Upload presentasi
1
UJI ASUMSI KLASIK

2
Tujuan Pengajaran: Mengerti apa yang dimaksud dengan uji asumsi klasik
Mengerti item-item asumsi Menjelaskan maksud item-item asumsi Menyebutkan nama-nama asumsi yang harus dipenuhi Mengerti apa yang dimaksud dengan autokorelasi

3
Mengerti apa yang dimaksud dengan Multikolinearitas
Mengerti apa yang dimaksud dengan Heteroskedastisitas Mengerti apa yang dimaksud dengan Normalitas Menjelaskan timbulnya masalah-masalah dalam uji asumsi klasik

4
Menjelaskan dampak dari autokorelasi, heteroskedastisitas, multikolinearitas, normalitas
Menyebutkan alat deteksi dari masalah-masalah tersebut

5
Menggunakan sebagian alat-alat deteksi
Menjelaskan keterkaitan asumsi-asumsi Menjelaskan konsekuensi-konsekuensi dari Asumsi

6
asumsi-asumsi klasik Jika hasil regresi telah memenuhi asumsi-asumsi regresi maka nilai estimasi yang diperoleh akan bersifat BLUE: (Best, Linear, Unbiased, Estimator.)
")
7
Gauss-Markov Theorem. BLUE: (Best, Linear, Unbiased, Estimator.)
Adalah asumsi yang dikembangkan oleh Gauss dan Markov, yang kemudian teori tersebut terkenal dengan sebutan Gauss-Markov Theorem.

8
Best dimaksudkan sebagai terbaik
Hasil regresi dikatakan Best apabila garis regresi yang dihasilkan guna melakukan estimasi atau peramalan dari sebaran data, menghasilkan error yang terkecil.

9
Linear Linear dalam model artinya model yang digunakan dalam analisis regresi telah sesuai dengan kaidah model OLS dimana variabel-variabel penduganya hanya berpangkat satu. Sedangkan linear dalam parameter menjelaskan bahwa parameter yang dihasilkan merupakan fungsi linear dari sampel

10
Unbiased atau tidak bias, Suatu estimator dikatakan unbiased jika nilai harapan dari estimator b sama dengan nilai yang benar dari b. Artinya, nilai rata-rata b = b. Bila rata-rata b tidak sama dengan b, maka selisihnya itu disebut dengan bias.

11
10 asumsi yang menjadi syarat penerapan OLS,
Gujarati (1995): Asumsi 1: Linear regression Model. Model regresi merupakan hubungan linear dalam parameter. Y = a + bX +e
: Asumsi 1: Linear regression Model. Model regresi merupakan hubungan linear dalam parameter. Y = a + bX +e.")
12
Untuk model regresi: Y = a + bX + cX2 + e Walaupun variabel X dikuadratkan, ini tetap merupakan regresi yang linear dalam parameter sehingga OLS masih dapat diterapkan.

13
Asumsi 2: Nilai X adalah tetap dalam sampling yang diulang-ulang (X fixed in repeated sampling).
Tepatnya bahwa nilai X adalah nonstochastic (tidak random).
.")
14
Asumsi 3: Variabel pengganggu e memiliki rata-rata nol (zero mean of disturbance).
.")
15
Asumsi 4: Homoskedastisitas, atau variabel pengganggu e memiliki variance yang sama sepanjang observasi dari berbagai nilai X. Ini berarti data Y pada setiap X memiliki rentangan yang sama. Jika rentangannya tidak sama, maka disebut heteroskedastisitas Variance……

16
Asumsi 5: Tidak ada otokorelasi antara variabel e pada setiap. nilai
Asumsi 5: Tidak ada otokorelasi antara variabel e pada setiap nilai xi dan ji (No autocorrelation between the disturbance).
.")
17
Asumsi 6: Variabel X dan disturbance e tidak berkorelasi.

18
Asumsi 7: Jumlah observasi atau besar sampel (n) harus lebih. besar
Asumsi 7: Jumlah observasi atau besar sampel (n) harus lebih besar dari jumlah parameter yang diestimasi.
 harus lebih besar dari jumlah parameter yang. diestimasi.")
19
Asumsi 8: Variabel X harus memiliki variabilitas
Asumsi 8: Variabel X harus memiliki variabilitas. Jika nilai X selalu sama sepanjang observasi maka tidak bisa dilakukan regresi.

20
Asumsi 9: Model regresi secara benar telah terspesifikasi.
Artinya, tidak ada spesifikasi yang bias, karena semuanya telah terekomendasi atau sesuai dengan teori.

21
Asumsi 10. Tidak ada multikolinearitas antara variabel penjelas
Asumsi 10. Tidak ada multikolinearitas antara variabel penjelas. Jelasnya kolinear antara variabel penjelas tidak boleh sempurna atau tinggi.

22
meskipun nilai t sudah signifikan ataupun tidak signifikan, keduanya tidak dapat memberi informasi yang sesungguhnya.

23
Untuk memenuhi asumsi-asumsi di atas, maka estimasi regresi hendaknya dilengkapi dengan uji-uji yang diperlukan, seperti: uji normalitas, autokorelasi, heteroskedastisitas, atupun multikolinearitas.

24
Secara teoretis model OLS akan menghasilkan estimasi nilai parameter model penduga yang sahih bila dipenuhi asumsi Tidak ada Autokorelasi, Tidak Ada Multikolinearitas, dan Tidak ada Heteroskedastisitas.

25
A. Uji Autokorelasi

26
A.1. Pengertian autokorelasi
Autokorelasi adalah keadaan dimana variabel gangguan pada periode tertentu berkorelasi dengan variabel gangguan pada periode lain.

27
Asumsi terbebasnya autokorelasi ditunjukkan oleh nilai e yang mempunyai rata-rata nol, dan variannya konstan.

28
A.2. Sebab-sebab Autokorelasi
1. Kesalahan dalam pembentukan model, 2. Tidak memasukkan variabel yang penting. 3. Manipulasi data 4. Menggunakan data yang tidak empiris

29
A.3. Akibat Autokorelasi Akibatnya adalah nilai t hitung akan menjadi bias pula, karena nilai t diperoleh dari hasil bagi Sb terhadap b (t = b/sb). Berhubung nilai Sb bias maka nilai t juga akan bias atau bersifat tidak pasti (misleading). ( Karena adanya masalah korelasi dapat menimbulkan adanya bias pada hasil regresi.)
. Berhubung nilai Sb bias maka nilai t juga akan bias atau bersifat tidak pasti (misleading). ( Karena adanya masalah korelasi dapat menimbulkan adanya bias pada hasil regresi.)")
30
1. Uji Durbin-Watson (DW Test).
.")
31
dapat pula ditulis dalam rumus sebagai berikut:

32
DW test ini terdapat beberapa asumsi penting
1. Terdapat intercept dalam model regresi. 2. variabel penjelasnya tidak random (nonstochastics).
.")
33
3. Tidak ada unsur lag dari variabel dependen di dalam model.
4. Tidak ada data yang hilang. 5. υ t = ρυ t −1 + ε t

34
Langkah-langkah pengujian autokorelasi menggunakan uji Durbin Watson (DW test) dapat dimulai dari menentukan hipotesis. (H◦)erdapat autokorelasi positif, atau, terdapat autokorelasi negatif.
erdapat autokorelasi positif, atau, terdapat autokorelasi negatif.")
35
Terdapat beberapa standar keputusan yang perlu dipedomani ketika menggunakan DW test, yang semuanya menentukan lokasi dimana nilai DW berada.

36
Jelasnya adalah sebagai berikut:
DW < dL = terdapat atokorelasi positif dL< DW <dU = tidak dapat disimpulkan (inconclusive) dU > DW >4-dU = tidak terdapat autokorelasi 4-dU < DW <4-dL = tidak dapat disimpulkan DW > 4-dL = terdapat autokorelasi negatif
 dU > DW >4-dU = tidak terdapat autokorelasi. 4-dU < DW <4-dL = tidak dapat disimpulkan. DW > 4-dL = terdapat autokorelasi negatif.")
37
Dimana: DW = Nilai Durbin-Watson d statistik dU = Nilai batas atas (didapat dari tabel) dL = Nilai batas bawah (didapat dari tabel)

38
Ketentuan-ketentuan daerah hipotesis pengujian DW dapat diwujudkan dalam bentuk gambar sebagai berikut:

39
Gambar 3.3.: Daerah Uji Durbin Watson

40
Bantuan dengan spss:

41
(α)=5%, N = 22 Prediktor : 2 batas atas (U) =1,54 sedang batas bawah (L) = 1,15. DW = 0,883
=5%, N = 22 Prediktor : 2 batas atas (U) =1,54 sedang batas bawah (L) = 1,15. DW = 0,883")
42
0,883 yang berarti lebih kecil dari nilai batas bawah, maka koefisien autokorelasi lebih kecil dari nol. Dengan demikian dapat disimpulkan bahwa hasil regresi tersebut belum terbebas dari masalah autokorelasi positif.

43
Dengan. kata. lain,. Hipotesis
Dengan kata lain, Hipotesis nol (H◦) yang menyatakan tidak terdapat masalah autokorelasi dapat ditolak, sedang hipotesis nol (H◦) yang menyatakan terdapat masalah autokorelasi dapat diterima
 yang menyatakan tidak terdapat masalah autokorelasi dapat ditolak, sedang hipotesis nol (H◦) yang menyatakan terdapat masalah autokorelasi dapat diterima.")
44
Uraian di atas dapat pula dijelaskan dalam bentuk gambar sbb

45
B. Uji Normalitas Tujuan dilakukannya uji normalitas adalah untuk menguji apakah variabel penganggu (e) memiliki distribusi normal atau tidak.
 memiliki distribusi normal atau tidak.")
46
Beberapa cara untuk melakukan uji normalitas, antara lain:
1. tendesi sentral (mean – median = 0) 2. Menggunakan formula Jarque Bera (JB test),
 2. Menggunakan formula Jarque Bera (JB test),")
47
formula Jarque Bera (JB test),
,")
48
dimana: S = Skewness (kemencengan) distribusi data K= Kurtosis (keruncingan)
 distribusi data K= Kurtosis (keruncingan)")
49
Skewness

50
Kurtosis

51
Bantuan SPSS : Hal

52
3) Mengamati sebaran data, dengan melakukan hitungan-hitungan berapa prosentase data observasi dan berada di area mana.
 Mengamati sebaran data, dengan melakukan hitungan-hitungan berapa prosentase data observasi dan berada di area mana.")
53
Untuk menentukan posisi normal dari sebaran data, langkah. awal
Untuk menentukan posisi normal dari sebaran data, langkah awal yang dilakukan adalah menghitung standar deviasi.

54
SD1 = 68 % SD2 = 95% SD3 = 99,7 %

55
Sebanyak 68% dari observasi berada pada area SD1
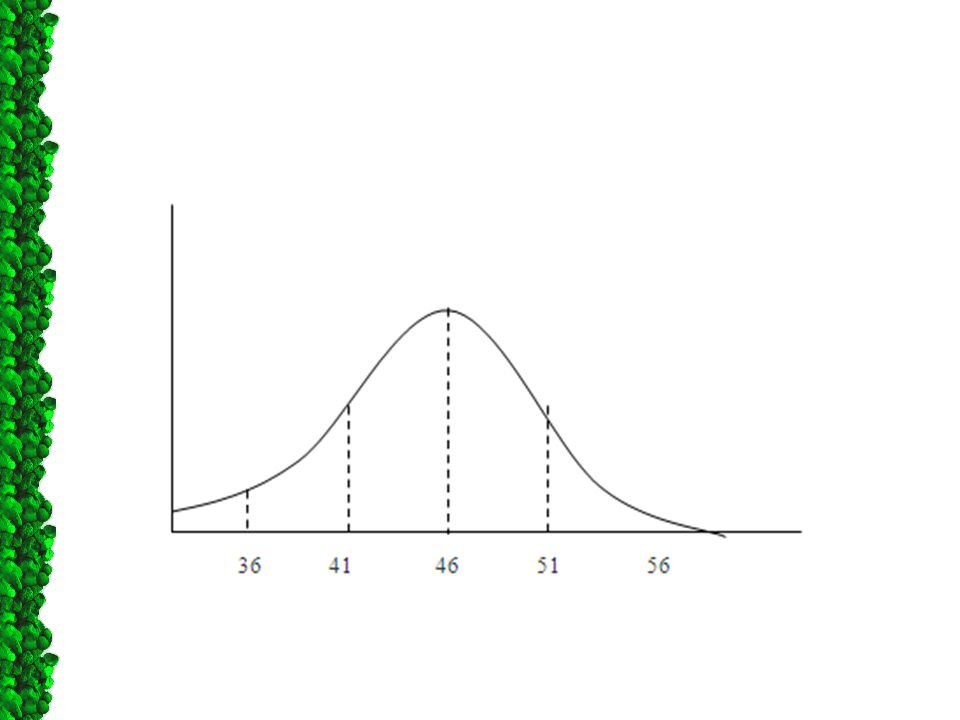
Penentuan area ini penting, karena sebaran data yang dikatakan normal apabila tersebar sebagai berikut: Sebanyak 68% dari observasi berada pada area SD1 Sebanyak 95% dari sisanya berada pada area SD2 Sebanyak 99,7% dari sisanya berada pada area SD3

56
sebaran data yang dikatakan normal

57
Apabila data tidak normal, maka
diperlukan upaya untuk mengatasi seperti: memotong data yang out liers, memperbesar sampel, atau melakukan transformasi data.

58
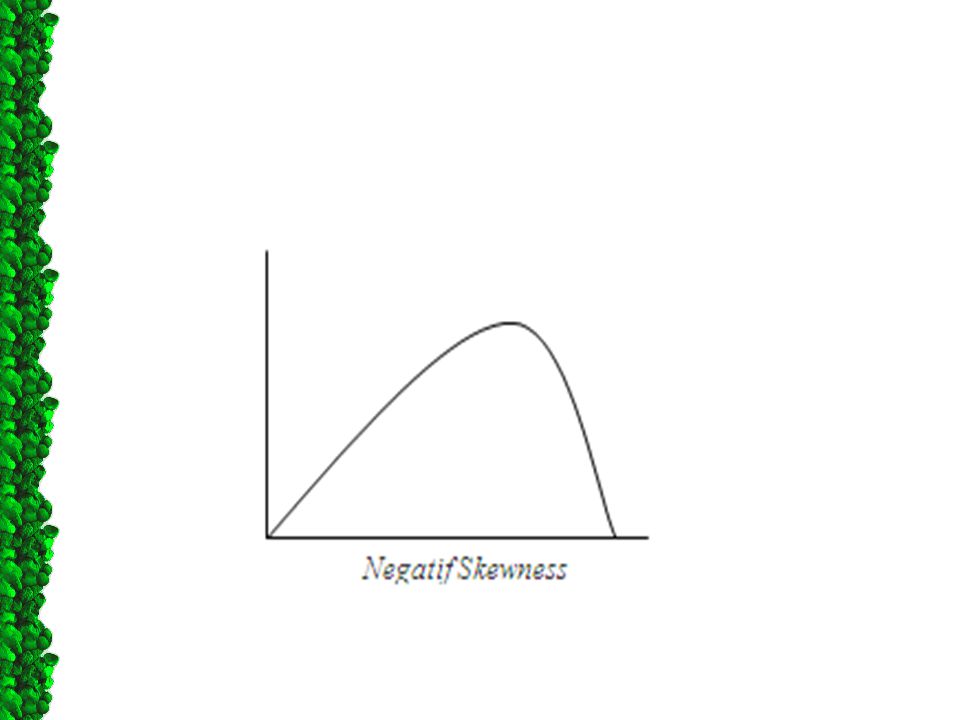
Data yang tidak normal juga dapat dibedakan dari tingkat kemencengannya (skewness). Jika data cenderung menceng ke kiri disebut positif skewness, dan jika data cenderung menceng ke kanan disebut negatif skewness. Data dikatakan normal jika datanya simetris.

59
Lihat gambar berikut:

62
Ilustrasi: Mean : 46 kg Sd = 5 kg 68% x 30 = 10: (41-46) kg
 kg")
64
C. Uji Heteroskedastisitas
C.1. Pengertian Heteroskedastisitas Model akan menghadapi masalah heteroskedastisitas. Heteroskedastisitas muncul apabila kesalahan (e) atau residual dari model yang diamati tidak memiliki varians yang konstan dari satu observasi ke observasi lainnya
 atau residual dari model yang diamati tidak memiliki varians yang konstan dari satu observasi ke observasi lainnya.")
65
rumus regresi diperoleh dengan asumsi bahwa variabel pengganggu (error) atau e, diasumsikan memiliki variabel yang konstan (rentangan e kurang lebih sama). Apabila terjadi varian e tidak konstan, maka kondisi tersebut dikatakan tidak homoskedastik atau mengalami heteroskedastisitas

66
C.2. Konsekuensi Heteroskedastisitas
1. Sb menjadi bias 2. nilai b bukan nilai yang terbaik. 3. Munculnya masalah heteroskedastisitas yang mengakibatkan nilai Sb menjadi bias, akan berdampak pada nilai t dan nilai F yang menjadi tidak dapat ditentukan.

67
Lain halnya, jika asumsi ini tidak terpenuhi, sehingga variance residualnya berubah-ubah sesuai perubahan observasi, maka akan mengakibatkan nilai Sb yang diperoleh dari hasil regresi akan menjadi bias.

68
C.3. Pendeteksian Heteroskedastisitas
Untuk mendeteksi ada tidaknya heteroskedastisitas, dapat dilakukan dengan berbagai cara seperti uji grafik, uji Park, Uji Glejser, uji Spearman’s Rank Correlation, dan uji Whyte menggunakan Lagrange Multiplier Membandingkan sebaran data pada scatter plot

69
menggunakan uji Arch, e ² = a + bỶ ² + u . Cari R ²
Kalikan R ² dengan n (sampel)/ R ² x n.
/ R ² x n.")
70
Jika R2 x N lebih besar dari chi-square (χ2) tabel, maka. standar
Jika R2 x N lebih besar dari chi-square (χ2) tabel, maka standar error mengalami heteroskedastisitas. Sebaliknya, jika R2 x N lebih kecil dari chi-square (χ2) tabel, maka standar error telah bebas dari masalah heteroskedastisitas, atau telah homoskedastis.
 tabel, maka standar error mengalami heteroskedastisitas. Sebaliknya, jika R2 x N lebih kecil dari chi-square (χ2) tabel, maka standar error telah bebas dari masalah. heteroskedastisitas, atau telah homoskedastis.")
71
Masalah heteroskedastisitas lebih sering muncul dalam data cross section dari pada data time series
Karena dalam data cross section menunjukkan obyek yang berbeda dan waktu yang berbeda pula. Antara obyek satu dengan yang lainnya tidak ada saling keterkaitan, begitu pula dalam hal waktu.

72
Sedangkan data time series, antara observasi satu dengan yang lainnya saling mempunyai kaitan. Ada trend yang cenderung sama. Sehingga variance residualnya juga cenderung sama.

73
D. Uji Multikolinieritas
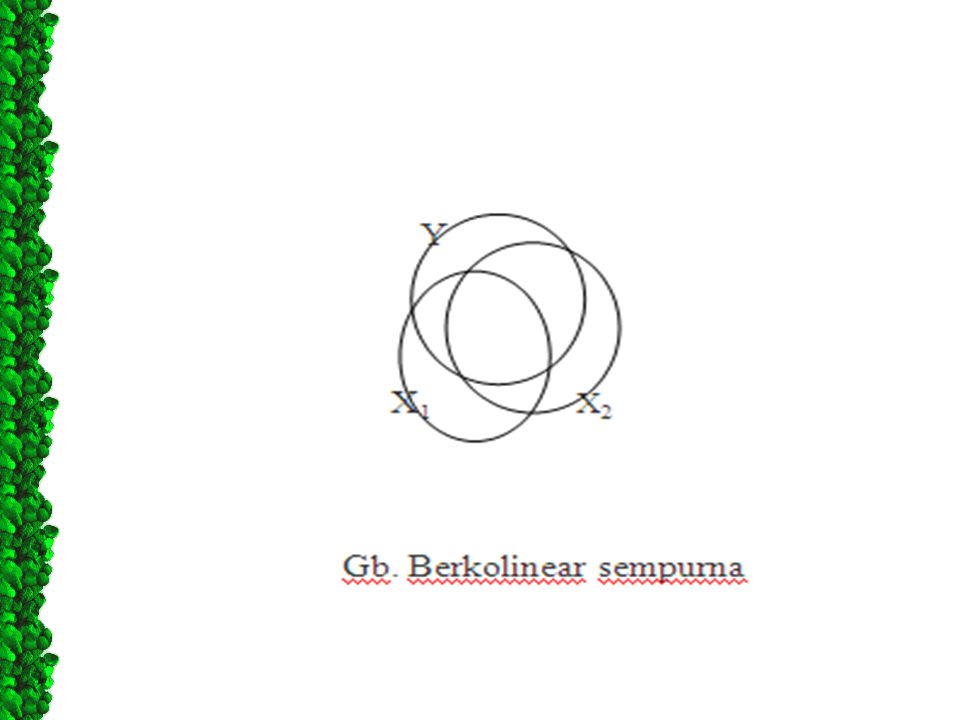
D.1. Pengertian Multikolinearitas Multikolinearitas: Multikolinieritas adalah suatu keadaan dimana terjadi korelasi linear yang ”perfect” atau eksak di antara variabel penjelas yang dimasukkan ke dalam model.

74
Sebagai gambaran penjelas,

77
D.2. Konsekuensi Multikolinearitas
Apabila belum terbebas dari masalah multikolinearitas akan menyebabkan nilai koefisien regresi (b) masing-masing variabel bebas dan nilai standar error-nya (Sb) cenderung bias, dalam arti tidak dapat ditentukan kepastian nilainya, sehingga akan berpengaruh pula terhadap nilai t
 masing-masing variabel bebas dan nilai standar error-nya (Sb) cenderung bias, dalam arti tidak dapat ditentukan kepastian nilainya, sehingga akan berpengaruh pula terhadap nilai t.")
78
D.3. Pendeteksian Multikolinearitas
Terdapat beragam cara untuk menguji multikolinearitas, di antaranya: menganalisis matrix korelasi dengan Pearson Correlation atau dengan Spearman’s Rho Correlation, melakukan regresi partial dengan teknik auxilary regression,

79
pendapat Gujarati (1995:335) yang mengatakan bahwa bila korelasi antara dua variabel bebas melebihi 0,8 maka multikolinearitas menjadi masalah yang serius.
 yang mengatakan bahwa bila korelasi antara dua variabel bebas melebihi 0,8 maka multikolinearitas menjadi masalah yang serius.")
80
Gujarati juga menambahkan bahwa, apabila korelasi. antara
Gujarati juga menambahkan bahwa, apabila korelasi antara variabel penjelas tidak lebih besar dibanding korelasi variabel terikat dengan masing-masing variabel penjelas, maka dapat dikatakan tidak terdapat masalah yang serius.

81
Dengan demikian, dapat disimpulkan bahwa apabila angka korelasi lebih kecil dari 0,8 maka dapat dikatakan telah terbebas dari masalah multikolinearitas.

82
Dalam kaitan adanya kolinear yang tinggi sehingga menimbulkan tidak terpenuhinya asumsi terbebas dari masalah multikolinearitas, dengan smempertimbangkan sifat data dari cross section, maka bila tujuan persamaan hanya sekedar untuk keperluan prediksi, hasil regresi dapat ditolerir, sepanjang nilai t signifikan.








>")














>")