Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
PENERAPAN ALGORITMA MODIFIED K-NEAREST NEIGHBOR (MKNN) UNTUK MENGKLASIFIKASIKAN LETAK PROTEIN PADA BAKTERI E.COLI Kelompok : Rosangelina / Prasetia Adi P / Dimas Fanny H. P. /

2
Latar Belakang Bakteri E.Coli adalah salah satu jenis spesies utama bakteri gram negatif atau jenis bakteri patogen. Bakteria Escherichia Coli, merupakan bakteri yang pada umumnya hidup di dalam usus besar manusia, kebanyakan dari bakteri E.Coli tidak berbahaya bahkan keberadaannya bisa dibilang menguntungkan. Fungsi potensial dari bakteri tersebut sangat dipengaruhi oleh penyebaran protein pada selnya. Sehingga diperlukan penelitian pada E.Coli guna mempermudah para ahli microbiology dalam mengklasifikasikan kelas-kelasnya berdasarkan letak proteinnya. Untuk mempermudah tahapan pengklasifikasian bakteri E-Coli berdasarkan letak proteinnya maka digunakan metode data mining.

3
Tujuan Penerapan algoritma Modified K-Nearest Neighbor (MKNN) untuk mengklasifikasikan letak protein pada bakteri E.Coli Pengujian akurasi algoritma Modified K-Nearest Neighbor (MKNN) terhadap banyak data tes dan nilai tetangga. untuk mengklasifikasikan bakteri E.Coli berdasarkan letak protein di tubuhnya agar dapat digolongkan bakteri E. Coli yang merugikan dan tidak.
 terhadap banyak data tes dan nilai tetangga. untuk mengklasifikasikan bakteri E.Coli berdasarkan letak protein di tubuhnya agar dapat digolongkan bakteri E. Coli yang merugikan dan tidak.")
4
Manfaat Dengan mengetahui letak protein pada bakteri E.Coli, diharapkan dapat mengurangi penyebab bakteri patogen. Dapat mengetahui tingkat akurasi pada algoritma pengujian akurasi algoritma Modified K-Nearest Neighbor (MKNN) terhadap banyak data tes dan nilai tetangga untuk pengklasifikasian letak protein pada bakteri E.Coli.
 terhadap banyak data tes dan nilai tetangga untuk pengklasifikasian letak protein pada bakteri E.Coli.")
5
Metode Penyelesaian Masalah
Studi literatur. Mempelajari dan mengkaji beberapa literatur (jurnal, buku, dan artikel dari website) mengenai data mining, algoritma pengujian akurasi algoritma Modified K-Nearest Neighbor (MKNN). Perumusan masalah dan analisa kebutuhan Mengkaji permasalahan sebagai hasil dari studi pustaka dan menganalisis yang dibutuhkan. Perancangan dan implementasi sistem. Mengimplementasikan algoritma MKNN dengan merancang dan membangun sebuah perangkat lunak untuk mengklasifikasikan data protein pada E.Coli. Uji coba dan analisis hasil implementasi. Menganalisa akurasi hasil pengklasifikasian data dengan menggunakan model klasifikasi.
 mengenai data mining, algoritma pengujian akurasi algoritma Modified K-Nearest Neighbor (MKNN). Perumusan masalah dan analisa kebutuhan. Mengkaji permasalahan sebagai hasil dari studi pustaka dan menganalisis yang dibutuhkan. Perancangan dan implementasi sistem. Mengimplementasikan algoritma MKNN dengan merancang dan membangun sebuah perangkat lunak untuk mengklasifikasikan data protein pada E.Coli. Uji coba dan analisis hasil implementasi. Menganalisa akurasi hasil pengklasifikasian data dengan menggunakan model klasifikasi.")
6
Definisi K-Nearest Neighbor (KNN)
Algoritma K-Nearest Neighbor (KNN) adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data.
 adalah sebuah metode untuk melakukan klasifikasi terhadap objek berdasarkan data pembelajaran yang jaraknya paling dekat dengan objek tersebut. Data pembelajaran diproyeksikan ke ruang berdimensi banyak, dimana masing-masing dimensi merepresentasikan fitur dari data.")
7
Proses K-Nearest Neighbor (KNN)
Menurut Agusta, 2007 bahwa prinsip kerja K-Nearest Neighbor (KNN) adalah mencari jerak terdekat antara data yang dievaluasi dengan k tetangga terdekatnya dalam data pelatihan. Persamaan perhitungan untuk mencari euclidean dengan d adalah jarak dan p adalah dimensi data dengan: dimana : x1: sample data uji x2 : data uji d : jarak p : dimensi data
 adalah mencari jerak terdekat antara data yang dievaluasi dengan k tetangga terdekatnya dalam data pelatihan. Persamaan perhitungan untuk mencari euclidean dengan d adalah jarak dan p adalah dimensi data dengan: dimana : x1: sample data uji. x2 : data uji. d : jarak. p : dimensi data.")
8
Definisi Modified K-Nearest Neighbor (MKNN)
Modified K-Nearest Neighbor (MKNN) adalah menempatkan label kelas data sesuai dengan k divalidasi poin data yang sudah ditetapkan dengan perhitungan K-Nearest Neighbor (KNN) tertimbang.(Hamid Parvin, 2008)
 adalah menempatkan label kelas data sesuai dengan k divalidasi poin data yang sudah ditetapkan dengan perhitungan K-Nearest Neighbor (KNN) tertimbang.(Hamid Parvin, 2008)")
9
Proses Modified K-Nearest Neighbor (MKNN)
Dalam algoritma MKNN, setiap data pada data training harus divalidasi terlebih dahulu pada awalnya. Validitas setiap data tergantung pada setiap tetangganya. Proses validasi dilakukan untuk semua data pada data training. Setelah dihitung validitas tiap data maka nilai validitas tersebut digunakan sebagai informasi lebih mengenai data tersebut. Untuk menghitung validitas dari data pada data training, tetangga terdekatnya perlu dipertimbangkan. Di antara tetangga terdekat dengan data, validitas digunakan untuk menghitung jumlah titik dengan label yang sama untuk data tersebut. Persamaan yang digunakan untuk menghitung validitas dari setiap titik pada data training adalah seperti pada persamaan : dimana : H : jumlah titik terdekat LBL (x) : kelas x N i (X) : label kelas titik terdekat x Fungsi S digunakan untuk menghitung kesamaan antara titik x dan data ke-i dari tetangga terdekat. Yang dituliskan dalam persamaan. Keterangan: a = kelas a pada data training. b = kelas lain selain a pada data training.
 : kelas x. N i (X) : label kelas titik terdekat x. Fungsi S digunakan untuk menghitung kesamaan antara titik x dan data ke-i dari tetangga terdekat. Yang dituliskan dalam persamaan. Keterangan: a = kelas a pada data training. b = kelas lain selain a pada data training.")
10
Perhitungan akurasi Perhitungan akurasi dilakukan untuk mengetahui tingkat akurasi dari hasil klasifikasi, dengan cara menghitung jumlah record uji yang kelasnya diprediksi secara tepat . Dapat dilihat pada persamaan dibawah ini. Jumlah predikasi benar adalah jumlah record data uji yang diprediksi kelasnya menggunakan metode klasifikasi dan hasilnya sama dengan kelas sebenarnya. Sedangkan jumlah total prediksi adalah jumlah keseluruhan record yang diprediksi kelasnya (seluruh data uji). Metode klasifikasi berusaha untuk mencari model yang memiliki tingkat akurasi yang tinggi ketika model tersebut diterapkan pada data uji.( Sarkar dan Leong, 2000)
. Metode klasifikasi berusaha untuk mencari model yang memiliki tingkat akurasi yang tinggi ketika model tersebut diterapkan pada data uji.( Sarkar dan Leong, 2000)")
11
Flowchart Sistem Langkah-langkah dalam proses ini antara lain yaitu :
Melakukan input data bakteri. Melakukan proses klasifikasi untuk menentukan letak protein pada bakteri E.Coli. Output data bakteri setelah dilakukan klasifikasi.

12
Gambar flowchart

13
Proses Klasifikasi MKNN
Langkah-langkah dalam proses ini antara lain yaitu : Memberikan inputan berupa dataset bakteri. Melakukan proses perhitungan validitas dari tiap data pada dataset bakteri. Melakukan proses perhitungan jarak euclidean pada tiap data pada dataset bakteri. Melakukan proses perhitungan weight voting dari data set bakteri dan mengambil nilai weight voting yang terbesar berdasarkan jumlah nilai tetangga yang diinputkan. Memberikan keluaran data berupa kelas yang menunjukkan letak protein pada tubuh bakteri E.Coli

14
Menghitung Validitas Langkah-langkah dalam proses ini antara lain yaitu : Memberikan inputan data bakteri. Menentukan nilai k-nya. Melakukan perhitungan validitas sesuai persamaan sebelumnya Memberikan keluaran berupa hasil validitas.

15
Menghitung Euclidean Langkah-langkah dalam proses ini antara lain yaitu : Memberikan inputan data bakteri. Melakukan perhitungan euclidean sesuai persamaan sebelumnya Memberikan keluaran berupa nilai euclidean.

16
Menghitung Weight Voting
Langkah-langkah dalam proses ini antara lain yaitu : Memasukkan nilai euclidean dan nilai validitas-nya. Melakukan perhitungan weight voting-nya. Memberikan keluaran berupa nilai weight voting-nya.

17
Contoh Perhitungan Manual
Dari algoritma Modified K-Nearest Neighbor (MKNN) ini langkah-langkah dalam perhitungannya antara lain yaitu : Menentukan nilai k atau tetangganya. Menghitung validitas data training. Menghitung jarak euclidean Menghitung pembobotan (weight voting) Menentukan kelas dari data testing
 ini langkah-langkah dalam perhitungannya antara lain yaitu : Menentukan nilai k atau tetangganya. Menghitung validitas data training. Menghitung jarak euclidean. Menghitung pembobotan (weight voting) Menentukan kelas dari data testing.")
18
Data Testing dan Data Traning pada data letak protein pada bakteri E
Data Testing dan Data Traning pada data letak protein pada bakteri E.Coli. Nama0 Mcg Gvh Lip Chg Aac Alm1 Alm2 Kelas Kdsa_ecoli 0.51 0.37 0.48 0.50 0.35 0.36 0.45 ? Nird_ecoli 0.44 0.42 0.25 0.20 Cp Plfb_ecoli 0.29 0.41 0.18 0.30 Ubic_ecoli 0.57 0.78 0.80 Im Cyda_ecoli 0.55 0.47 Pnta_ecoli 0.33 0.46 0.65 0.69 im

19
Menentukan nilai k atau tetangganya
Pada perhitungan ini ditentukan nilai dari k yaitu 3.

20
Menghitung validitas data training
Setelah ditentukan nilai k-nya maka dihitung nilai validitas dari data training dengan persamaan sebelumnya

21
Tabel Perhitungan Validitas
K=1 K=2 K=3 Sum S(a,b) validitas 1 2 0.6667 0.3333
 validitas")
22
Menghitung jarak euclidean
Pada perhitungan mencari nilai euclidean dengan memasukkan data pada persamaan sebelumnya

23
Tabel hasil perhitungan
Melakukan perhitungan yang sama untuk semua data training. Hasil perhitungan euclidean ini seperti yang ditunjukkan tabel Perhitungan Euclidean Sum Euclidian Euclidian 0.0869 1.207 0.0371 0.5549 0.3748

24
Menghitung pembobotan (weight voting)
Pada tahapan menghitung nilai weight voting yang didapat dari memasukkan nilai validitas dan nilai euclidean pada persamaan berikut :

25
Tabel hasil perhitungan
Melakukan perhitungan yang sama untuk semua data training. Hasil perhitungan weight voting ini seperti yang ditunjukkan tabel Perhitungan Weight Voting Weight

26
Menentukan kelas dari data testing
Setelah didapatkan nilai weight voting dari semua data training maka dilakukan pencarian nilai weight voting yang terbesar sebanyak nilai k yang telah ditentukan. Maka didapatkan nilai dengan 3 weight voting terbesar yaitu dengan kelasnya CP, dengan kelasnya CP, dan dengan kelasnya IM. Dari data testing yang telah ditentukan maka ke kelas yang didapat pada data testing adalah CP karena kelas yang sering muncul adalah CP.

27
Pengkodingan input file data
Untuk melakukan input data adalah dengan cara merandom data bakteri E.Coli dengan cara random unik yaitu dengan mengurutkan tiap kelas bakteri agar dapat mewakili tiap kelasnya saat dilakukan klasifikasi. Kemudian setelah data selesai diurutkan dimasukkan ke table bakteri.

28
koding var acak = new Random(); var dialog = new OpenFileDialog();
if (dialog.ShowDialog() == System.Windows.Forms.DialogResult.OK) { daftarBakteri = Bakteri.BacaFileBakteri(dialog.FileName).OrderBy(x => acak.Next()) .ToArray(); urutkanKelas(daftarBakteri); urutkanKelasTerbalik(daftarBakteri); } dataGridView1.DataSource = daftarBakteri.CopyToDataTable(); nUDJumlahLatih.Maximum = daftarBakteri.Length - 1; nUDKAwal.Maximum = daftarBakteri.Length - 1;
 == System.Windows.Forms.DialogResult.OK) { daftarBakteri = Bakteri.BacaFileBakteri(dialog.FileName).OrderBy(x => acak.Next()) .ToArray(); urutkanKelas(daftarBakteri); urutkanKelasTerbalik(daftarBakteri); } dataGridView1.DataSource = daftarBakteri.CopyToDataTable(); nUDJumlahLatih.Maximum = daftarBakteri.Length - 1; nUDKAwal.Maximum = daftarBakteri.Length - 1;")
29
Membaca dan memasukkan data pada table
Pada tahapan membaca file berikut ini data dimasukkan ke variable dipisahkan berdasarkan spasi {“ “}. Sedangkan tanda {“.”} adalah koma pada attribut numeriknya. Fungsi variable tipe kelas berfungsi untuk menyimpan attribut kelas pada data bakteri

30
koding if (pisahan[8] == "cp") { kelas = Kelas.cp; }
else if (pisahan[8] == "im") kelas = Kelas.im; else if (pisahan[8] == "pp") kelas = Kelas.pp; else if (pisahan[8] == "imU") kelas = Kelas.imU; public static IEnumerable<Bakteri> BacaFileBakteri(string lokasiFile) { var format = new NumberFormatInfo(); format.NumberDecimalSeparator = "."; foreach (var baris in File.ReadLines(lokasiFile)) var pisahan = baris.Split(new[] { ' ', '\t' }, StringSplitOptions.RemoveEmptyEntries); var nama = pisahan[0]; var mcg = double.Parse(pisahan[1], format); var gvh = double.Parse(pisahan[2], format); var lip = double.Parse(pisahan[3], format); var chg = double.Parse(pisahan[4], format); var aac = double.Parse(pisahan[5], format); var alm1 = double.Parse(pisahan[6], format); var alm2 = double.Parse(pisahan[7], format); Kelas kelas;
![koding if (pisahan[8] == cp ) { kelas = Kelas.cp; }](http://slideplayer.info/slide/2570380/9/images/30/koding+if+%28pisahan%5B8%5D+%3D%3D+cp+%29+%7B+kelas+%3D+Kelas.cp%3B+%7D.jpg "else if (pisahan[8] == im ) kelas = Kelas.im; else if (pisahan[8] == pp ) kelas = Kelas.pp; else if (pisahan[8] == imU ) kelas = Kelas.imU; public static IEnumerable<Bakteri> BacaFileBakteri(string lokasiFile) { var format = new NumberFormatInfo(); format.NumberDecimalSeparator = . ; foreach (var baris in File.ReadLines(lokasiFile)) var pisahan = baris.Split(new[] { , \t }, StringSplitOptions.RemoveEmptyEntries); var nama = pisahan[0]; var mcg = double.Parse(pisahan[1], format); var gvh = double.Parse(pisahan[2], format); var lip = double.Parse(pisahan[3], format); var chg = double.Parse(pisahan[4], format); var aac = double.Parse(pisahan[5], format); var alm1 = double.Parse(pisahan[6], format); var alm2 = double.Parse(pisahan[7], format); Kelas kelas;")
31
Koding (cont’d) else if (pisahan[8] == "om") { kelas = Kelas.om; }
else if (pisahan[8] == "omL") kelas = Kelas.omL; else if (pisahan[8] == "imL") kelas = Kelas.imL; else kelas = Kelas.imS; yield return new Bakteri(nama, mcg, gvh, lip, chg, aac, alm1, alm2, kelas); yield break;}
![Koding (cont’d) else if (pisahan[8] == om ) { kelas = Kelas.om; }](http://slideplayer.info/slide/2570380/9/images/31/Koding+%28cont%E2%80%99d%29+else+if+%28pisahan%5B8%5D+%3D%3D+om+%29+%7B+kelas+%3D+Kelas.om%3B+%7D.jpg "else if (pisahan[8] == omL ) kelas = Kelas.omL; else if (pisahan[8] == imL ) kelas = Kelas.imL; else. kelas = Kelas.imS; yield return new Bakteri(nama, mcg, gvh, lip, chg, aac, alm1, alm2, kelas); yield break;}")
32
Mengurutkan kelas pada data bakteri dari atas
Pada tahapan mengurutkan kelas pada data bakteri dari atas adalah mengurutkan atribut kelasnya dari data yang paling atas secara unik, yaitu dengan cara menukar tiap kelas agar mewakili atrtribut datanya. Proses mengurutkan datanya diseleksi dari kelas bakterinya, yaitu dari 8 kelasnya dibandingkan dengan 7 kelas lain yang berbeda. Ketika kelas bawah yang dibandingkan sama dengan index maka dilakukan penukaran kelasnya.

33
koding private static void urutkanKelas(Bakteri[] dB) {
for (int index = 1; index <= 7; index++) var tukar = index + 1; while (dB.Take(index).Select(x => x.Kelas).Contains(dB[index].Kelas)) var temp = dB[tukar]; dB[tukar] = dB[index]; dB[index] = temp; tukar++; }
![koding private static void urutkanKelas(Bakteri[] dB) {](http://slideplayer.info/slide/2570380/9/images/33/koding+private+static+void+urutkanKelas%28Bakteri%5B%5D+dB%29+%7B.jpg "for (int index = 1; index <= 7; index++) var tukar = index + 1; while (dB.Take(index).Select(x => x.Kelas).Contains(dB[index].Kelas)) var temp = dB[tukar]; dB[tukar] = dB[index]; dB[index] = temp; tukar++; }")
34
Mengurutkan kelas pada data bakteri dari bawah
private static void urutkanKelasTerbalik(Bakteri[] dB) { for (int index = 1; index <= 7; index++) var tukar = index + 1; while (dB.Skip(dB.Count() - index).Select(x => x.Kelas).Contains(dB[dB.Count() - 1 - index].Kelas)) var temp = dB[dB.Count() tukar]; dB[dB.Count() tukar] = dB[dB.Count() index]; dB[dB.Count() index] = temp; tukar++; }
 { for (int index = 1; index <= 7; index++) var tukar = index + 1; while (dB.Skip(dB.Count() - index).Select(x => x.Kelas).Contains(dB[dB.Count() index].Kelas)) var temp = dB[dB.Count() tukar]; dB[dB.Count() tukar] = dB[dB.Count() index]; dB[dB.Count() index] = temp; tukar++; }")
35
Proses Klasifikasi MKNN
Pada proses klasifikasi MKNN sendiri melalui beberapa proses tahapan yang diantaranya hitung euclidean, hitung validitas, kemudian hitung weight voting yang akan digunakan untuk menentukan kelas pada data testing berdasarkan ketentuan pembobotan yang telah didapatkan. Tahapan proses klasifikasi sendiri adalah dengan membagi data latih dan data uji adalah dengan membagi jumlah data yang akan dilakukan klasifikasi data sesuai record yang akan diinputkan.

36
koding { var acak = new Random();
var daftarTraining = daftarBakteri.Take((int)nUDJumlahLatih.Value).Select(x =>x.Duplikat()).ToArray(); var daftarTesting = daftarBakteri.Skip((int)nUDJumlahLatih.Value).Select(x => x.Duplikat()).ToArray(); urutkanKelas(daftarTesting); dgDataUji.DataSource = daftarTesting.CopyToDataTable(); var kelasAsli = daftarTesting.Select(x => x.Kelas).ToArray(); var daftarHasilTesting = Enumerable.Range(0, daftarTesting.Count()).Select(x => new List<Kelas>()).ToArray(); //new List<Kelas>[daftarTesting.Count()]; var daftarAkurasi = Enumerable.Range(0, daftarTesting.Count()).Select(x => new List<bool>()).ToArray(); //untuk menampilkan perulangan inputan sesuai jumlah k nya for (int index = (int)nUDKAwal.Value; index <= (int)nUDKAkhir.Value; index++) daftarTraining.HitungKelas(daftarTesting, index); for (int i = 0; i < daftarHasilTesting.Count(); i++) daftarHasilTesting[i].Add(daftarTesting[i].Kelas); daftarAkurasi[i].Add(daftarTesting[i].Kelas == kelasAsli[i]); }
nUDJumlahLatih.Value).Select(x =>x.Duplikat()).ToArray(); var daftarTesting = daftarBakteri.Skip((int)nUDJumlahLatih.Value).Select(x => x.Duplikat()).ToArray(); urutkanKelas(daftarTesting); dgDataUji.DataSource = daftarTesting.CopyToDataTable(); var kelasAsli = daftarTesting.Select(x => x.Kelas).ToArray(); var daftarHasilTesting = Enumerable.Range(0, daftarTesting.Count()).Select(x => new List<Kelas>()).ToArray(); //new. List<Kelas>[daftarTesting.Count()]; var daftarAkurasi = Enumerable.Range(0, daftarTesting.Count()).Select(x => new List<bool>()).ToArray(); //untuk menampilkan perulangan inputan sesuai jumlah k nya. for (int index = (int)nUDKAwal.Value; index <= (int)nUDKAkhir.Value; index++) daftarTraining.HitungKelas(daftarTesting, index); for (int i = 0; i < daftarHasilTesting.Count(); i++) daftarHasilTesting[i].Add(daftarTesting[i].Kelas); daftarAkurasi[i].Add(daftarTesting[i].Kelas == kelasAsli[i]); }")
37
Proses klasifikasi menentukan kelas pada data testingnya
Proses hitung kelas ini adalah urutan proses klasifikasi dengan menentukan validitasnya, lalu euclidean, kemudian dibobotkan. Pada validitas ditentukan nilai k nya dengan k maksimal k = training.Count() - 1; , yaitu k maksimal didapatkan sejumlah data latih-1. Untuk hasil pembobotan sendiri diambil nilai yang paling besar.
 - 1; , yaitu k maksimal didapatkan sejumlah data latih-1. Untuk hasil pembobotan sendiri diambil nilai yang paling besar.")
38
koding foreach (var test in testing) { test.Kelas = Kelas.xx;
var max = double.MinValue; var indexMax = 0; for (int train = 0; train < training.Length; train++) var weightVoting = validitas[train] / (test.JarakEuclidean(training[train]) + 0.5); if (max < weightVoting) max = weightVoting; indexMax = train; } test.Kelas = training[indexMax].Kelas; public static void HitungKelas(this Bakteri[] training, Bakteri[] testing, int k = 0) { if (k == 0) k = training.Count() - 1; } var validitas = training.Validitas(k).ToArray();
 var weightVoting = validitas[train] / (test.JarakEuclidean(training[train]) + 0.5); if (max < weightVoting) max = weightVoting; indexMax = train; } test.Kelas = training[indexMax].Kelas; public static void HitungKelas(this Bakteri[] training, Bakteri[] testing, int k = 0) { if (k == 0) k = training.Count() - 1; } var validitas = training.Validitas(k).ToArray();")
39
Hitung validitas Pada proses hitung validitas ini membahas perhitungan validitas membandingkan kelas pada data training dengan tetangga terdekat dan dilakukan penjumlahan lalu dibagi sebanyak nilai k yang diinputkan sesuai dengan persamaan – persamaan yang lalu

40
koding public static IEnumerable<double> Validitas(this Bakteri[] training, int k) { for (int index = 0; index < training.Length; index++) var kesamaan = 0; for (int indexK = 1; indexK <= k; indexK++) if (training[index].Kelas == training[(index + indexK) % training.Length].Kelas) kesamaan++; } yield return kesamaan / (double)k; yield break;
![koding public static IEnumerable<double> Validitas(this Bakteri[] training, int k) { for (int index = 0; index < training.Length;](http://slideplayer.info/slide/2570380/9/images/40/koding+public+static+IEnumerable%3Cdouble%3E+Validitas%28this+Bakteri%5B%5D+training%2C+int+k%29+%7B+for+%28int+index+%3D+0%3B+index+%3C+training.Length%3B.jpg "index++) var kesamaan = 0; for (int indexK = 1; indexK <= k; indexK++) if (training[index].Kelas == training[(index + indexK) % training.Length].Kelas) kesamaan++; } yield return kesamaan / (double)k; yield break;")
41
Hitung Euclidean Pada proses Hitung Euclidean ini membahas tentang tahapan awal proses klasifikasi yaitu proses menghitung euclidean pada data bakteri. Euclidean dihitung dari jarak tiap atribut pada data testing dengan data training sesuai persamaan

42
koding public static double JarakEuclidean(this Bakteri a, Bakteri b)
{ var totalJarak = (a.AAC - b.AAC) * (a.AAC - b.AAC); totalJarak += (a.ALM1 - b.ALM1) * (a.ALM1 - b.ALM1); totalJarak += (a.ALM2 - b.ALM2) * (a.ALM2 - b.ALM2); totalJarak += (a.CHG - b.CHG) * (a.CHG - b.CHG); totalJarak += (a.GVH - b.GVH) * (a.GVH - b.GVH); totalJarak += (a.LIP - b.LIP) * (a.LIP - b.LIP); totalJarak += (a.MCG - b.MCG) * (a.MCG - b.MCG); return Math.Sqrt(totalJarak); }
 * (a.AAC - b.AAC); totalJarak += (a.ALM1 - b.ALM1) * (a.ALM1 - b.ALM1); totalJarak += (a.ALM2 - b.ALM2) * (a.ALM2 - b.ALM2); totalJarak += (a.CHG - b.CHG) * (a.CHG - b.CHG); totalJarak += (a.GVH - b.GVH) * (a.GVH - b.GVH); totalJarak += (a.LIP - b.LIP) * (a.LIP - b.LIP); totalJarak += (a.MCG - b.MCG) * (a.MCG - b.MCG); return Math.Sqrt(totalJarak); }")
43
Hitung nilai weight voting
Pada proses hitung weight voting ini membahas perhitungan bobot pada data bakteri, yaitu dengan membandingkan data validitas dengan euclidean. Dari tahapan ini akan dilakukan pembobotan, yang bertujuan untuk menentukan kelas pada data testing dengan mengambil nilai maksimal/terbesar dari hasil perhitungan yang diperoleh. Menghitung nilai weight voting sendiri dilakukan dengan cara melakukan perhitungan nilai dari data testing dengan data training sesuai persamaan

44
koding var weightVoting = validitas[train] / (test.JarakEuclidean(training[train]) + 0.5);
![koding var weightVoting = validitas[train] / (test.JarakEuclidean(training[train]) + 0.5);](http://slideplayer.info/slide/2570380/9/images/44/koding+var+weightVoting+%3D+validitas%5Btrain%5D+%2F+%28test.JarakEuclidean%28training%5Btrain%5D%29+%2B+0.5%29%3B.jpg "koding var weightVoting = validitas[train] / (test.JarakEuclidean(training[train]) + 0.5);")
45
Implementasi Pengujian
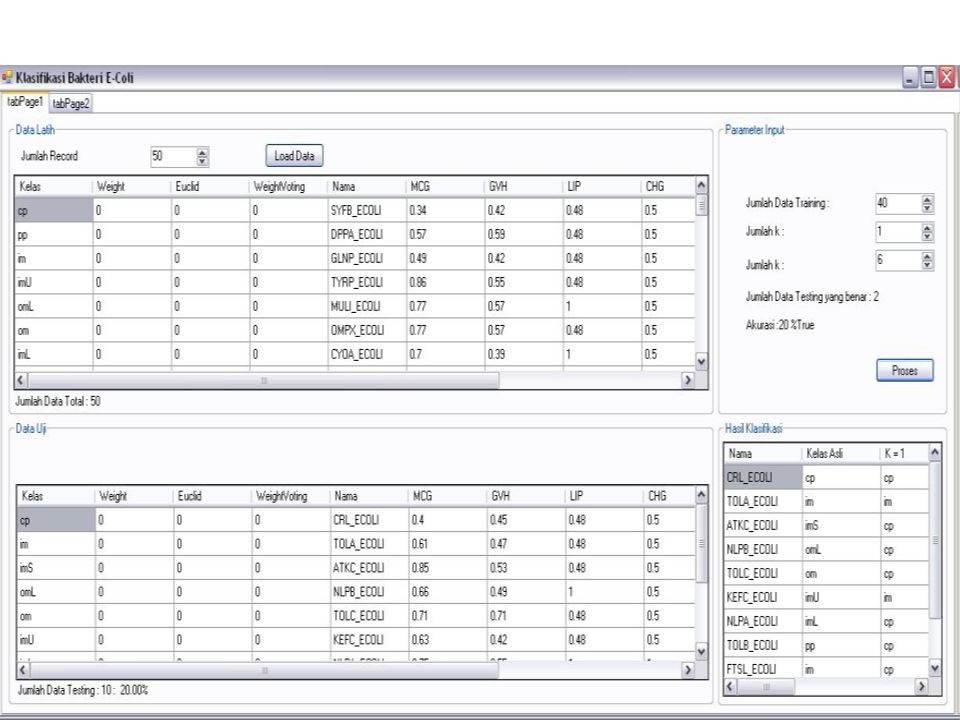
Pada pengujian klasifikasi digunakan dataset bakteri E.Coli yang tediri dari 336 record. Data yang digunakan dalam sistem yaitu data bakteri E-Coli tentang letak protein pada tiap bagian tubuh bakteri E-Coli yang dibagi menjadi beberapa kelas. Pada data ini atribut yang digunakan antara lain yaitu mcg (Metode McGeoch untuk penentuan urutan sinyal), gvh (Metode von Heijne untuk penentuan urutan sinyal), lip ( Sinyal peptidase von Heijne itu konsensus II skor berurutan), chg ( Kehadiran biaya di N-terminus lipoprotein diprediksi), aac ( skor analisis diskriminan dari kandungan asam amino membran luar dan protein periplasmic), alm (skor dari Alom membran program mencakup wilayah prediksi), alm2 (skor program Alom setelah mengecualikan sinyal cleavable (membelah) putatif daerah dari urutan). Jumlah data yang digunakan ada 336 data bakteri E-Coli yang terdiri dari 7 atribut kelas bakteri. Pada data ini ditunjukkan letak protein pada tubuh bakteri E-Coli berdasarkan jumlahnya yaitu; cp (cytoplasm) 143 im (inner membrane without signal sequence) 77 pp (perisplasm) 52 imU (inner membrane, uncleavable signal sequence) 35 om (outer membrane) 20 omL (outer membrane lipoprotein) 5 imL (inner membrane lipoprotein) 2 imS (inner membrane, cleavable signal sequence) 2
, gvh (Metode von Heijne untuk penentuan urutan sinyal), lip ( Sinyal peptidase von Heijne itu konsensus II skor berurutan), chg ( Kehadiran biaya di N-terminus lipoprotein diprediksi), aac ( skor analisis diskriminan dari kandungan asam amino membran luar dan protein periplasmic), alm (skor dari Alom membran program mencakup wilayah prediksi), alm2 (skor program Alom setelah mengecualikan sinyal cleavable (membelah) putatif daerah dari urutan). Jumlah data yang digunakan ada 336 data bakteri E-Coli yang terdiri dari 7 atribut kelas bakteri. Pada data ini ditunjukkan letak protein pada tubuh bakteri E-Coli berdasarkan jumlahnya yaitu; cp (cytoplasm) 143. im (inner membrane without signal sequence) 77. pp (perisplasm) 52. imU (inner membrane, uncleavable signal sequence) 35. om (outer membrane) 20. omL (outer membrane lipoprotein) 5. imL (inner membrane lipoprotein) 2. imS (inner membrane, cleavable signal sequence) 2.")
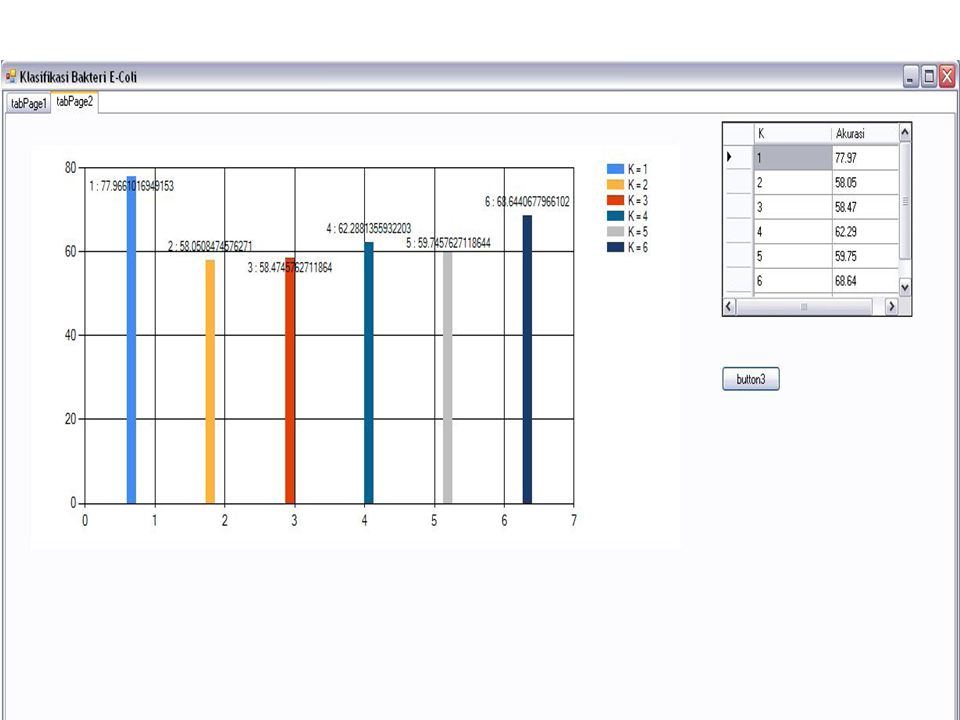
46
Hasil Uji Pengujian yang pertama dilakukan untuk mengetahui pengaruh nilai k terhadap tingkat akurasi. Sedangkan pengujian yang kedua dilakukan untuk mengetahui pengaruh jumlah data training terhadap tingkat akurasi.

47
Tabel pengujian pada data set E.Coli
Pada tabel pengujian ini terdapat 3 parameter antara lain menentukan jumlah record, jumlah nilai k dan rasio. Pada pengujian jumlah record terdapat 4 record data yang terdiri dari record 50, 100, 200, dan 300 dengan perulangan nilai k=1 sampai dengan k=20. Sedangkan rasionya terdiri dari 3 pengujian yaitu 8:2, 7:3, dan 6:4.

48
Pengujian Pada Record 50 Pada pengujian data bakteri rasio 8:2 ini didapatkan hasil pengujian dengan nilai akurasi maksimum pada jumlah record 50 adalah 30% dan akurasi minimumnya 20%. Dapat dilihat pada tabel bahwa untuk tiap kenaikan nilai k maka hasil akurasi pada record 50 ini semakin menurun dan mengalami kenaikan pada k=16. Sedangkan pada rasio 7:3 didapatkan akurasi maksimumnya pada k=1 yaitu 40% dan mengalami kenaikan dan penurunan tidak stabil dengan bertambahnya jumlah nilai k nya. Akurasi minimum pada rasio ini adalah 20%. Pada rasio 6:4 sendiri stabil pada kenaikan dan penurunan akurasi tiap kenaikan nilai k. Akurasi maksimumnya adalah 40% dan minimumnya 25%. Dari data pengujian record 100 sendiri pengaruh k untuk pengujian rasio 8:2 hampir memiliki kesamaan pada penyebaran akurasinya yang cenderung sama, sedangkan pada rasio 7:3 sendiri mengalami kenaikan dan penurunan akurasi yang tidak merata. Sedangkan pengaruh k pada pengujian 6:4 sendiri jauh berbeda dengan pengujian sebelumnya, akurasi maksimumnya berada pada k=13.

49
Tabel pengujian pada data set E.Coli untuk record 50
Jumlah Record Akurasi % untuk rasio 8:2 7:3 6:4 1 30 40 2 20 26.67 3 33.33 4 5 6 7 35 8 9 50 10 11 12 13 45 14 15 25

50
Pengujian Pada Record 100 Pada pengujian data bakteri rasio 8:2 untuk record 100 akurasinya mengalami penyebaran yang hampir sama dengan jumlah akurasi maksimumnya 45% pada k=1 dan k=10 dan selebihnya maksimum akurasinya adalah 40%. Sedangkan pada rasio 7:3 kenaikan akurasinya tidak stabil dengan nilai maksimumnya 43,33% pada k=5, k=8, k=9, dan k=10 selebihnya akurasi minimum sebesar 40%. Pada rasio 6:4 sendiri mengalami pemerataan akurasi dengan akurasi sebesar 30% dari data latihnya. Dari data pengujian record 100 sendiri pengaruh k untuk pengujian rasio 8:2 dan 6:4 hampir memiliki kesamaan pada penyebaran akurasinya yang cenderung sama, sedangkan pada rasio 7:3 sendiri mengalami kenaikan dan penurunan akurasi yang tidak seimbang.

51
Tabel pengujian pada data set E.Coli untuk record 100
Jumlah Record Akurasi % untuk rasio 8:2 7:3 6:4 1 45 40 30 2 3 4 5 43.33 6 7 8 9 100 10 11 12 13 14 15

52
Pengujian Pada Record 200 Pada pengujian data bakteri rasio 8:2 untuk record 200 akurasinya mengalami kenaikan akurasi yang cukup stabil dengan akurasi maksimumnya 57,5% dan akurasi maksimumnya 25%. Sedang pada rasio 7:3 akurasinya mulai memperlihatkan kenaikan dan penurunan akurasi yang cukup stabil dengan nilai maksimum akurasi sebesar 60% pada k=1 dan nilai maksimum akurasinya sebesar 23,33% . Pada rasio 6:4 sendiri akurasi maksimumnya sebesar 67,5% dan akurasi minimumnya sebesar 28,75%. Dari data pengujian record 200 sendiri pengaruh k untuk tiap pengujian mengalami kenaikan dan penurunan yang tidak stabil. Hal ini dapat dilihat pada rasio 7:3 dan 6:4 yang mengalami penurunan akurasi setelah k=5. Sedangkan pada rasio 8:2 mengalami kenaikan dan penurunan hingga k=10.

53
Tabel pengujian pada data set E.Coli untuk record 200
Jumlah Record Akurasi % untuk rasio 8:2 7:3 6:4 1 57.5 60 67.5 2 32.5 33.33 42.5 3 30 25 4 27.5 23.33 28.75 5 26.67 6 40 7 8 9 200 35 10 11 12 13 14 15

54
Pengujian Pada Record 300 Pada pengujian data bakteri rasio 8:2 untuk record 300 akurasinya mengalami kenaikan akurasi yang cukup stabil dengan akurasi maksimumnya 75% dan akurasi maksimumnya 40%. Sedang pada rasio 7:3 akurasinya mulai memperlihatkan kenaikan dan penurunan akurasi yang cukup stabil dengan nilai maksimum akurasi sebesar 72.22% pada k=1 dan nilai minimum akurasinya sebesar 36,67% . Pada rasio 6:4 sendiri akurasi maksimumnya sebesar 78,33% dan akurasi minimumnya sebesar 42,55%. Dari data pengujian record 300 sendiri pengaruh k untuk tiap pengujian hampir memiliki kesamaan pada penyebaran akurasinya. Dapat dilihat dari akurasi maksimumnya pada k=1.

55
Tabel pengujian pada data set E.Coli untuk record 300
Jumlah Record Akurasi % untuk rasio 8:2 7:3 6:4 1 75 72.22 78.33 2 55 53.33 60 3 45 51.11 58.33 4 43.33 50 5 40 36.67 42.5 6 38.89 46.67 7 8 9 300 10 11 12 13 14 15

58
Kesimpulan Algoritma Modified K-Nearest Neighbor (MKNN) dapat diimplementasikan untuk klasifikasi dataset Bakteri E.Coli. Metode ini digunakan menentukan pembobotan untuk menentukan tiap kelas pada data uji. Dengan melakukan perbandingan penghitungan jarak euclidean antar record dan validitasnya. Pada perhitungan validitasnya juga diinputkan nilai k dengan perhitungan k maksimalnya sebanyak jumlah data latih-1. Tingkat akurasi pada metode MKNN dipengaruhi oleh beberapa parameter, sebagai berikut: Nilai k yang telalu besar menghasilkan akurasi yang kurang baik hal ini dikarena berpengaruh terjadinya noise. Meningkatnya jumlah data latih turut disertai dengan kenaikan nilai akurasi, karena dengan semakin banyaknya data latih maka kemungkinan semakin banyaknya jarak record yang mendekati kelas data prediksi.
 dapat diimplementasikan untuk klasifikasi dataset Bakteri E.Coli. Metode ini digunakan menentukan pembobotan untuk menentukan tiap kelas pada data uji. Dengan melakukan perbandingan penghitungan jarak euclidean antar record dan validitasnya. Pada perhitungan validitasnya juga diinputkan nilai k dengan perhitungan k maksimalnya sebanyak jumlah data latih-1. Tingkat akurasi pada metode MKNN dipengaruhi oleh beberapa parameter, sebagai berikut: Nilai k yang telalu besar menghasilkan akurasi yang kurang baik hal ini dikarena berpengaruh terjadinya noise. Meningkatnya jumlah data latih turut disertai dengan kenaikan nilai akurasi, karena dengan semakin banyaknya data latih maka kemungkinan semakin banyaknya jarak record yang mendekati kelas data prediksi.")
59
DAFTAR PUSTAKA Dunham, M.H Data mining introductory and advanced topics. New Jersey: Prentice Hall. Dataset Bakteri E-Coli. Protein Localization Sites.. Kenta Nakai Institue of Molecular and Cellular Biology Osaka, University 1-3 Yamada-oka.Osaka. Donald E. Knuth The Art of Computer Programming (TAOCP). Computer Science Department Stanford University.California Hamid Parvin, Hosein Alizadeh and Behrouz Minaei-Bidgoli MKNN: Modified K-Nearest Neighbor.Proceedings of the World Congress on Engineering and Computer Science.San Francisco. Hand, David, dkk Principles of Data Mining. MIT press. Cambridge. Kantardzic, Mehmed Data Mining :Concepts, Models, Methods and Algorithm. John Wiley & Sons. New York. Kenta Nakai A Probabilistic Classification System for Predicting the Cellular Localization Sites of Proteins. Institute of Molecular and Cellular Biology Osaka University, 1-3 Yamada-oka, Suita 565. Kusnawi, PENGANTAR SOLUSI DATA MINING. Seminar Nasional Teknologi 2007 (SNT 2007).Yogyakarta. Moertini, Veronika S Data Mining Sebagai Solusi Bisnis. Tanggal akses : 19 April 2010. Pramudiono, Iko Pengantar Data Mining: Menambang Permata Pengetahuan di Gunung Data. Ilmu Komputer.Com. Sarkar, Manish dan Leong, Tze-Yun Application of K-Nearest Neighbors Algorithm on Breast Cancer Diagnosis Problem. The National University of Singapore. Singapore. Tan et al Data mining. pdf/ s1teknikinformatika09 /.../ BAB%20II.pdf. Diakses tanggal: 25 april 2011. Turban, 2005, Decision Support Systems and Intelligent Systems (Sistem Pendukung Keputusan dan Sistem Cerdas) jilid 1., Andi Offset : Yogyakarta. Yang Liu,a Xinmiao Fu,a Jia Shen,b Hui Zhang,b Weizhe Hong,a and Zengyi Changa,b,* Periplasmic proteins of Escherichia coli are highly resistant to aggregation: reappraisal for roles of molecular chaperones in periplasm. Department of Biological Science and Biotechnology, Tsinghua University, Beijing , PR China and Department of Biochemistry and Molecular Biology, College of Life Science, Peking University, Beijing.
. Computer Science Department Stanford University.California. Hamid Parvin, Hosein Alizadeh and Behrouz Minaei-Bidgoli MKNN: Modified K-Nearest Neighbor.Proceedings of the World Congress on Engineering and Computer Science.San Francisco. Hand, David, dkk Principles of Data Mining. MIT press. Cambridge. Kantardzic, Mehmed Data Mining :Concepts, Models, Methods and Algorithm. John Wiley & Sons. New York. Kenta Nakai A Probabilistic Classification System for Predicting the Cellular Localization Sites of Proteins. Institute of Molecular and Cellular Biology Osaka University, 1-3 Yamada-oka, Suita 565. Kusnawi, PENGANTAR SOLUSI DATA MINING. Seminar Nasional Teknologi 2007 (SNT 2007).Yogyakarta. Moertini, Veronika S Data Mining Sebagai Solusi Bisnis. Tanggal akses : 19 April Pramudiono, Iko Pengantar Data Mining: Menambang Permata Pengetahuan di Gunung Data. Ilmu Komputer.Com. Sarkar, Manish dan Leong, Tze-Yun Application of K-Nearest Neighbors Algorithm on Breast Cancer Diagnosis Problem. The National University of Singapore. Singapore. Tan et al Data mining. pdf/ s1teknikinformatika09 /.../ BAB%20II.pdf. Diakses tanggal: 25 april Turban, 2005, Decision Support Systems and Intelligent Systems (Sistem Pendukung Keputusan dan Sistem Cerdas) jilid 1., Andi Offset : Yogyakarta. Yang Liu,a Xinmiao Fu,a Jia Shen,b Hui Zhang,b Weizhe Hong,a and Zengyi Changa,b,* Periplasmic proteins of Escherichia coli are highly resistant to aggregation: reappraisal for roles of molecular chaperones in periplasm. Department of Biological Science and Biotechnology, Tsinghua University, Beijing , PR China and Department of Biochemistry and Molecular Biology, College of Life Science, Peking University, Beijing.")
Presentasi serupa






 JAVA Class, Java Interface Encapsulation.>")




.>")




 Minggu III - 40 menit>")

>")
