Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Dr. Yekti Asih Purwestri, M.Si.
TRANSLASI Dr. Yekti Asih Purwestri, M.Si.

2
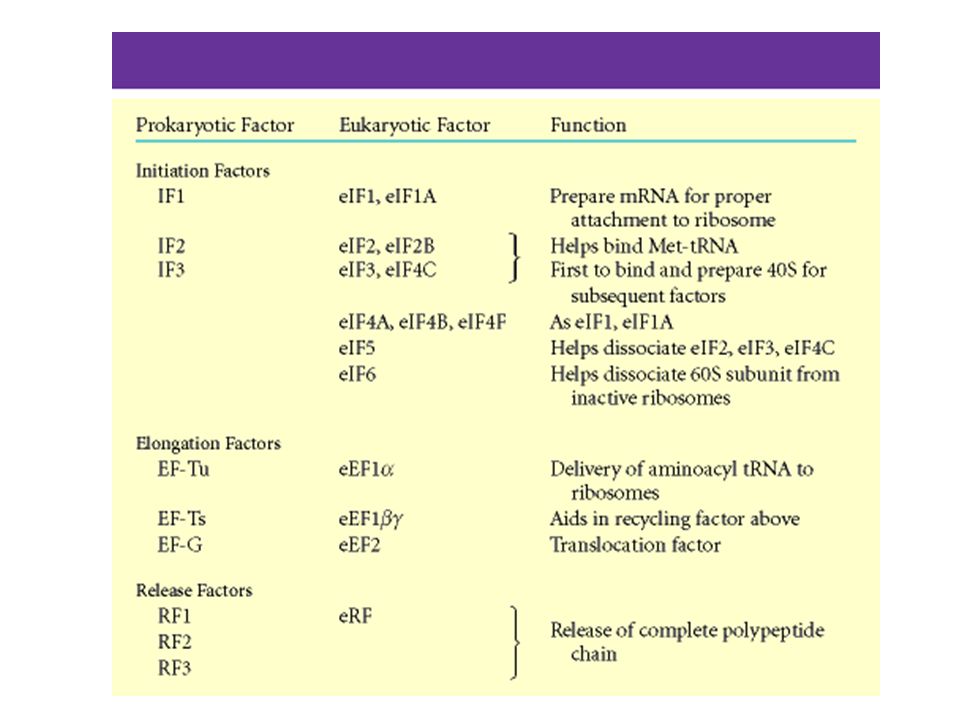
Asam amino dan ikatan peptida
Ada 20 asam amino yang dikode oleh DNA Semua mempunya gugus amino group (-NH2) dan gugus karboksil (-COOH). Terikat pada C sentralnya adalah rantai samping R. Gugus asam pada asam mino terikat pada gugus amino pada asam amino berikutnya, membentuk ikatan peptida
 dan gugus karboksil (-COOH). Terikat pada C sentralnya adalah rantai samping R. Gugus asam pada asam mino terikat pada gugus amino pada asam amino berikutnya, membentuk ikatan peptida.")
4
Dari gen menjadi protein
DNA Transcription mRNA Translation Sequence of a.a Primary structure of protein

5
Translasi merupakan proses pembacaan kodon dan menggabungkan asam amino melalui ikatan peptida
Komponen proses translasi mRNA tersusun atas kode genetik Ribosom tRNA bersama dengan asam amino Enzim2

6
Tahap proses translasi
Inisiasi Elongasi Terminasi Inisiasi Aktivasi asam amino untuk bergabung membentuk protein

7
Activation of amino acids for incorporation into proteins.

8
Genetic code Three nucleotides - codon - code for one amino acid in a protein
Codon sequence of three nucleotides in a mRNA that specifies the incorporation of a specific amino acid into a protein. The relationship between codons and the amino acids they code for is called the genetic code.

9
Not all codons are used with equal frequency.
There is a considerable amount of variation in the patterns of codon usage between different organisms.

10
Kode Genetik Masing2 kelompok yang terdiri dari 3 nukleotida pada mRNA disebut kodon. Karena 4 basa , kodon yang terbentuk adalah 43 = 64, yang harus mengkode 20 asam amino yang berbeda. Lebih dari satu kodon digunakan untuk banyak asam amino : kode genetik bersifat “degenerate”. Hal ini berarti bahwa tidak mungkin mengambil sekuen protein dan menterjemahkannya ke dalam sekuen basa gen tersebut. Dalam banyak hal, basa ketiga dari kodon (the wobble base) dapat diubah tanpa mengubah asam aminonya. AUG digunakan sebagai start kodon. Awal translasi semua protein adalah metionin, meskipun sering dihilangkan setelah translasi. Ada juga internal metionin yang dikode oleh kodon AUG yang sama. Terdapat 3 stop kodon, yang disebut “nonsense” kodon. Protein berakhir dengan stop kodon yang tidak mengkode suatu asam amino
 dapat diubah tanpa mengubah asam aminonya. AUG digunakan sebagai start kodon. Awal translasi semua protein adalah metionin, meskipun sering dihilangkan setelah translasi. Ada juga internal metionin yang dikode oleh kodon AUG yang sama. Terdapat 3 stop kodon, yang disebut nonsense kodon. Protein berakhir dengan stop kodon yang tidak mengkode suatu asam amino.")
11
Kode Genetik Kebanyakan kode genetik bersifat universal. Digunakan baik pada prokariot maupun eukariot. Namun, beberapa varian dijumpai, terutama pada mitokondria yang hanya memiliki sedikit gen. Contoh: CUA umumnya mengkode, tetapi pada mitokondria yeast mengkode treonin. AGA umumnya mengkode arginin, tetapi pada mitokondria manusia dan Drosophila merupakan stop kodon.

12
Wobble Hypothesis

13
Relationships of DNA to mRNA to polypeptide chain.

14
Translation is accomplished by the anticodon loop of tRNA forming base pairs with the codon of mRNA in ribosomes

15
Transfer RNA (tRNA) composed of a nucleic acid and
a specific amino acid provide the link between the nucleic acid sequence of mRNA and the amino acid sequence it codes for. An anticodon a sequence of 3 nucleotides in a tRNA that is complementary to a codon of mRNA Structure of tRNAs

16
Transfer RNA Transfer RNA molecules are short RNAs that fold into a characteristic cloverleaf pattern. Some of the nucleotides are modified to become things like pseudouridine and ribothymidine. Each tRNA has 3 bases that make up the anticodon. These bases pair with the 3 bases of the codon on mRNA during translation. Each tRNA has its corresponding amino acid attached to the 3’ end. A set of enzymes, the “aminoacyl tRNA synthetases”, are used to “charge” the tRNA with the proper amino acid. Some tRNAs can pair with more than one codon. The third base of the anticodon is called the “wobble position”, and it can form base pairs with several different nucleotides.

17
Only tRNAfMet is accepted to form the initiation complex.
All further charged tRNAs require fully assembled (i.e., 70S) ribosomes The Shine-Dalgarno sequence help ribosomes and mRNA aligns correctly for the start of translation. Ribosome consists of A site aminoacyl P site peptidyl - E site exit Two initiation factors (IF1 &IF3) bind to a 70S ribosome. promote the dissociation of 70S ribosomes into free 30S and 50S subunits. mRNA and IF2, which carries GTP the charged tRNA bind to a free 30S subunit. After these have all bound, the 30S initiation complex is complete.
 ribosomes. The Shine-Dalgarno sequence help ribosomes and mRNA aligns correctly for the start of translation. Ribosome consists of. A site aminoacyl. P site peptidyl. - E site exit. Two initiation factors (IF1 &IF3) bind to a 70S ribosome. promote the dissociation of 70S ribosomes into free 30S and 50S subunits. mRNA and IF2, which carries. GTP. the charged tRNA. bind to a free 30S subunit. After these have all bound, the 30S initiation complex is complete.")
18
Peptide bond formation
catalyzed by an enzyme complex called peptidyltransferase Peptidyltransferase consists of some ribosomal proteins and the ribosomal RNA acts as a ribozyme. The process is repeated until a termination signal is reached.

19
Termination of translation occurs when one of the stop codons (UAA, UAG, or UGA) appears in the A site of the ribosome. No tRNAs correspond to those sequences, so no tRNA is bound during termination. Proteins called release factors participate in termination

21
Posttranslational Processing of Proteins
Folding Amino acid modification (some proteins) Proteolytic cleavage FOLDING Before a newly translated polypeptide can be active, it must be folded into the proper 3-D structure and it may have to associate with other subunits.
 Proteolytic cleavage. FOLDING. Before a newly translated polypeptide can be active, it must be folded into the proper 3-D structure and it may have to associate with other subunits.")
22
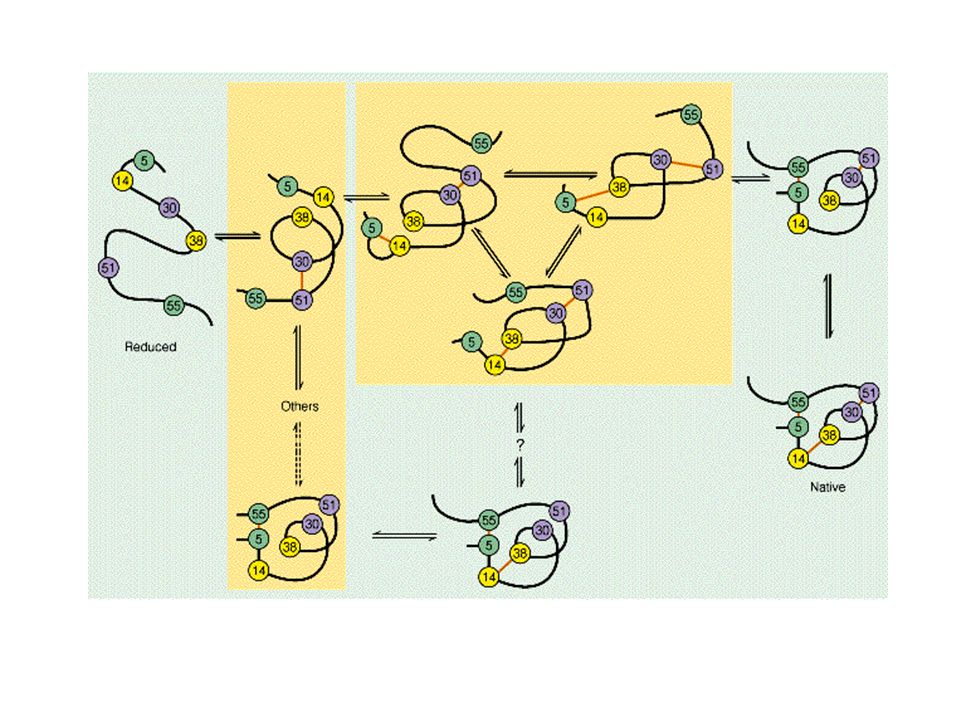
Enzymes/protein involve in folding process
1. Cis-trans isomerase for proline Proline is the only amino acid in proteins forms peptide bonds in which the trans isomer is only slightly favored (4 to 1 versus 1000 to 1 for other residues). Thus, during folding, there is a significant chance that the wrong proline isomer will form first. Cells have enzymes to catalyze the cis-trans isomerization necessary to speed correct folding. 2. disulfide bond making enzymes 3. Chaperonins (molecular chaperones) a protein to help keep it properly folded and non-aggregated.
. Thus, during folding, there is a significant chance that the wrong proline isomer will form first. Cells have enzymes to catalyze the cis-trans isomerization necessary to speed correct folding. 2. disulfide bond making enzymes. 3. Chaperonins (molecular chaperones) a protein to help keep it properly folded and non-aggregated.")
24
Insulin is synthesized single polypeptide preproinsulin
has leader sequence (help it be transported through the cell membrane) Specific protease cleaves leader sequence proinsulin. Proinsulin folds into specific 3D structure and disulfide bonds form Another protease cuts molecule insulin 2 polypeptide chains
 Specific protease cleaves leader sequence proinsulin. Proinsulin folds into specific 3D structure and disulfide bonds form. Another protease cuts molecule insulin 2 polypeptide chains.")
25
Chaperones Function to keep a newly synthesized protein from either improperly folding or aggregating After synthesized, protein needs to fold in order to have its function The folding pattern is dictated in the amino acid sequence of the protein. Some proteins capable to fold into its proper 3-D structure by itself without any help of other molecules Some proteins need chaperones to fold (example in human hsp 70) Some proteins need bigger protein chaperonins to be able to fold correctly. Chaperonins a polysubunit protein form “a cage” like shape give micro environment to protein
 Some proteins need bigger protein chaperonins to be able to fold correctly. Chaperonins a polysubunit protein form a cage like shape give micro environment to protein.")
26
Protein Targeting Nascent proteins contain signal sequence determine their ultimate destination. Bacteria newly synthesized protein can: stay in the cytosol, send to the plasma membran, outer membrane, periplasmic, extracellular. Eukaryotes can direct proteins to internal sites lysosomes, mitochondria etc. Nascent polypeptide E.R and glycosylated golgi complex and modified sorted for delivery to lysosomes, secretory vesicle and plasma membrane.

27
Translocation The protein to be translocated (called a pro-protein) is complexed in the cytoplasm with a chaperone The complex keeps the protein from folding prematurely, which would prevent it from passing through the secretory porean ATPase that helps drive the translocation after the pro-protein is translocated, the leader peptide is cleaved by a membrane-bound protease and the protein can fold into its active 3-d form.

28
Signal recognition particle (SRP) detects signal sequence and brings ribosome to the ER membrane
 detects signal sequence and brings ribosome to the ER membrane")
29
Most mitochondrial proteins are synthesized in the cytosol and imported into the organelle

31
Initiation of Translation
In prokaryotes, ribosomes bind to specific translation initiation sites. There can be several different initiation sites on a messenger RNA: a prokaryotic mRNA can code for several different proteins. Translation begins at an AUG codon, or sometimes a GUG. The modified amino acid N-formyl methionine is always the first amino acid of the new polypeptide. In eukaryotes, ribosomes bind to the 5’ cap, then move down the mRNA until they reach the first AUG, the codon for methionine. Translation starts from this point. Eukaryotic mRNAs code for only a single gene. (Although there are a few exceptions, mainly among the eukaryotic viruses). Note that translation does not start at the first base of the mRNA. There is an untranslated region at the beginning of the mRNA, the 5’ untranslated region (5’ UTR).
. Note that translation does not start at the first base of the mRNA. There is an untranslated region at the beginning of the mRNA, the 5’ untranslated region (5’ UTR).")
32
More Initiation The initiation process involves first joining the mRNA, the initiator methionine-tRNA, and the small ribosomal subunit. Several “initiation factors”--additional proteins--are also involved. The large ribosomal subunit then joins the complex.

33
Elongation The ribosome has 2 sites for tRNAs, called P and A. The initial tRNA with attached amino acid is in the P site. A new tRNA, corresponding to the next codon on the mRNA, binds to the A site. The ribosome catalyzes a transfer of the amino acid from the P site onto the amino acid at the A site, forming a new peptide bond. The ribosome then moves down one codon. The now-empty tRNA at the P site is displaced off the ribosome, and the tRNA that has the growing peptide chain on it is moved from the A site to the P site. The process is then repeated: the tRNA at the P site holds the peptide chain, and a new tRNA binds to the A site. the peptide chain is transferred onto the amino acid attached to the A site tRNA. the ribosome moves down one codon, displacing the empty P site tRNA and moving the tRNA with the peptide chain from the A site to the P site.

34
Elongation

35
Termination Three codons are called “stop codons”. They code for no amino acid, and all protein-coding regions end in a stop codon. When the ribosome reaches a stop codon, there is no tRNA that binds to it. Instead, proteins called “release factors” bind, and cause the ribosome, the mRNA, and the new polypeptide to separate. The new polypeptide is completed. Note that the mRNA continues on past the stop codon. The remaining portion is not translated: it is the 3’ untranslated region (3’ UTR).
.")
36
Post-Translational Modification
New polypeptides usually fold themselves spontaneously into their active conformation. However, some proteins are helped and guided in the folding process by chaperone proteins Many proteins have sugars, phosphate groups, fatty acids, and other molecules covalently attached to certain amino acids. Most of this is done in the endoplasmic reticulum. Many proteins are targeted to specific organelles within the cell. Targeting is accomplished through “signal sequences” on the polypeptide. In the case of proteins that go into the endoplasmic reticulum, the signal seqeunce is a group of amino acids at the N terminal of the polypeptide, which are removed from the final protein after translation.

Presentasi serupa