Upload presentasi
1
Statistika Nonparametrik
PERTEMUAN KE-3 Statistika Nonparametrik FITRI CATUR LESTARI, M. Si. 2013

2
Analisis Pembelajaran
korelasi banyak populasi 2 populasi 1 populasi

3
Sekilas tentang Kenormalan
Bagaimana mendeteksi kenormalan secara sederhana? Boxplot, Histogram, Scatter Plot, Stem and Leaf Plot Bagaimana mendeteksi kenormalan secara tidak sederhana? Alat uji Bagaimana jika data berdistribusi tidak normal? Transformasi, perbanyak data, metode statistik nonparametrik Bisa jadi ketidaknormalan disebabkan oleh outlier. Bagaimana solusinya? Buang outlier, metode anti outlier

4
UJI KOLMOGOROV-SMIRNOV

5
Skala: minimal ordinal (Siegel,51)
Fungsi dan Esensi Fungsi: Membandingkan distribusi frekuensi kumulatif hasil pengamatan (sampel) dengan distribusi frekuensi kumulatif yang diharapkan(teoritis) Esensi Apakah sampel yang kita ambil berasal dari populasi yang memiliki distribusi normal? -goodness of fit- Tidak hanya distribusi normal uniform, poisson, eksponensial Skala: minimal ordinal (Siegel,51)
 dengan distribusi frekuensi kumulatif yang diharapkan(teoritis) Esensi. Apakah sampel yang kita ambil berasal dari populasi yang memiliki distribusi normal -goodness of fit- Tidak hanya distribusi normal uniform, poisson, eksponensial. Skala: minimal ordinal (Siegel,51)")
6
Urutkan datanya dari yang terkecil sampai terbesar
Prosedur Urutkan datanya dari yang terkecil sampai terbesar Buat distribusi frekuensi kumulatif relatifS(X) Hitung zstandarisasi Hitung distribusi frekuensi kumulatif teoritis (berdasarkan kurve normal)F(X) Hitung selisih poin (b) dengan poin (d) Hitung D=selisih maksimum poin (e) (nilai paling besar pada poin (e)) Bandingkan dengan D tabel(Ho ditolak jika D>Dtabel) Ada juga yang menggunakan simbol T
 Hitung zstandarisasi. Hitung distribusi frekuensi kumulatif teoritis (berdasarkan kurve normal)F(X) Hitung selisih poin (b) dengan poin (d) Hitung D=selisih maksimum poin (e) (nilai paling besar pada poin (e)) Bandingkan dengan D tabel(Ho ditolak jika D>Dtabel) Ada juga yang menggunakan simbol T.")
7
Contoh Suatu perusahaan penerbangan ingin mengetahui apakah keterlambatan waktu take-off pesawat-pesawat terbang di pelabuhan udara X berdistribusi normal. Dari sampel 11 keterlambatan yang terjadi diketahui (dalam jam): Dari studi-studi pelabuhan udara lainnya dipertimbangkan bahwa keterlambatan take-off di pelabuhan udara x akan mempunyai mean 3 jam dengan simpangan baku 1 jam. Apakah data tersebut berdistribusi normal? Bedanya dengan Lilifors 1 2 3 4 5 6 7 8 9 10 11 2,1 1,9 3,2 2,8 1,0 5,1 0,9 4,2 3,9 3,6 2,7
: Dari studi-studi pelabuhan udara lainnya dipertimbangkan bahwa keterlambatan take-off di pelabuhan udara x akan mempunyai mean 3 jam dengan simpangan baku 1 jam. Apakah data tersebut berdistribusi normal Bedanya dengan Lilifors ,1. 1,9. 3,2. 2,8. 1,0. 5,1. 0,9. 4,2. 3,9. 3,6. 2,7.")
8
Penyelesaian = 0,1795 Ho data berdistribusi normal
SN(Xi) F0(Xi) = 0,1795 Ho data berdistribusi normal Alpha 10%Dtabeln=11 ____ 0,352 Data menyebar normal
 F0(Xi) = 0,1795 Ho data berdistribusi normal. Alpha 10%Dtabeln=11 ____ 0,352. Data menyebar normal.")
9
CONTOH LAGI, kalau ada data kembar

10
CONTOH LAGI Berdasarkan penelitian tentang intensitas penerangan alami yang dilakukan terhadap 18 sampel rumah sederhana, rata-rata pencahayaan alami di beberapa ruangan dalam rumah pada sore hari sebagai berikut ; 46, 57, 52, 63, 70, 48, 52, 52, 54, 46, 65, 45, 68, 71, 69, 61, 65, 68 lux. Selidikilah dengan α = 5%, apakah data tersebut di atas diambil dari populasi yang berdistribusi normal ?

11
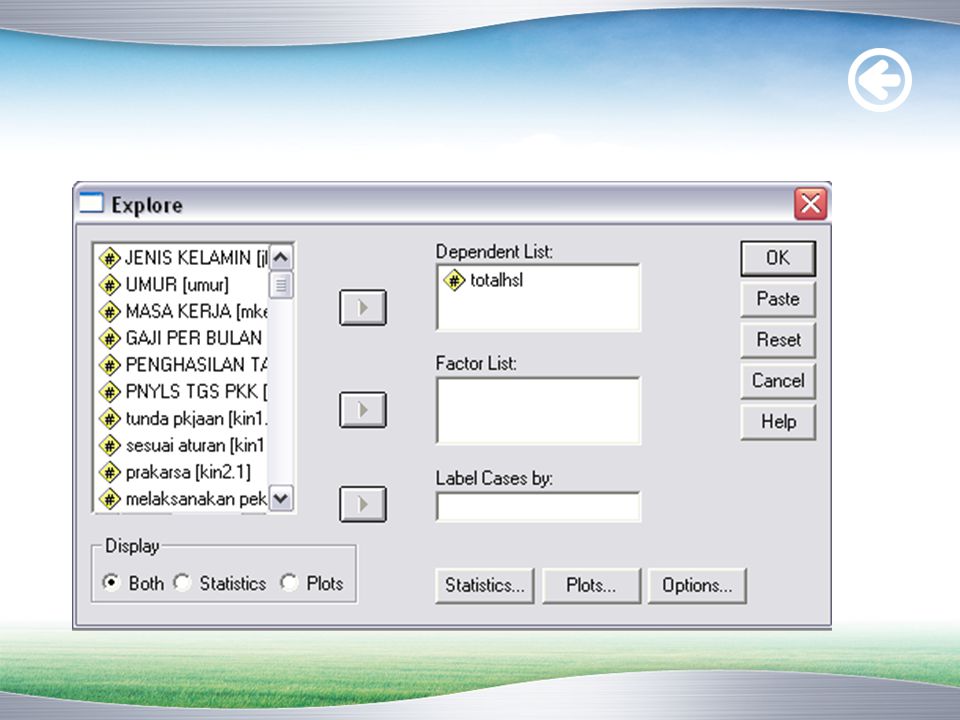
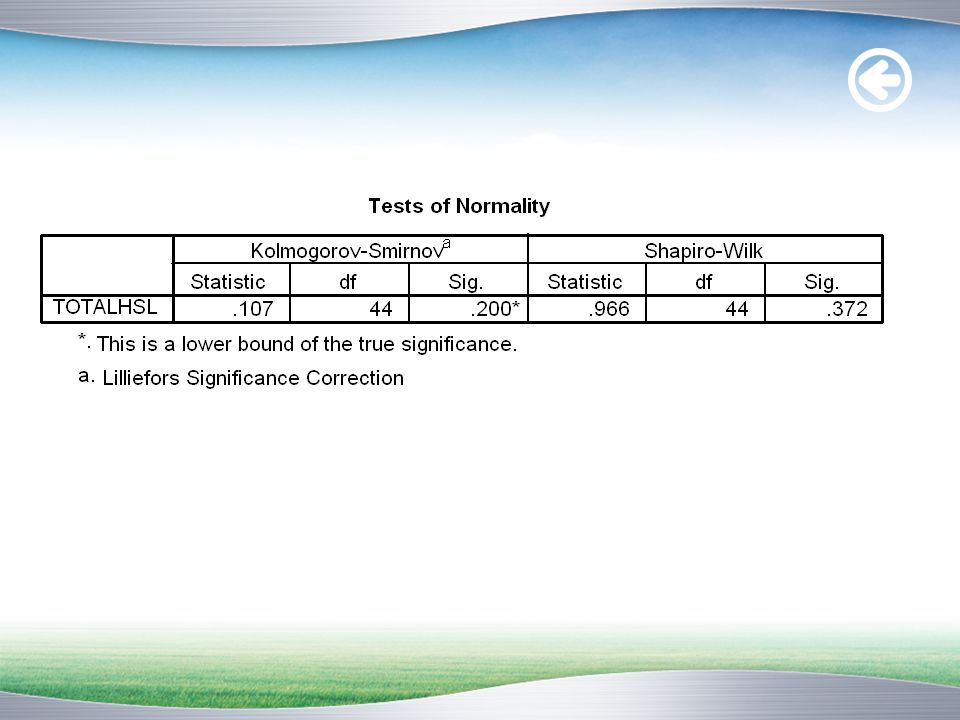
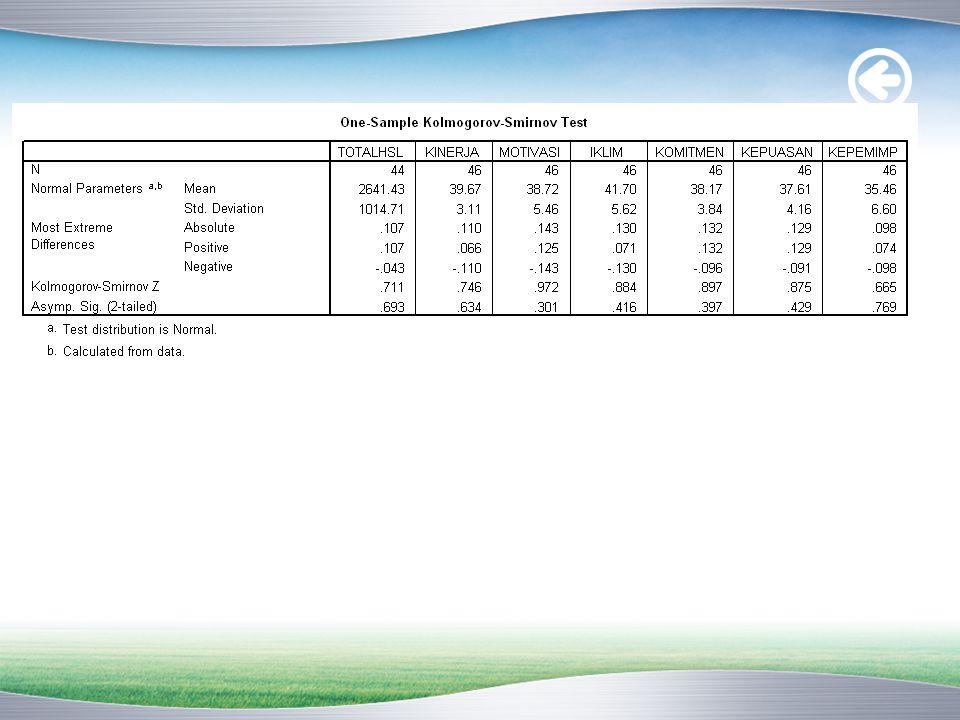
SPSS-Cara 1 Kolmogorov-Smirnov dari menu Analyze > Descriptive Statistics > Explore

15
SPSS-Cara 2

18
UJI CHI SQUARE

19
Tidak hanya distribusi normal
Fungsi dan Esensi Fungsi: Membandingkan fungsi distribusi random variabel pengamatan dengan fungsi distribusi normal Esensi Apakah sampel yang kita ambil berasal dari populasi yang memiliki distribusi normal? -goodness of fit- Tidak hanya distribusi normal

20
pj*=peluang suatu observasi X termasuk dalam kelas j (j=1,…,c)
Formula Ho menyatakan proporsi sebuah obyek jatuh pada tiap kategori pada populasi yang diduga pj*=peluang suatu observasi X termasuk dalam kelas j (j=1,…,c) Ei= pj*.N tidak boleh kecil nilainya karena distribusinya cenderung tidak Chi Square Cohran menyarankan Ei jangan kurang dari 1 dan tidak lebih dari 20% Ei kurang dari 5 Yarnold Tolak Ho jika T>X1-alpha Siegel, 45
 Ei= pj*.N tidak boleh kecil nilainya karena distribusinya cenderung tidak Chi Square. Cohran menyarankan Ei jangan kurang dari 1 dan tidak lebih dari 20% Ei kurang dari 5. Yarnold Tolak Ho jika T>X1-alpha. Siegel, 45.")
21
Siegel The size of df reflects the number of “observations” which are free to vary after certain restrictions have been placed on the data df: k-1 dengan Ei=N/k

22
CONTOH-Uniform Grup 1 2 3 4 5 6 7 8 Total Obs 29 19 18 25 17 10 15 11
144 Eksp Hipotesis: Ho: Data berdistribusi uniform H1: Data tdk berdistribusi uniform Stat uji: X2 Alpha=1% Distribusi sampling: dist X2 df=k-1=8-1=7 Daerah penolakan: Ho ditolak jika prob. Atau p-value <=0.01 Keputusan: X2 hit =16.3 Terima Ho Tapi kalau alpha 5% Tolak Ho Tabel 1%=18.475 Tabel 5%=14.067

23
CONTOH-Normal Grup 1 2 3 4 5 6 7 8 9 10 Total Obs 13 15 14 12 103 Eksp 10.3 X2=8.36 X2 tabel=14.07 Terima Ho: data berdistribusi normal Catatan: Derajat bebas

24
Ekspektasi yang terlalu kecil
Df=1 (k=2)minimal Ei=5 Df>1 (k>2) tidak digunakan jika: Lebih dari 20% Ei nya <5 Ada Ei<1 Penggabungan kategori p50 Jika sudah dikombinasikan/gabung masih Ei nya <5 maka gunakan uji binomial
minimal Ei=5. Df>1 (k>2) tidak digunakan jika: Lebih dari 20% Ei nya <5. Ada Ei<1. Penggabungan kategori p50. Jika sudah dikombinasikan/gabung masih Ei nya <5 maka gunakan uji binomial.")
25
Contoh Apakah data di bawah ini berdistribusi normal dengan mean 30 dan varians 100?

26
Penyelesaian w0.25 w0.5 w0.75tabel X0.25=30+10(-0.6745)=23.255
Kelas 1 <=23.255 Kelas <x<=30 Kelas 3 30<x<=36.745 Kelas 4 >36.745

27
Oj=8,4,3,5 T=2.8 Alpha 0.05tolak Ho jika T>7.815

28
Rules of Thumbs Pilih interval dimana Ekspektasinya : N/k
Jumlah kategori ditentukan sedemikian rupa sehingga Ekspektasinya antara 6-10 untuk sampel besar (>200)
")
29
PERBANDINGAN

30
K-S tidak tergantung pada pengelompokan seperti pada Chi-Square (CS)
Jika sampel sedikit, maka K-S lebih powerful K-S dapat digunakan pada sampel kecil sekalipun Chi Square membutuhkan data skala nominal K-S membutuhkan data distribusi kontinu KS dan CS bisa digunakan untuk data berskala ordinal Presisi KS lebih tinggi karena pada CS terdapat pengelompokan. Pada sampel kecil, KS adalah eksak sedangkan CS hanya pendekatan eksak.

31
Terdapat beberapa keuntungan dan kerugian relatif uji kesesuaian Kolmogorov-Smirnov dibandingkan dengan uji kesesuaian Kai Kuadrat, yaitu: Data dalam Uji Kolmogorov-Smirnov tidak perlu dilakukan kategorisasi. Dengan demikian semua informasi hasil pengamatan terpakai. Uji Kolmogorov-Smirnov bisa dipakai untuk semua ukuran sampel, sedang uji Kai Kuadrat membutuhkan ukuran sampel minimum tertentu. Uji Kolmogorov-Smirnov tidak bisa dipakai untuk memperkirakan parameter populasi. Sebaliknya uji Kai Kuadrat bisa digunakan untuk memperkirakan parameterpopulasi,dengan cara mengurangi derajat bebas sebanyak parameter yang diperkirakan. Uji Kolmogorov-Smirnov memakai asumsi bahwa distribusi populasi teoritis bersifat kontinu.

32
Metode Lilliefors Untuk Uji Normalitas
Uji lilliefors digunakan bila ukuran sampel (n) lebih kecil dari 30. Misalkan sampel acak dengan hasil pengamatan : x1 ,x2 , …,xn. Akan diuji apakah sampel tersebut berasal dari populasi berdistribusi normal atau tidak?
 lebih kecil dari 30. Misalkan sampel acak dengan hasil pengamatan : x1 ,x2 , …,xn. Akan diuji apakah sampel tersebut berasal dari populasi berdistribusi normal atau tidak")
33
Langkah-langkah pengujian:
Rumuskan Hipotesis: Ho : sampel berasal dari populasi berdistribusi normal H1 : sampel tidak berasal dari populasi berdistribusi normal Tentukan α : taraf nyata Susun tabel berikut: Data diurutkan dari terkecil ke terbesar Cari rata-rata, simpangan baku sampel Lakukan standarisasi normal (z=(xi–x) /s) Hitung peluang F(zi ) = P(zi) Hitung proporsi yang lebih kecil atau sama dengan zi -> S( zi) Hitung | F(zi) – S(zi) | Statistik Uji : Nilai terbesar dari | F(zi) -S(zi) | Dengan α tertentu tentukan titik kritis L Kriteria uji : tolak Ho jika Lo >= Ltabel , terima dalam hal lainya.
 /s) Hitung peluang F(zi ) = P(zi) Hitung proporsi yang lebih kecil atau sama dengan zi -> S( zi) Hitung | F(zi) – S(zi) | Statistik Uji : Nilai terbesar dari | F(zi) -S(zi) | Dengan α tertentu tentukan titik kritis L. Kriteria uji : tolak Ho jika Lo >= Ltabel , terima dalam hal lainya.")
34
PR Cari soal dan penyelesaian (sebanyak mungkin) dari buku referensi (cantumkan sumbernya) ttg uji liliefors. Kerjakan menurut kelompok bulan lahir: Kelompok 1: Januari-Maret Kelompok 2: April-Juni Kelompok 3: Juli-September Kelompok 4: Oktober-Desember Ketik dan kumpulkan lewat setelah di compile oleh PJ Deadline Senin, tgl 8 April 2013

35
T E R I M A K A S I H

36
Fitri Catur Lestari, M. Si. 2013
Uji Kenormalan TEKNIS ! Fitri Catur Lestari, M. Si. 2013

37
Metode Kolmogorov Smirnov
Persyaratan : Data berskala interval atau ratio (kuantitatif) Data tunggal/belum dikelompokkan pada table distribusi frekuensi Dapat untuk n besar maupun n kecil. D = max |Fr – Fs| Tolak Ho jika D > D (α,n) Fr = nilai Z Fs = probabilitas kumulatif empiris
 Data tunggal/belum dikelompokkan pada table distribusi frekuensi. Dapat untuk n besar maupun n kecil. D = max |Fr – Fs| Tolak Ho jika D > D (α,n) Fr = nilai Z. Fs = probabilitas kumulatif empiris.")
38
Tabel uji Kolmogorov-Smirnov

39
Soal : Suatu penerapan tentang berat badan peserta pelatihan kebugaran fisik/jasmani dengan sampel sebanyak 27 orang diambil secara random, didapatkan data sebagai berikut : 78, 78, 95, 90, 78, 80, 82, 77, 72, 84, 68, 67, 87, 78, 77, 88, 97, 89, 97, 98, 70, 72, 70, 69, 67, 90, 97 kg. Selidikilah dengan α= 5%, apakah data tersebut diambil dari populasi yang berdistribusi normal ?

40
Penyelesaian : Hipotesis: Ho : Data berdistribusi normal H1 : Data tidak berdistribusi normal α = 0,05 Statistik uji dan hitung: X = 81,2963 SD = 10,28372 Dhitung: nilai |Fr-Fs| tertinggi sebagai angka penguji normalitas, yaitu 0, 1440

41
Dan seterusnya..

42
Daerah kritis : Ho ditolak jika Dhitung>Dn(α) = D27(0,05) = 0,254. Keputusan : Terima Ho karena 0,1440 < 0,254 Kesimpulan : Dengan tingkat kepercayaan 95%, dapat diperkirakan bahwa data berat badan peserta pelatihan kebugaran diperoleh dari populasi yg berdistribusi normal.

43
Metode Goodness-of-fit
Metode Chi square atau χ2 untuk uji Goodness of Fit Distribusi Normal menggunakan pendekatan penjumlahan penyimpangan data observasi tiap kelas dengan nilai yang diharapkan. Rumus :

44
Tabel : Persyaratan : Data bersusun berkelompok atau dikelompokkan dalam table distribusi frekuensi Cocok untuk data dengan kebanyakan angka besar (n > 30) Setiap sel harus terisi, yang Ei kurang dari 5 digabungkanlebih baik jika ada referensi
 Setiap sel harus terisi, yang Ei kurang dari 5 digabungkanlebih baik jika ada referensi.")
45
Jika χ2 > nilai χ2 tabel, maka Ho ditolak
Contoh : Data tinggi badan Selidiki dengan α = 5%, apakah data diatas berdistribusi normal ?

46
Ho : Data berdistribusi normal H1 : Data tidak berdistribusi normal
Penyelesaian : Hipotesis: Ho : Data berdistribusi normal H1 : Data tidak berdistribusi normal Alpha= 5% Statistik uji dan hitung: X = 165,3 ; SD = 10,36

47
χ2 = 0,1628 Daerah kritis: Ho ditolak jika χ2hitung > χ2tabel Df = (k - 3) = (5 – 3) = 2 Nilai table χ20,05; 2 = 5,991 Keputusan: Karena | 0,1628 | < | 5,991 | maka Ho diterima Kesimpulan: Dengan tingkat kepercayaan 95%, dapat diperkirakan bahwa tinggi badan masyarakat kalimas tahun diambil dari populasi yang berdistribusi normal.

48
Thank You







>")


>")











