Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Ratri Enggar Pawening http://infokampuskoe.wordpress.com Materi 4 I NFORMATION R ETRIEVAL

2
Overview Dalam korpus yang besar, sebuah boolean query mampu mengembalikan hasil yang besar pula. Andaikan hasil boolean retrieval mengembalikan 10.000 dokumen, manakah yang benar-benar cocok untuk kita? Bagaimana pula dengan user yang kurang memiliki pengetahuan yang bagus dalam boolean query?

3
Overview Permasalahan: Kita butuh mengurutkan dokumen hasil retrieval disesuaikan dengan query yang kita masukkan. Pemecahan: Pemberian score/nilai untuk setiap dokumen dalam korpus terhadap query kita. (untuk dirangkingkan)
.")
4
Scoring Yang sudah kita pelajari tentang scoring/nilai adalah score 1 untuk dokumen yang relevan dengan query dan score 0 untuk dokumen yang tidak relevan. Kita akan masuk ke tahap berikutnya: – dokumen yang memiliki token query lebih banyak didalamnya, akan memiliki score yang lebih tinggi. – query berupa free text (tanpa operator)
.")
5
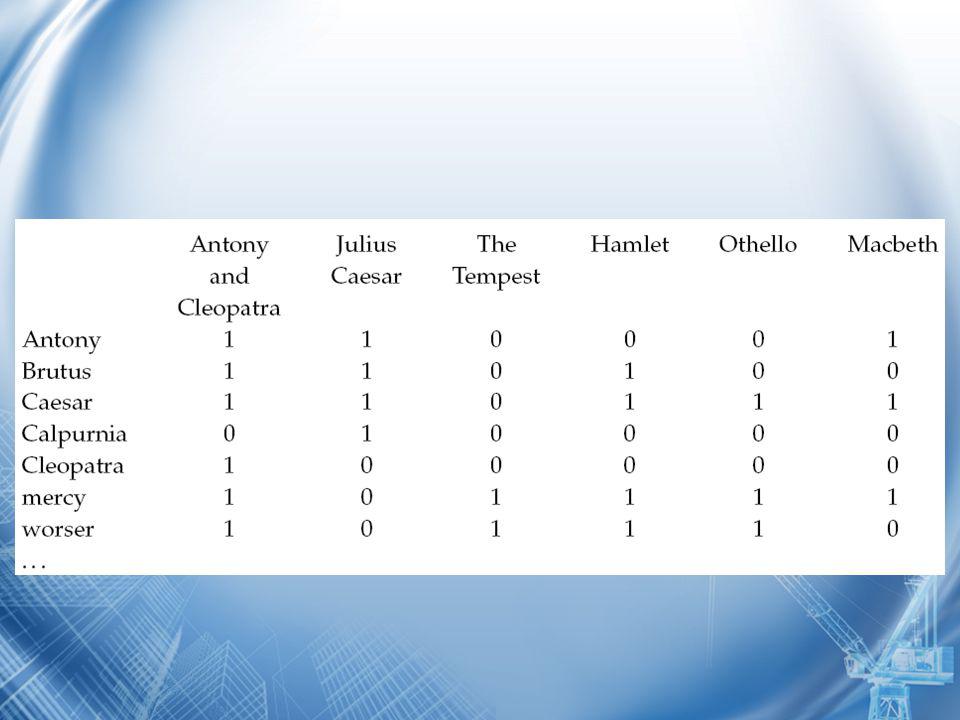
Overlap Measure [1] Ide perangkingan yang sederhana adalah overlap measure (Manning, 2008) Sebagai contoh, kita lihat kasus berikut.
![Overlap Measure [1] Ide perangkingan yang sederhana adalah overlap measure (Manning, 2008) Sebagai contoh, kita lihat kasus berikut.](http://images.slideplayer.info/10/2752101/slides/slide_5.jpg "Overlap Measure [1] Ide perangkingan yang sederhana adalah overlap measure (Manning, 2008) Sebagai contoh, kita lihat kasus berikut.")
7
Overlap Measure [2] Misalkan contoh query-nya adalah: “Brutus Mercy Antony” Maka dokumen “Antony and Cleopatra” memiliki score 3 (Karena ketiga token dalam query dimiliki semua oleh dokumen tersebut). Dokumen “Julius Caesar” dan “Macbeth” memiliki score 2. Nah, dengan begitu, dokumen “Antony and Cleopatra” menempati rangking pertama.
![Overlap Measure [2] Misalkan contoh query-nya adalah: Brutus Mercy Antony Maka dokumen Antony and Cleopatra memiliki score 3 (Karena ketiga token dalam query dimiliki semua oleh dokumen tersebut).](http://images.slideplayer.info/10/2752101/slides/slide_7.jpg "Dokumen Julius Caesar dan Macbeth memiliki score 2. Nah, dengan begitu, dokumen Antony and Cleopatra menempati rangking pertama..")
8
Overlap Measure [3] Tapi, apakah masih ditemui kelemahan dari penghitungan overlap measure? Bagaimana kalau query hanya satu kata/token saja? Overlap measure tidak: – Mempertimbangkan jumlah suatu token dalam suatu dokumen. – Mempertimbangkan scarcity dari tiap token – Tidak memperhitungkan jumlah korpus dan jumlah token dalam query.
![Overlap Measure [3] Tapi, apakah masih ditemui kelemahan dari penghitungan overlap measure.](http://images.slideplayer.info/10/2752101/slides/slide_8.jpg "Bagaimana kalau query hanya satu kata/token saja. Overlap measure tidak: – Mempertimbangkan jumlah suatu token dalam suatu dokumen. – Mempertimbangkan scarcity dari tiap token – Tidak memperhitungkan jumlah korpus dan jumlah token dalam query..")
9
Overlap Measure [4] Ide selanjutnya adalah menemukan metode scoring yang lebih baik. Scoring juga tetap dapat dilakukan meski hanya ada satu token dalam query. Dokumen akan semakin relevan jika memuat token yang semakin banyak. Ini semua menuju ke ide berikutnya term weighting.
![Overlap Measure [4] Ide selanjutnya adalah menemukan metode scoring yang lebih baik.](http://images.slideplayer.info/10/2752101/slides/slide_9.jpg "Scoring juga tetap dapat dilakukan meski hanya ada satu token dalam query. Dokumen akan semakin relevan jika memuat token yang semakin banyak. Ini semua menuju ke ide berikutnya term weighting..")
10
Term Frequency Untuk bisa mendapat score tadi, pertama-tama kita perlu memberikan bobot tiap token dalam tiap dokumen. Ex: Bobot token ditentukan dari jumlah kemunculan token tersebut di dalam dokumen. ( term frequency – tf ) term frequency dinotasikan dengan tf (t,d), dimana t token, dan d dokumen
 term frequency dinotasikan dengan tf (t,d), dimana t token, dan d dokumen.")
11
Document Frequency DOCUMENT FREQUENCY (df), defined to be the number of documents in the collection that contain a term t.
, defined to be the number of documents in the collection that contain a term t.")
12
Components N jml dokumen tf (t,d) df idf inverse df + 1
 df idf inverse df + 1")
13
tf-idf weighting df t = jumlah token pada dokumen i i = dokumen ke-… j & k = token ke-…

14
Referensi http://come2dz.wordpress.com/

Presentasi serupa
 IX. 1.>")













>")


>")
>")
