+1) = (2+1) + (3+1) + (6+1) + (4+1) = 19
Statistical Notation S(x+1) indicates that a constant value of 1 is added to each score, then each score is added up Remember that operations in parenthesis are always done first S(x+1) = (2+1) + (3+1) + (6+1) + (4+1) = 19 = ( = 19) Notice that S(x+1) S x+1 (19 vs. 16)
 indicates that a constant value of 1 is added to each score, then each score is added up. Remember that operations in parenthesis are always done first. S(x+1) = (2+1) + (3+1) + (6+1) + (4+1) = 19. = ( = 19) Notice that S(x+1) S x+1 (19 vs. 16)")
20
X2 indicates to square each of the x values, then add them up
Statistical Notation X2 indicates to square each of the x values, then add them up X2 = 2² + 3² + 6² + 4² = 65 (= =65) Notice that x2 (x) 2 (65 vs. 225)
 Notice that x2 (x) 2 (65 vs. 225)")
21
Dalam statistika hal yang paling penting adalah
PENGAMATAN

25
Perhatikan data berikut :
8, 8, 9, 10, 11, 12, 12 5, 6, 8, 10, 12, 14, 15 1, 2, 5, 10, 15, 18, 19 Dan 8, 9, 10, 10, 10, 11, 12 5, 7, 9, 10, 11, 13, 15 1, 5, 8, 10, 12, 15, 19

26
Perhatikan data berikut :
8, 8, 9, 10, 11, 12, 12 s: 1.6 5, 6, 8, 10, 12, 14, 15 s: 3.58 1, 2, 5, 10, 15, 18, 19 s: 6.96 Dan 8, 9, 10, 10, 10, 11, 12 s: 1.19 5, 7, 9, 10, 11, 13, 15 s: 3.16 1, 5, 8, 10, 12, 15, 19 s: 5.60

27
Central Tendency CENTRAL TENDENCY:
A statistical measure that identifies a single score that is most typical or representative of the entire group; a single score or measurement used to describe an entire distribution Usually, a value that reflects the middle of the distribution is used, because this is where most of the scores pile up No single measure of central tendency works best in all circumstances, so there are 3 different measures -- mean, median, and mode. Each works best in a specific situation

28
Central Tendency (Mode)
The score or category that has the greatest frequency; the most common score To find the mode, simply locate the score that appears most often In a frequency distribution table, it will be the score with the largest frequency value In a frequency graph, it will be the tallest bar or point

29
Central Tendency (Mode)
Example: A sample of class ages is given. . . Ages f * The age with the highest frequency is 19, with a frequency of 3; therefore, the mode is 19. 20 0 19 3 18 2

30
Central Tendency (Mode)
A distribution may have more than one mode, or peak: A distribution with 2 modes is said to be bimodal; A distribution with more than 2 modes is said to be multimodal Example: A sample of class ages. . . Age f * age 22 and age 19 both have a frequency of 3; if this distribution were graphed, there would be peaks; therefore this distribution is bimodal -- both 22 and 19 are modes

31
Central Tendency (Mode)
Advantages: Easiest to determine The only measure of central tendency that can be used with nominal (categorical) data Disadvantages Sometimes is not a unique point in the distribution (bimodal or multimodal) Not sensitive to the location of scores in a distribution Not often used beyond the descriptive level
 data. Disadvantages. Sometimes is not a unique point in the distribution (bimodal or multimodal) Not sensitive to the location of scores in a distribution. Not often used beyond the descriptive level.")
32
Central Tendency (Median)
The score that divides the distribution exactly in half; 50% of the individuals in a distribution have scores at or below the median

33
Central Tendency (Median)
Method 1: (Use when N (or n) is an odd number) List the scores from lowest to highest; the middle score on the list is the median Example: The ages of a sample of class members are 24, 18, 19, 22, and 20. What is the median value? List the scores from lowest to highest: 18, 19, 20, 22, 24 The middle score is 20 - therefore, that is the median
 is an odd number) List the scores from lowest to highest; the middle score on the list is the median. Example: The ages of a sample of class members are 24, 18, 19, 22, and 20. What is the median value List the scores from lowest to highest: 18, 19, 20, 22, 24. The middle score is 20 - therefore, that is the median.")
34
Central Tendency (Median)
Method 2: (Use when N (or n) is an even number) List scores in order from lowest to highest and locate the point halfway between the middle two scores Example: The ages of a sample of class members are 18, 19, 20, 22, 24 and 30. What is the median age? The scores are already listed from lowest to highest; select the middle two scores (20, 22) and find the middle point:
 is an even number) List scores in order from lowest to highest and locate the point halfway between the middle two scores. Example: The ages of a sample of class members are 18, 19, 20, 22, 24 and 30. What is the median age The scores are already listed from lowest to highest; select the middle two scores (20, 22) and find the middle point:")
35
Central Tendency (Mean)
MEAN (µ, x): The mathematical average of the scores The amount that each individual would receive if the total (x) were divided up equally between everyone in the distribution Computed by adding all of the scores in the distribution and dividing that sum by the total number of scores Population mean: Sample mean:
: The mathematical average of the scores. The amount that each individual would receive if the total (x) were divided up equally between everyone in the distribution. Computed by adding all of the scores in the distribution and dividing that sum by the total number of scores. Population mean: Sample mean:")
36
Central Tendency (Mean)
Note that, while the computations would yield the same answer, the symbols differ for a population (, N) and a sample (x,n) Example:
 and a sample (x,n) Example:")
37
Central Tendency (Mean)
If a constant is added or subtracted from each score used to compute the mean, the mean will change by the value of that constant Example: The class scores on a 15-point quiz are 8, 4, 12, 14, 4, and 6. The mean of these scores is. . .

38
Central Tendency (Mean)
Suppose the instructor made an error on the quiz and decided to add 1 point to everyone’s score. How would that change the mean? X+1 * The new scores are 9, 5, 13, 15, 5, &7 8+1= 9 * The new mean is: 4+1= 5 12+1=13 14+1=15 * so, adding a constant to each score 4+1= (x+a) and calculating mean has the 6+1= same result as adding that constant to X = the mean (x+ a)
 and calculating mean has the. 6+1= 7 same result as adding that constant to. X = 54 the mean (x+ a)")
39
Central Tendency (Mean)
If all of the scores are multiplied or divided by a constant value, and the mean is then computed, the result will be the same as if the mean were multiplied or divided by that constant Example: A 10-point quiz is given to a class. Their scores are 6, 5, 7, 8, 10 and 6. The mean is computed. . . X=42

40
Central Tendency (Mean)
The instructor then decides to change the value of the quiz from 10 points to 20 points. What is the new mean for the class? X(2) * The new scores are 12, 10, 14, 6(2)= , 20, 12 5(2)=10 * The new mean is: 7(2)=14 8(2)=16 * thus, multiplying each score by 10(2)= a constant is the same as 6(2)= multiplying the mean by the X= constant
 * The new scores are 12, 10, 14, 6(2)=12 16, 20, 12. 5(2)=10 * The new mean is: 7(2)=14. 8(2)=16 * thus, multiplying each score by. 10(2)=20 a constant is the same as. 6(2)=12 multiplying the mean by the. X=84 constant.")
41
Central Tendency (Mean)
Sensitive to extreme scores, and therefore may not be desirable when working with highly skewed distributions Example: compare 2 samples of class ages 1) 18, 19, 20, 22, 24 2) 18, 19, 20, 22, 47 Vs.
 18, 19, 20, 22, 24. 2) 18, 19, 20, 22, 47. Vs.")
42
Mean – Mode = 3(Mean – Median)
")
43
Persentase luas daerah antara Mean dan Std Dev
X 1 2 3 | x +/- 1s | = 68.27% | x +/- 2s | = 95.45% | x +/- 3s | = 99.73%

44
Measures of Variability
range- (highest score - lowest score) +1 deviation- score - mean mean deviation- the average absolute deviation score
 +1. deviation- score - mean. mean deviation- the average absolute deviation score.")
45
Measures of Variability
sum of squares- the sum of the squared deviation scores definitional

46
Measures of Variability
variance- the average sum of the squared deviation scores sample- population-

47
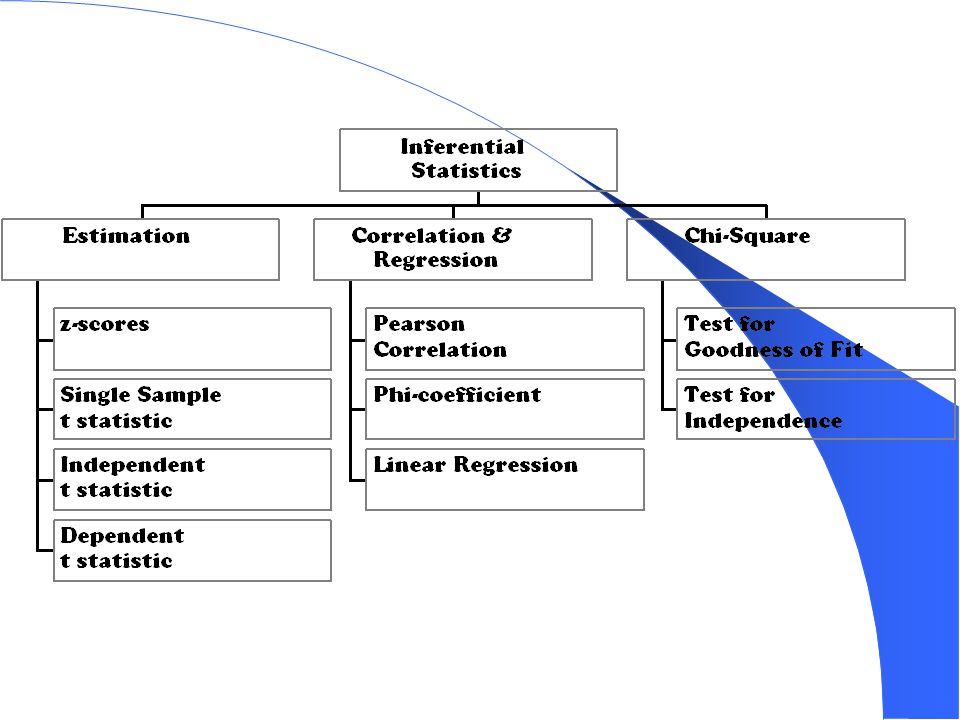
Statistik Inferensi Setelah dilakukan uji terhadap suatu distribusi data, dan terbukti bahwa data yang diuji berdistribusi normal atau mendekati normal, maka pada data tersebut dapat dilakukan berbagai Inferensi dengan metode statistik parametrik. Tetapi jika dalam pengujian terbukti distribusi data tidak berdistribusi normal atau jauh dari normal maka Inferensi yang dilakukan harus dengan metode statistik non parametrik.

48
Uji Hipotesa Dalam melakukan uji hipotesis, ada banyak faktor yang menentukan seperti apakah sampel yang diambil berjumlah banyak atau hanya sedikit, apakah std deviasi populasi diketahui, apakah variansi dari populasi diketahui, apa metode parametrik yang digunakan, dst. 1. Prosedur Uji Hipotesis a. Menentukan H0 dan H1 b. Menentukan nilai statistiknya 1. Tingkat kepercayaan 2. Derajat kebebasan 3. Jumlah sampel yang didapat

49
c. Menentukan Statistik hitung, nilai ini
tergantung pada metode parametrik yang digunakan. b. d. Mengambil keputusan, hal ini ditentukan dengan membandingkan nilai statistik hitung dengan nilai statistik tabel atau nilai kritisnya.

50
Kesalahan : Jika kita menolak hipotesa, sedangkan hipotesa benar dikatakan kita melakukan kesalahan type I Sebaliknya jika kita menerima hipotesa sedangkan hipotesa salah, dikatakan kita melakukan kesalahan type II

51
Derajat kepercayaan. (level of significant)
Dalam melakukan test terhadap hipotesa, maksimum probabitity yang akan kita gunakan untuk mendapatkan resiko Type I disebut derajat kepercayaan Harga yang umum di gunakan adalah 0.05 dan 0.01

52
2. Berbagai Metode Parametrik
a. Inferensi terhadap sebuah rata-rata populasi · sampel besar, gunakan rumus z · sampel kecil (<30), gunakan student t test b. Inferensi terhadap dua rata-rata populasi · Sampel besar, gunakan z test yang dimodifikasi · Sampel kecil, gunakan t test yang dimodifikasi atau F test
, gunakan student t test. b. Inferensi terhadap dua rata-rata populasi. · Sampel besar, gunakan z test yang. dimodifikasi. · Sampel kecil, gunakan t test yang. dimodifikasi atau F test.")
53
c. Inferensi untuk mengetahui hubungan antar variabel > Hubungan antar Dua Variabel, meng gunakan metode korelasi dan Regresi sederhana > Hubungan antar lebih dari dua variabel, menggunakan metode korelasi dan regresi berganda

54
Regresi Sederhana dan Korelasi
Jika akan dibahas mengenai dua variabel numerik atau lebih, termasuk hubungan di antara keduanya, maka digunakan dua teknik perhitungan, yaitu Regresi dan Korelasi. Dalam analisa Regresi, akan dikembangkan sebuah persamaan regresi yaitu formula matematika yang mencari nilai variabel tergantung (dependent) dari nilai variabel bebas (independent) yang diketahui. Analisa regresi terutama digunakan untuk tujuan peramalan.
 dari nilai variabel bebas (independent) yang diketahui. Analisa regresi terutama digunakan untuk tujuan peramalan.")
55
Model Matematika yang digunakan :
Garis Lurus Parabola / Kurva Kuadratik Kurva kubik Kurva Quartic Kurva pangkat n Biasanya disebut sebagai polinomial berderajat satu, dua, ….dst

56
Metoda Garis Lurus y= a + bx

57
Metoda Kuadrat Terkecil (Least Square)
Untuk mendapatkan parameter y = a + bx + e

58
Statistik Non-Parametrik
Jika data yang ada tidak berdistribusi Normal, atau jumlah data sangat sedikit serta level data adalah nominal atau ordinal, maka perlu digunakan metode statistik alternatif yang tidak harus menggunakan suatu parameter tertentu misalnya Mean, STD Deviasi dll. Metode ini disebut metode Statistik Non Parametrik.

59
Keuntungannya : · Data tidak harus berdistribusi Normal, (distribution free test) · Dapat digunakan untul level data nominal dan ordinal · Cenderung lebih sederhana

60
Kelemahan : · Tidak ada sistematika yang jelas
· Hasil bisa meragukan karena kesederhanaan metodenya · Tabel yang digunakan lebih banyak Dalam penggunaannya apakah akan digunakan metode parametrik atau non parametrik, semua tergantung pada situasi yang ada, dan keduanya lebih bersifat saling melengkapi dalam melakukan berbagai pengambilan keputusan.

61
SPSS (Statistical Product and Service Solutions)
Adalah suatu program komputer statistik yang mampu mengolah/memproses data statistik secara cepat dan tepat, untuk mendapatkan berbagai hasil/keluaran yang dikehendaki para pengambil keputusan

62
Komponen SPSS 1. Data Collection, mengumpulkan data untuk
pengolahan data 2. Data Preparation, persiapan data untuk pengolahan data lebih lanjut 3. Data analysis & Data mining, menyediakan berbagai perhitungan statistik untuk pengolahan data 4. Data deployment, mendistribusikan hasil pengolahan data (informasi)
")
63
Cara Kerja SPSS (analogi dengan proses komputer)
Pada Komputer Data Input Proses Komputer Data Output Pada Statistik Data Output Data Input Proses Statistik

64
Window Pada SPSS 1. Data Editor Window, Help 2. Menu Output Navigator
File, Edit, View, Data, Transform, Analize, Graphs, Utilities, Window, Help 2. Menu Output Navigator Insert, Format 3. Menu Pivot Table Editor 4. Menu Chart Editor Gallery, Chart, Series 5. Menu Text Output Editor 6. Menu Syntax Editor 7. Menu Script Editor

66
Bagian SPSS yang berhubungan dengan Statistik Deskriptif
1. Frequencies. Membahas beberapa penjabaran ukuran statistik deskriptif seperti Mean, Median, Kuartil, Persentil, Standar Deviasi dll 2. Descriptive Berfungsi untuk mengetahui skor z dari suatu distribusi data dan menguji apakah data berdistribusi normal atau tidak 3. Explore Berfungsi untuk memeriksa lebih teliti terhadap sekelompok data dengan Box-Plot dan Steam and Leaf Plot, selain beberapa uji tambahan untuk menguji apakah data berasal dari distribusi normal.

67
4. Crosstab 5. Case Summaries
Digunakan untuk menyajikan deskripsi data dalam bentuk tabel silang. Menu ini juga dilengkapi dengan analisis hubungan di antara baris dan kolom, seperti independensi antara mereka, besar hubungannya dsb 5. Case Summaries Digunakan untuk melihat lebih jauh isi statistik deskriptif yang meliputi subgroup dari sebuah kasus.

68
Penggunaan Regresi dengan SPSS.
1. Pilih menu Analyze – Regression – Linear 2. Tentukan var bergantung dan var bebas 3. Tentukan Metoda yang digunakan (Enter, Stepwise, Forward, Backward) 4. Tentukan perhitungan statistik yang diperlukan 5. Tentukan jenis plot yang diperlukan 6. Tentukan harga F testnya
 4. Tentukan perhitungan statistik yang diperlukan. 5. Tentukan jenis plot yang diperlukan. 6. Tentukan harga F testnya.")
Presentasi serupa




>")

>")


>")







>")




