Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Artificial Neural Network (Back-Propagation Neural Network)
Yusuf Hendrawan, STP., M.App.Life Sc., Ph.D

2
Neurons Biological Artificial
Artificial

3
A typical AI agent

4
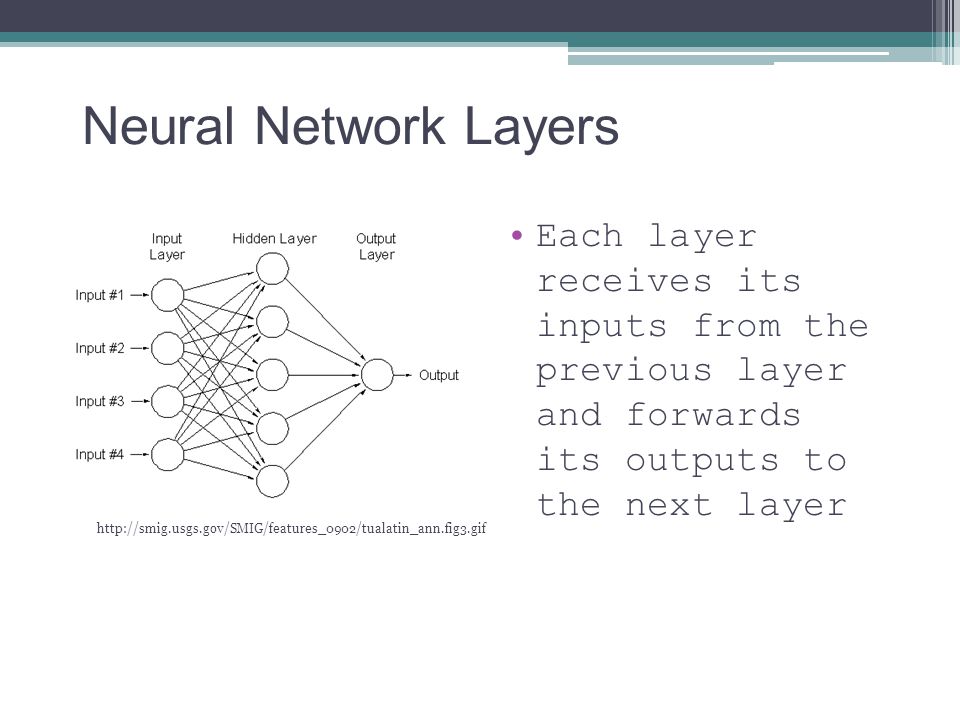
Neural Network Layers Each layer receives its inputs from the previous layer and forwards its outputs to the next layer
5
Multilayer feed forward network
It contains one or more hidden layers (hidden neurons). “Hidden” refers to the part of the neural network is not seen directly from either input or output of the network . The function of hidden neuron is to intervene between input and output. By adding one or more hidden layers, the network is able to extract higher- order statistics from input
. Hidden refers to the part of the neural network is not seen directly from either input or output of the network . The function of hidden neuron is to intervene between input and output. By adding one or more hidden layers, the network is able to extract higher- order statistics from input.")
6
Neural Network Learning
Back-Propagation Algorithm: function BACK-PROP-LEARNING(examples, network) returns a neural network inputs: examples, a set of examples, each with input vector x and output vector y network, a multilayer network with L layers, weights Wj,i , activation function g repeat for each e in examples do for each node j in the input layer do aj ‰ xj[e] for l = 2 to M do ini ‰ åj Wj,i aj ai ‰ g(ini) for each node i in the output layer do Dj ‰ g’(inj) åi Wji Di for l = M – 1 to 1 do for each node j in layer l do Dj ‰ g’(inj) åi Wj,i Di for each node i in layer l + 1 do Wj,i ‰ Wj,i + a x aj x Di until some stopping criterion is satisfied return NEURAL-NET-HYPOTHESIS(network) [Russell, Norvig] Fig Pg. 746
 returns a neural network. inputs: examples, a set of examples, each with input vector x and output vector y. network, a multilayer network with L layers, weights Wj,i , activation function g. repeat. for each e in examples do. for each node j in the input layer do aj ‰ xj[e] for l = 2 to M do. ini ‰ åj Wj,i aj. ai ‰ g(ini) for each node i in the output layer do. Dj ‰ g’(inj) åi Wji Di. for l = M – 1 to 1 do. for each node j in layer l do. Dj ‰ g’(inj) åi Wj,i Di. for each node i in layer l + 1 do. Wj,i ‰ Wj,i + a x aj x Di. until some stopping criterion is satisfied. return NEURAL-NET-HYPOTHESIS(network) [Russell, Norvig] Fig Pg")
7
Back-Propagation Illustration
ARTIFICIAL NEURAL NETWORKS Colin Fahey's Guide (Book CD)
")
8
Input (X) Hidden Output (Y) Z1 X1 Z2 Y Z3 X2 Z4 Vo Wo
 Hidden Output (Y) Z1 X1 Z2 Y Z3 X2 Z4 Vo Wo")
9
Input (X) Output / Target (T) X1 X2 0.3 0.4 0.5 0.6 0.2 0.7 T 0.1 0.8 0.4 0.5 Jumlah Neuron pada Input Layer 2 Jumlah Neuron pada Hidden Layer 4 Jumlah Neuron pada Output Layer 1 Learning rate (α) 0.1 Momentum (m) 0.9 Target Error 0.01 Maximum Iteration 1000
 0.1. Momentum (m) 0.9. Target Error Maximum Iteration")
10
Bobot Awal Input ke Hidden
Bias ke Hidden V11 = 0.75 V21 = 0.35 V12 = 0.54 V22 = 0.64 V13 = 0.44 V23 = 0.05 V14 = 0.32 V24 = 0.81 Vo11 = 0.07 Vo21 = 0.12 Vo12 = 0.91 Vo22 = 0.23 Vo13 = 0.45 Vo23 = 0.85 Vo14 = 0.25 Vo24 = 0.09 Bobot Awal Hidden ke Output Bias ke Output W1 = 0.04 W2 = 0.95 W3 = 0.33 W4 = 0.17 Wo1 = 0.66 Wo2 = 0.56 Wo3 = 0.73 Wo4 = 0.01

11
Menghitung Zin & Z dari input ke hidden
Zin(1) = (X1 * V11) + (X2 * V21) = (0.3 * 0.75) + (0.4 * 0.35) = 0.302 Zin(2) = (X1 * V12) + (X2 * V22) = (0.3 * 0.54) + (0.4 * 0.64) = 0.418 Zin(3) = (X1 * V13) + (X2 * V23) = (0.3 * 0.44) + (0.4 * 0.05) = 0.152 Zin(4) = (X1 * V14) + (X2 * V24) = (0.3 * 0.32) + (0.4 * 0.81) = 0.42
 = (X1 * V11) + (X2 * V21) = (0.3 * 0.75) + (0.4 * 0.35) = Zin(2) = (X1 * V12) + (X2 * V22) = (0.3 * 0.54) + (0.4 * 0.64) = Zin(3) = (X1 * V13) + (X2 * V23) = (0.3 * 0.44) + (0.4 * 0.05) = Zin(4) = (X1 * V14) + (X2 * V24) = (0.3 * 0.32) + (0.4 * 0.81) =")
12
Menghitung Yin & Y dari hidden ke output
Yin = (Z(1) * W1) + (Z(2) * W2) + (Z(3) * W3) + (Z(4) * W4) = (0.57 * 0.04) + (0.603 * 0.95) + (0.538 * 0.33) + (0.603 * 0.17) = 0.876 Menghitung dev antara Y dengan output nyata dev = (T - Y) * Y * (1 - Y) = (0.1 – 0.706) * * (1 – 0.706) = Menghitung selisih selisih = T - Y=
 * W1) + (Z(2) * W2) + (Z(3) * W3) + (Z(4) * W4) = (0.57 * 0.04) + (0.603 * 0.95) + (0.538 * 0.33) + (0.603 * 0.17) = Menghitung dev antara Y dengan output nyata. dev = (T - Y) * Y * (1 - Y) = (0.1 – 0.706) * * (1 – 0.706) = Menghitung selisih. selisih = T - Y=")
13
Back-Propagation Menghitung din dari output ke hidden din(1) = (dev * W1) = ( * 0.04) = din(2) = (dev * W2) = ( * 0.95) = din(3) = (dev * W3) = ( * 0.33) = din(4) = (dev * W4) = ( * 0.17) = Menghitung d d (1) = (din(1) * Z(1) * (1 - Z(1) ) = ( * * (1 – 0.575) = d (2) = (din(2) * Z(2) * (1 - Z(2) ) = ( * * (1 – 0.603) = d (3) = (din(3) * Z(3) * (1 - Z(3) ) = ( * * (1 – 0.538) = d (4) = (din(4) * Z(4) * (1 - Z(4) ) = ( * * (1 – 0.603) =
 = (dev * W2) = ( * 0.95) = din(3) = (dev * W3) = ( * 0.33) = din(4) = (dev * W4) = ( * 0.17) = Menghitung d. d (1) = (din(1) * Z(1) * (1 - Z(1) ) = ( * * (1 – 0.575) = d (2) = (din(2) * Z(2) * (1 - Z(2) ) = ( * * (1 – 0.603) = d (3) = (din(3) * Z(3) * (1 - Z(3) ) = ( * * (1 – 0.538) = d (4) = (din(4) * Z(4) * (1 - Z(4) ) = ( * * (1 – 0.603) =")
14
Mengkoreksi bobot (W) dan bias (Wo)
W1 = W1 + (α * dev * Z(1) ) + (m * Wo(1)) = (0.1 * * 0.575) + (0.9 * 0.66) = 0.627 W2 = W2 + (α * dev * Z(2) ) + (m * Wo(2)) = (0.1 * * 0.603) + (0.9 * 0.56) = 1.45 W3 = W3 + (α * dev * Z(3) ) + (m * Wo(3)) = (0.1 * * 0.538) + (0.9 * 0.73) = 0.98 W4 = W4 + (α * dev * Z(4) ) + (m * Wo(4)) = (0.1 * * 0.603) + (0.9 * 0.01) = 0.171 Wo1 = (α * Z(1) ) + (m * Wo(1)) = (0.1 * 0.575) + (0.9 * 0.66) = 0.65 Wo2 = (α * Z(2) ) + (m * Wo(2)) = (0.1 * 0.603) + (0.9 * 0.56) = 0.564 Wo3 = (α * Z(3) ) + (m * Wo(3)) = (0.1 * 0.538) + (0.9 * 0.73) = 0.71 Wo4 = (α * Z(4) ) + (m * Wo(4)) = (0.1 * 0.603) + (0.9 * 0.01) =
 ) + (m * Wo(1)) = (0.1 * * 0.575) + (0.9 * 0.66) = W2 = W2 + (α * dev * Z(2) ) + (m * Wo(2)) = (0.1 * * 0.603) + (0.9 * 0.56) = W3 = W3 + (α * dev * Z(3) ) + (m * Wo(3)) = (0.1 * * 0.538) + (0.9 * 0.73) = W4 = W4 + (α * dev * Z(4) ) + (m * Wo(4)) = (0.1 * * 0.603) + (0.9 * 0.01) = Wo1 = (α * Z(1) ) + (m * Wo(1)) = (0.1 * 0.575) + (0.9 * 0.66) = Wo2 = (α * Z(2) ) + (m * Wo(2)) = (0.1 * 0.603) + (0.9 * 0.56) = Wo3 = (α * Z(3) ) + (m * Wo(3)) = (0.1 * 0.538) + (0.9 * 0.73) = Wo4 = (α * Z(4) ) + (m * Wo(4)) = (0.1 * 0.603) + (0.9 * 0.01) =")
15
Mengkoreksi bobot (V) dan bias (Vo)
V11 = V11 + (α * d (1) * X1 ) + (m * Vo(11)) = (0.1 * * 0.3) + (0.9 * 0.07) = V12 = V12 + (α * d (2) * X1 ) + (m * Vo(12)) = (0.1 * * 0.3) + (0.9 * 0.91) = V13 = V13 + (α * d (3) * X1 ) + (m * Vo(13)) = (0.1 * * 0.3) + (0.9 * 0.45) = V14 = V14 + (α * d (4) * X1 ) + (m * Vo(14)) = (0.1 * * 0.3) + (0.9 * 0.25) = V21 = V21 + (α * d (1) * X2 ) + (m * Vo(21)) = (0.1 * * 0.4) + (0.9 * 0.12) = V22 = V22 + (α * d (2) * X2 ) + (m * Vo(22)) = (0.1 * * 0.4) + (0.9 * 0.23) = V23 = V23 + (α * d (3) * X2 ) + (m * Vo(23)) = (0.1 * * 0.4) + (0.9 * 0.85) = V24 = V24 + (α * d (4) * X2 ) + (m * Vo(24)) = (0.1 * * 0.4) + (0.9 * 0.09) =
 * X1 ) + (m * Vo(11)) = (0.1 * * 0.3) + (0.9 * 0.07) = V12 = V12 + (α * d (2) * X1 ) + (m * Vo(12)) = (0.1 * * 0.3) + (0.9 * 0.91) = V13 = V13 + (α * d (3) * X1 ) + (m * Vo(13)) = (0.1 * * 0.3) + (0.9 * 0.45) = V14 = V14 + (α * d (4) * X1 ) + (m * Vo(14)) = (0.1 * * 0.3) + (0.9 * 0.25) = V21 = V21 + (α * d (1) * X2 ) + (m * Vo(21)) = (0.1 * * 0.4) + (0.9 * 0.12) = V22 = V22 + (α * d (2) * X2 ) + (m * Vo(22)) = (0.1 * * 0.4) + (0.9 * 0.23) = V23 = V23 + (α * d (3) * X2 ) + (m * Vo(23)) = (0.1 * * 0.4) + (0.9 * 0.85) = V24 = V24 + (α * d (4) * X2 ) + (m * Vo(24)) = (0.1 * * 0.4) + (0.9 * 0.09) =")
16
Mengkoreksi bobot (V) dan bias (Vo)
Vo11 = (α * d (1) * X1 ) + (m * Vo11) = (0.1 * *0.3)+(0.9*0.07) = Vo12 = (α * d (2) * X1 ) + (m * Vo12) = (0.1 * *0.3)+(0.9*0.91) = Vo13 = (α * d (3) * X1 ) + (m * Vo13) = (0.1 * *0.3)+(0.9*0.45) = Vo14 = (α * d (4) * X1 ) + (m * Vo14) = (0.1 * *0.3)+(0.9*0.25) = Vo21 = (α * d (1) * X2 ) + (m * Vo21) = (0.1 * *0.4)+(0.9*0.12) = Vo22 = (α * d (2) * X2 ) + (m * Vo22) = (0.1 * *0.4)+(0.9*0.23) = Vo23 = (α * d (3) * X2 ) + (m * Vo23) = (0.1 * *0.4)+(0.9*0.85) = Vo24 = (α * d (4) * X2 ) + (m * Vo24) = (0.1 * *0.4)+(0.9*0.09) =
 * X1 ) + (m * Vo11) = (0.1 * *0.3)+(0.9*0.07) = Vo12 = (α * d (2) * X1 ) + (m * Vo12) = (0.1 * *0.3)+(0.9*0.91) = Vo13 = (α * d (3) * X1 ) + (m * Vo13) = (0.1 * *0.3)+(0.9*0.45) = Vo14 = (α * d (4) * X1 ) + (m * Vo14) = (0.1 * *0.3)+(0.9*0.25) = Vo21 = (α * d (1) * X2 ) + (m * Vo21) = (0.1 * *0.4)+(0.9*0.12) = Vo22 = (α * d (2) * X2 ) + (m * Vo22) = (0.1 * *0.4)+(0.9*0.23) = Vo23 = (α * d (3) * X2 ) + (m * Vo23) = (0.1 * *0.4)+(0.9*0.85) = Vo24 = (α * d (4) * X2 ) + (m * Vo24) = (0.1 * *0.4)+(0.9*0.09) =")
Presentasi serupa













 Informatics Eng. Dept. – IT Telkom.>")
>")



 stiki. ac>")
