Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Analisis Cluster Oleh : Rahmad Wijaya

2
Pokok Bahasan 1. Konsep Dasar 2. Statistik dalam Analisis Cluster
3. Langkah-langkah Analisis Cluster Rumuskan Permasalahan Memilih ukuran Jarak atau Kesamaan Memilih Prosedur Peng-clusteran Menetapkan Jumlah Cluster Interpretasi dan Profil dari Cluster Menaksir Reliabilitas and Validitas

3
Konsep Dasar W Cluster Analysis adalah suatu teknik mengelompokkan obyek atau cases ke dalam kelompok yang relatif homogen yang disebut CLUSTER Analisis Cluster sering juga disebut sebagai : Classification Analysis Numerical Taxonomy Pengelompokan dalam prakek sering tidak sama dengan pengelompokan yang ideal Perbedaan Analisis Discriminant dengan Cluster :

4
Situasi Pengelompokan Ideal
Variable 2 Variable 1 Back

5
Situasi Pengelompokan dalam Praktek
X Variable 2 Variable 1 Back

6
Penggunaan Analisis Cluster
Contoh : Segmentasi Pasar. Memahami perilaku pembeli Mengidentifikasi peluang produk baru. Memilih pasar yang akan diuji. Mengurangi Data

7
Statistik dalam Analisis Cluster
Agglomeration schedule Cluster centroid Cluster Centers Cluster membership Dendrogram Distance between cluster centers Incicle diagram Agglomeration schedule : Give information on the objects or cases being combined at each stage of a heirarchical clustering process Cluster centriod : the mean values of the variables for all the cases or object in particular cluster. Cluster Centers : The initial starting points in non hierarchical clustering. Clusters are built around these centers or seeds. Cluster membership Dendogram Distance between cluster centers Incicle diagram Similarity/Distance coefficient matrix 1

8
Langkah-langkah Analisis Cluster
Rumuskan Permasalahan Memilih ukuran Jarak atau Kesamaan Memilih Prosedur peng-Cluster-an Menetapkan Jumlah Cluster Interpretasi dan Profil dari Cluster Menaksir Reliablitas dan Validitas

9
Rumuskan Permasalahan
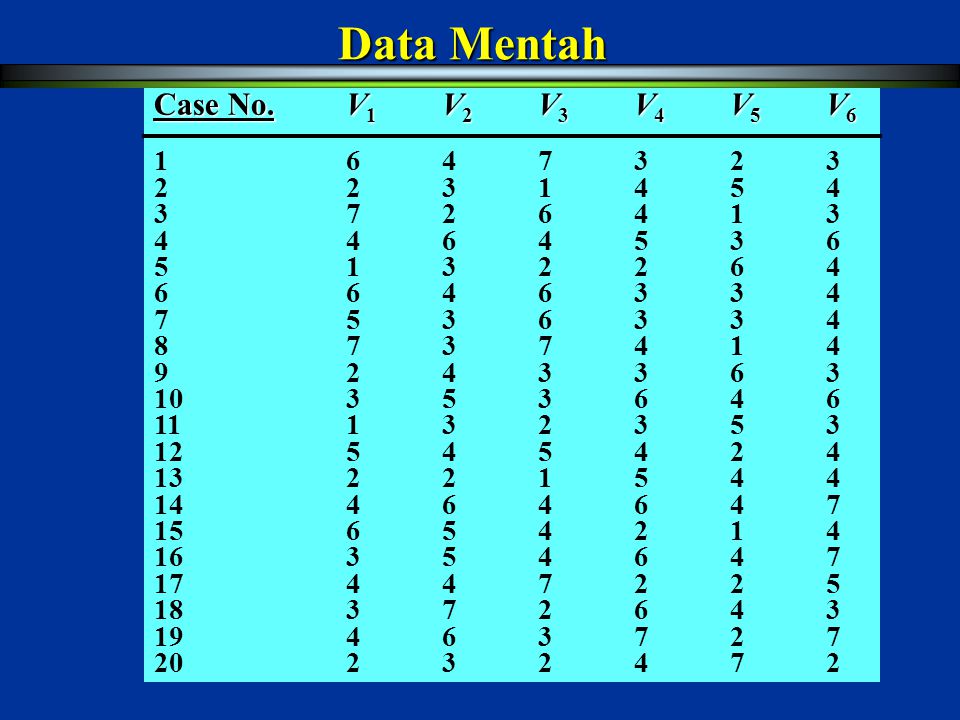
Contoh : Melakukan pengelompokan konsumen berdasarkan sikap mereka pada akvitivas belanja. Didasarkan pada penelitian sebelumnya dapat diidentifikasikan ada enamvariabel sikap. Konsumen diminta menyatakan tingkat kesepakatan mereka dengan pernyataan skala tujuh berikut ini : V1 = Shopping is fun V2 = Shopping is bad for your budget V3 = I combine shopping with eating out. V4 = I try to get best buys while shopping. V5 = I don’t care about shopping. V6 = You can save a lot of money by comparing prices. Data yang diperoleh dari 20 responden adalah sebagai berikut :

10
Data Mentah Case No. V1 V2 V3 V4 V5 V6 1 6 4 7 3 2 3 2 2 3 1 4 5 4
11
Memilih ukuran Jarak atau Kesamaan
Sebab tujuan clustering adalah mengelompokan obyek bersama-sama, maka beberapa pengukuran dibutuhkan untuk menilai perbedaan atau kesamaan diantara obyek. Pengukuran yang sering dipergunakan adalah : Euclidean Distance is square root of the sum of the square differences in values for each variables. City Block or Manhattan distance is the sum of the absolute differences in value for each variables Chebychev distance is the maximum absolute difference in values for any variables.

12
Klasifikasi Prosedur peng-Cluster-an Clustering Procedures
Hierarchical Nonhierarchical Agglomerative Divisive Sequential Threshold Parallel Threshold Optimizing Partitioning Linkage Methods Variance Methods Centroid Methods Ward’s Method Single Complete Average

13
Metode Hubungan Cluster (Linkage)
Single Linkage Minimum Distance Cluster 1 Cluster 2 Complete Linkage Maximum Distance Cluster 1 Cluster 2 Average Linkage Average Distance Cluster 1 Cluster 2

14
Metode Cluster Agglomerative lainnya
Ward’s Procedure Centroid Method

15
Output Cluster Hirarki

16
Icicle Plot Vertikal Jumlah Cluster Nomor Kasus Back 8+ 1+ 4+ 5+ 6+ 7+
2+ 3+ 11+ 12+ 13+ 14+ 9+ 10+ 16+ 19+ 17+ 18+ 15+ 1 Nomor Kasus 2 9 8 4 6 3 5 7 Jumlah Cluster Back

17
Dendrogram Using Ward’s Method
3 15 1 12 7 8 17 6 11 5 13 2 20 9 19 16 4 10 18 14 Back Case Label Seq 5 10 15 20 25 Rescaled Distance Cluster Combine

18
4 cluster 3 cluster 2 cluster 1 8 2 6 12 3 5 4
Keanggotaan Cluster Jumlah anggota per cluster Cluster 4 cluster 3 cluster 2 cluster 1 8 2 6 12 3 5 4

19
Menetapkan Jumlah Cluster
Pedoman dalam menetapkan jumlah cluster : Theoretical, conceptual, or practical consideration may suggest a certain number of cluster. In hierarchical clustering, the distance at which cluster are combined can be used as criteria. Thins information can be obtained from the agglomeration schedule or from the dendrogram. In non hierarchical clustering the ratio within group variance to between group variance can be plotted against the number of cluster. Point at which an elbow or a sharp bend occurs indicates an appropriate number of clusters. The relative size of clusters should be meaningful. In Cluster Membership table by making a simple frequency count of cluster membership. We. See that a three-cluster solution result in cluster with eight, six, and six element. However, if we go to four-cluster solution, the size of clusters are eight, six, five, and one. It is not meaningful to have a cluster with only one case.

20
Cluster Centroids Rata-rata per Variabel No. Cluster V1 V2 V3 V4 V5 V6 dapa Nilai Cluster Centriod dapat diperoleh dari Pengolahan Data K-Mean Cluster (lihat pada Final Cluster Center)
")
21
Menghitung Cluster Centroids pakai Ms Ecxel
No Resp V1 v2 v3 v4 v5 v6 Cluster membership 1 6 4 7 3 2 5 8 12 15 17 5,75 3,63 3,13 1,88 3,88 9 11 13 20 1,67 1,83 3,5 5,5 3,33 10 14 16 18 19 5,83 Cluster centroid untuk Cluster 1 Cluster centroid untuk Cluster 2 dapa Cluster centroid untuk Cluster 2

22
Interpretasi and Profil dari Cluster
Kita lihat dari Tabel Cluster Centroid : Pada Cluster 1 V1(shopping is fun), dan V3 (I combine shopping with eating out) nilainya relatif tinggi, sehingga cluster ini dapat diberi nama “fun-loving and concerned shoppers” Pada Cluster 2 V5(I don’t care about shopping) nilainya relatif tinggi, sehingga cluster ini dapat diberi nama “apathetic shoppers” Pada Cluster 3 V2 (Shopping is bad for my budget), V4 (I try to get the best buys while shopping) , dan V6 (You can save a lot of money by comparing prices) nilainya relatif tinggi, sehingga cluster ini dapat diberi nama “economical shoppers”
, dan V3 (I combine shopping with eating out) nilainya relatif tinggi, sehingga cluster ini dapat diberi nama fun-loving and concerned shoppers Pada Cluster 2 V5(I don’t care about shopping) nilainya relatif tinggi, sehingga cluster ini dapat diberi nama apathetic shoppers Pada Cluster 3 V2 (Shopping is bad for my budget), V4 (I try to get the best buys while shopping) , dan V6 (You can save a lot of money by comparing prices) nilainya relatif tinggi, sehingga cluster ini dapat diberi nama economical shoppers")
23
Menaksir Reliabilitas dan Validitas
Prosedur formal untuk menilai reliabilitas dan viliditas dari hasil cluster kompleks. Prosedur berikut cukup memadai untuk mengecek kualitas hasil cluster : 1. Perform cluster analysis on the same data using different distance measure. Compare the result across measure to determine the stability of the solutions. 2. Use different methods of clustering and compare the result. 3. Split the data randomly in halves. Perform clustering separetly on each half. Compare cluster centroids across the two subsamples. 4. Delete variables randomly. Perform clustering based on the reduced set of variables. Compare the result with those obtained by clustering based on the entire set of variables.

24
Results of Nonhierarchical Clustering
Initial Cluster Centers Cluster V1 V2 V3 V4 V5 V6 Classification Cluster Centers Cluster V1 V2 V3 V4 V5 V6 Case Listing of Cluster Membership Case ID Cluster Distance Case ID Cluster Distance

25
Distances between Final Cluster Centers
Cluster V1 V2 V3 V4 V5 V6 Distances between Final Cluster Centers Cluster Analysis of Variance Variable Cluster MS df Error MS df F p V V V V V V Number of Cases in each Cluster Cluster Unweighted Cases Weighted Cases Missing Total

Presentasi serupa










>")








