Upload presentasi
1
Outlier Pada Analisis Regresi
By Eni Sumarminingsih, SSi, MM

2
Pendahuluan Tujuan dari Analisis Regresi adalah mengepas persamaan pada peubah yang terobservasi Model regresi linier klasik mengasumsikan hubungan berikut : Dimana n adalah ukuran contoh Variabel xi1, …, xip adalah variabel penjelas dan yi adalah variabel respon

3
Pada theori klasik diasumsikan eror ei menyebar normal dengan rata – rata nol dan ragam 2 Jadi dengan analisis regresi kita menduga parameter Dari data

4
Dengan menggunakan metode penduga regresi pada data tersebut didapatkan Dimana adalah koefisien regresi adalah nilai duga y yang didapat dari persamaan berikut

5
Residual ri dari amatan ke I adalah selisih antara y observasi dan y dugaan Metode Kuadrat Terkecil (MKT) atau Ordinary Least Square (OLS) adalah metode paling populer untuk menduga parameter model regresi
 atau Ordinary Least Square (OLS) adalah metode paling populer untuk menduga parameter model regresi")
6
Ide dasar metode OLS adalah mencari nilai duga paramete yang meminimumkan Jumlah Kuadrat Galat

7
Efek Outlier pada Regresi Linier Sederhana
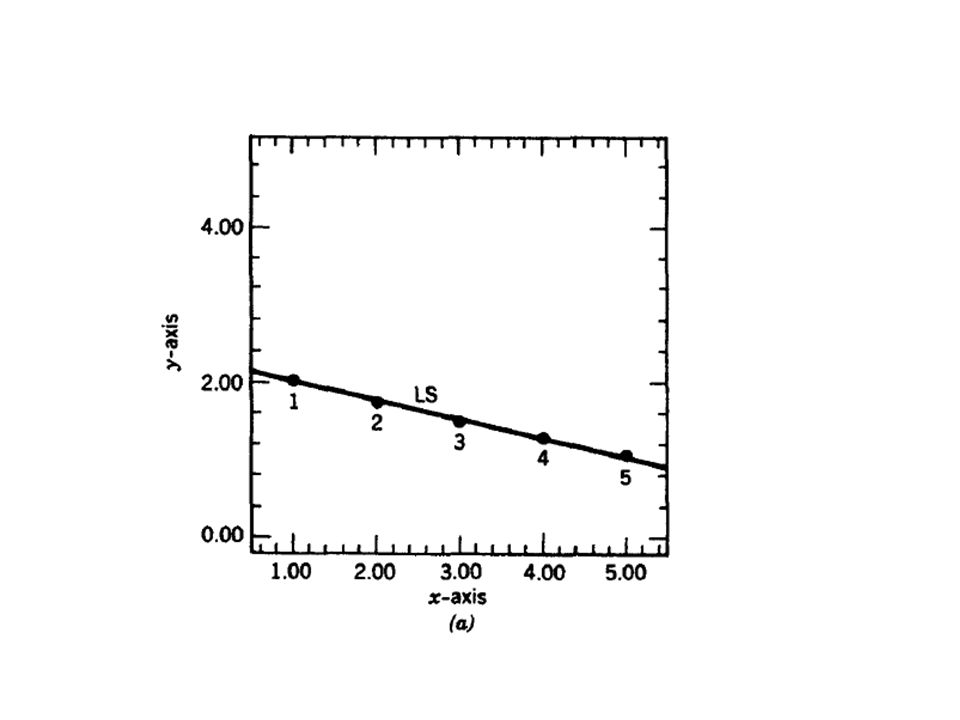
Model Regresi Linier Sederhana Misal kita memiliki 5 observasi (x1,y1),…, (x5,y5) yang jika diplotkan akan tampak seperti berikut : setiap titik sangat dekat dengan garis regresi
,…, (x5,y5) yang jika diplotkan akan tampak seperti berikut : setiap titik sangat dekat dengan garis regresi")
9
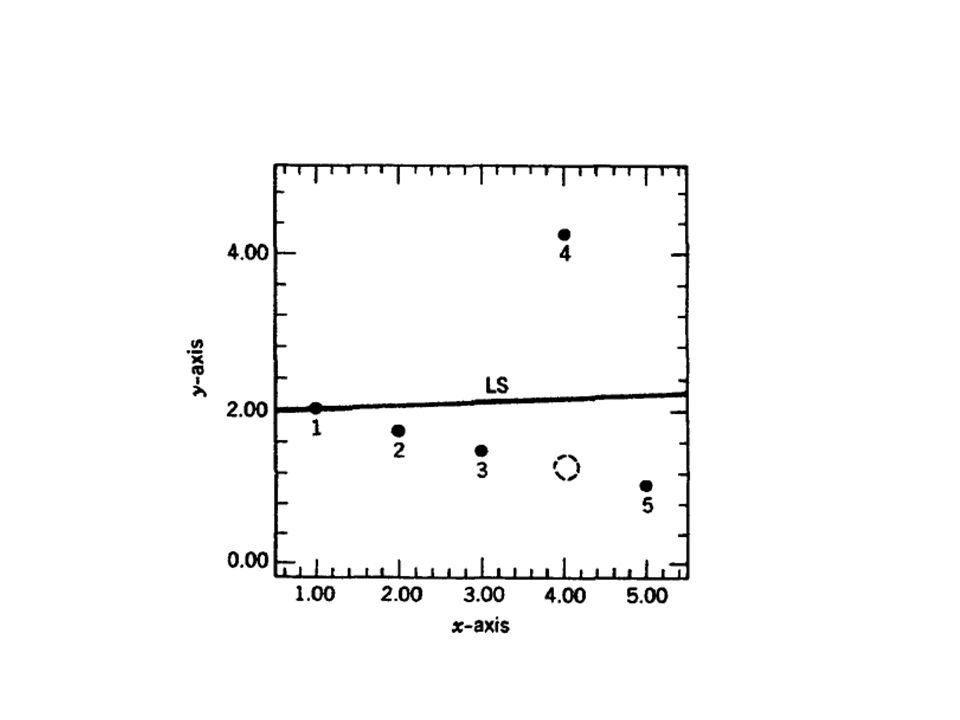
Misalkan terdapat kesalahan penulisan y4, maka titik (x4,y4) akan terletak jauh dari garis idealnya. Titik ini dinamakan outlier dalam y, dan mempengaruhi garis LS

11
Outlier juga dapat terjadi dalam X
Outlier juga dapat terjadi dalam X. Berikut adalah plot dari 5 titik (x1,y1), … (x5,y5) berikut garis LS-nya
, … (x5,y5) berikut garis LS-nya.")
12
Misalkan kita membuat kesalahan dalam mencatat x1 sehingga maka kita dapatkan gambar berikut

13
Titik (x1,y1) dinamakan outlier dalam arah x dan efeknya pada penduga LS sangat besar karena merubah garis LS. Titik (x1,y1) disebut leverage point
 disebut leverage point .")
14
Perhatikan bahwa (xk,yk) dalam gambar berikut bukan leverage point
Perhatikan bahwa (xk,yk) dalam gambar berikut bukan leverage point. Mengapa?
 dalam gambar berikut bukan leverage point. Mengapa")
15
Breakdown Point Misalkan terdapat sample dengan n titik data Dan misalkan T adalah penduga regresi sehingga Misalkan Z’ adalah sample yang didapat dari Z dimana m titik dalam Z diganti dengan titik – titik yang sembarang (ada kemungkinan outlier)
")
16
Notasikan bias(m; T, Z) adalah bias maksimum yang dapat disebabkan oleh kontaminasi tersebut Jika bias (m;T, Z) infinite berarti m outlier dapat memiliki efek yang besar pada T atau dapat dikatakan bahwa estimator “breaks down”
 adalah bias maksimum yang dapat disebabkan oleh kontaminasi tersebut Jika bias (m;T, Z) infinite berarti m outlier dapat memiliki efek yang besar pada T atau dapat dikatakan bahwa estimator breaks down")
17
Breakdown point dari estimator T pada sample Z didefinisikan sebagai Dengan kata lain, break down point adalah proporsi kontaminasi terkecil yang dapat menyebabkan estimator T menghasilkan yang cukup jauh dari T(Z)
")
18
Breakdown point untuk MKT (OLS) adalah Karena telah kita lihat bahwa satu outlier sudah dapat merubah nilai koefisien regresi Hal ini menunjukkan bahwa OLS sangat sensitif terhadap outlier
 adalah Karena telah kita lihat bahwa satu outlier sudah dapat merubah nilai koefisien regresi Hal ini menunjukkan bahwa OLS sangat sensitif terhadap outlier")
19
Identifikasi Pencilan pada Y
Dalam beberapa analisis regresi seringkali ditemukan adanya amatan ekstrem, yaitu bernilai jauh dengan amatan yang lain dalam sampel Adanya amatan ekstrem atau pencilan ini dapat menyebabkan residual yang besar dan seringkali memiliki efek yang besar pada dugaan fungsi regresi yang menggunakan OLS sehingga penduga koefisien regresi menjadi bias dan atau tidak konsisten

20
Pencilan harus diteliti dengan hati – hati apakah sebaiknya amatan ini dipertahankan atau dihilangkan. Jika dipertahankan, efek pencilan ini harus dikurangi

21
Suatu amatan dapat menjadi pencilan pada Y atau pada X atau pada keduanya

22
Pendeteksian Outlier Untuk pendeteksian pencilan , diperlukan suatu matriks yang dinamakan hat matrix yang dilambangkan dengan H

23
Penduga Y dapat ditulis sebagai Dengan

24
Elemen diagonal dari matriks H memberikan informasi tentang data observasi yang mempunyai nilai leverage yang besar Elemen diagonal ke-i dari matriks H yang dilambangkan dengan hii diperoleh dari:

25
Dengan adalah vektor baris yang berisi nilai-nilai dari variabel bebas atau independen dalam pengamatan ke-i. Pada elemen diagonal matriks H, diperoleh dimana p adalah banyaknya peubah dalam model

26
Pendeteksian pencilan pada X
Jika nilai lebih besar dari 2(p+1)/n maka pengamatan ke-i dikatakan sebagai outlier pada X (leverage point).
/n maka pengamatan ke-i dikatakan sebagai outlier pada X (leverage point).")
27
Pendeteksian Pencilan pada Y
Hipotesis yang digunakan untuk menguji adalah: H0 : Pengamatan ke-i bukan outlier H1 : Pengamatan ke-i merupakan outlier Statistik uji yang dapat digunakan untuk menguji adalah studentized residual atau studentized deleted residual yang didefinisikan:

28
Pendeteksian Pencilan pada Y
Kriteria yang digunakan untuk menguji ada tidaknya outlier adalah di mana p adalah banyaknya variabel bebas ditambah satu

29
Pendeteksian Pengamatan Berpengaruh
merupakan pengamatan yang berpengaruh besar dalam pendugaan koefisien regresi memiliki nilai galat atau sisaan yang besar atau mungkin pula tidak, tergantung pada model yang digunakan

30
Metode untuk mendeteksi pengamatan berpengaruh
Cook’s Distance Cook’s Distance merupakan jarak antara pendugaan parameter dengan MKT yang diperoleh dari n pengamatan atau observasi yaitu dan pendugaan parameter yang diperoleh dengan terlebih dahulu menghapus pengamatan atau observasi ke-i yaitu

31
Jarak tersebut dapat dituliskan sebagai berikut: dengan

32
Hipotesis untuk menguji adanya pengamatan berpengaruh adalah sebagai berikut: H0 : Pengamatan ke-i tidak berpengaruh H1 : Pengamatan ke-i berpengaruh kriteria yang digunakan untuk menguji hipotesis tersebut adalah sebagai berikut, alpha = 0.5:

33
2. The Difference In Fits Statistic (DFITS) Hipotesis untuk menguji adanya pengamatan berpengaruh adalah sebagai berikut: H0 : Pengamatan ke-i tidak berpengaruh H1 : Pengamatan ke-i berpengaruh merupakan pengaruh pengamatan atau observasi ke-i pada nilai duga yang didefinisikan sebagai
 Hipotesis untuk menguji adanya pengamatan berpengaruh adalah sebagai berikut: H0 : Pengamatan ke-i tidak berpengaruh H1 : Pengamatan ke-i berpengaruh merupakan pengaruh pengamatan atau observasi ke-i pada nilai duga yang didefinisikan sebagai .")
34
Kriteria yang digunakan untuk menguji hipotesis tersebut adalah

35
Metode untuk Penanganan Pencilan
Metode Theil Merupakan metode regresi nonparametrik Tidak terpengaruh terhadap adanya data outlier atau pencilan Asumsi: Contoh yang diambil bersifat acak dan kontinyu; Regresi bersifat linier; Data diasumsikan tidak berdistribusi normal.

36
Misalkan terdapat n pasangan pengamatan, (X1, Y1), (X2, Y2), …, (Xn, Yn), persamaan regresi linier sederhana adalah: Theil (1950) dalam Sprent (1991, hal ) mengusulkan perkiraan slope garis regresi sebagai median slope dari seluruh pasangan garis dari titik-titik dengan nilai X yang berbeda
, (X2, Y2), …, (Xn, Yn), persamaan regresi linier sederhana adalah: Theil (1950) dalam Sprent (1991, hal ) mengusulkan perkiraan slope garis regresi sebagai median slope dari seluruh pasangan garis dari titik-titik dengan nilai X yang berbeda")
37
Untuk satu pasangan (Xi, Yi) dan (Xj, Yj) slope-nya adalah untuk i < j penduga dinotasikan dengan dinyatakan sebagai median dari nilai-nilai sehingga
 dan (Xj, Yj) slope-nya adalah untuk i < j penduga dinotasikan dengan dinyatakan sebagai median dari nilai-nilai sehingga")
38
Penduga M (M-Estimator) dengan Fungsi Huber
Penduga M adalah solusi (1) Dimana (.) adalah fungsi kriteria yang dapat berubah-ubah
 Dimana (.) adalah fungsi kriteria yang dapat berubah-ubah")
39
fungsi krtiteria (.) mempunyai beberapa sifat sebagai berikut:
 mempunyai beberapa sifat sebagai berikut:")
40
Untuk mendapatkan penduga koefisien regresi maka fungsi kriteria diturunkan dan disamakan dengan nol Dimana adalah hasil diferensiasi dari fungsi kriteria dan Xij adalah observasi ke-i pada regressor ke-j

41
Bentuk umum dari persamaan (1) adalah Dan bentuk umum persamaan (2) adalah
 adalah Dan bentuk umum persamaan (2) adalah")
42
Fungsi kriteria Huber yang didefinisikan sebagai berikut :

43
Dan fungsi pengaruhnya adalah Dengan

44
Persamaan kedua dapat dituliskan
Dengan Jika maka persamaan (2) menjadi
 menjadi.")
45
Untuk fungsi pengaruh Huber, diperloleh pembobot sebagai berikut :

46
Langkah-langkah penghitungan penduga M:




 Anindita Ardha Pradibtia (09.5878) Elmafatriza Elisha Ekatama (00.5955) Muh. Mustakim Hasma (09.6051)>")

















