Upload presentasi
1
Kesimpulan BUKU Data Mining
By Muhammad Kasim

2
Buku Analisis dan kesimpulan yang telah saya lakukan pada buku yang berjudul : “Data Mining Konsep dan Aplikasi menggunakan MATLAB” Oleh “Eko Prayetno yang di terbitkan oleh ANDI Yogyakarta”

3
Kata Pengantar “Buku ini disusun secara sistematis dan jelas dalam menjelaskan konsep dan aplikasi data mining, dan disertai dengan contoh nyata untuk penerapan metode yang di bahas dengan MATLAB. Salah satu metode yang dibahas dalam buku ini adalah klasifikasi Naive Bayes yang di bahas secara jelas dan lengkap disertai dengan contoh implementasinya menggunakan MATLAB”.

4
1. Pendahuluan Munculnya data mining didasarkan pada kenyataan bahwa jumlah data yang tersimpan dalam basis data semakin besar. Misalnya, disebuah market dan perusahaan yang memiliki transaksi dan prosduksi yang dibuat. Disiplin ilmu data mining berusaha menjawab masalah tersebut dengan melakukan proses yang dapat menemukan suatu informasi baru yang berguna bagi perusahaan.

5
2. Landasan Teori Data mining sebagai proses untuk mendapatkan informasi yang berguna dari gudang basis data yang besar. Data mining juga dapat di artikan sebagai pengekstrakan informasi baru yang diambil dari bongkahan data besar yang membantu dalam pengambilan keputusan. (Tan, 2006)
")
6
Pekerjaan dalam Data Mining
Pekerjaan yang berkaitan dengan data mining dapat dibagi 4 kelompok, yaitu : Model Prediksi Model prediksi berkaitan dengan pembuatan sebuah model yang dapat melakukan pemetaan dari setiap himpunan variabel k setiap himpunan variabel ke setiap target nya. 2. Analisis kelompok Analisis kelompok melakukan pengelompokan data-data ke dalam sejumlah kelompok (cluster) berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada.
 berdasarkan kesamaan karakteristik masing-masing data pada kelompok-kelompok yang ada.")
7
Analisis Asosiasi Digunakan untuk menemukan pola yang menggambarkan kekuatan hubungan fitur dalam data. Deteksi Anomali Deteksi anomali berkaitan dengan pengamatan sebuah data dari sejumlah data yang secara signifikan mempunyai karakteristik yang berbeda dari sisa data yang lain

8
Naive Bayes Classifier
Teorema Bayes : Bayes merupakan teknik prediksi berbasis probabilistik sederhana yang berdasar pada penerapan teorema Bayes (atau aturan Bayes) dengan asumsi indepedensi yang kuat. Yang dimaksud dengan indepedensi yang kuat ada fitur pada sebuah data tidak berkaitan dengan ada atau tidaknya fitur lain dalam data yang sama.
 dengan asumsi indepedensi yang kuat. Yang dimaksud dengan indepedensi yang kuat ada fitur pada sebuah data tidak berkaitan dengan ada atau tidaknya fitur lain dalam data yang sama.")
9
Prediksi bayes didasarkan pada teorema Bayes dengan formula umum sebagai berikut: Dimana : P(H) = probabilitas awal (priori) hipotesis H terjadi tanpa memandang bukti apapun P(H|E) = Probabilitas akhir bersyarat (conditional probability) suatu hipotesis H terjadi jika diberikan bukti (evidence) E terjadi.
 = probabilitas awal (priori) hipotesis H terjadi tanpa memandang bukti apapun P(H|E) = Probabilitas akhir bersyarat (conditional probability) suatu hipotesis H terjadi jika diberikan bukti (evidence) E terjadi.")
10
P(E|H) = Probabilitas sebuah bukti E terjadi akan memengaruhi hipotesis H P(E) = Probabilitas awal (priori) bukti E terjadi tanpa memandang hipotesis/bukti yang lain
 = Probabilitas sebuah bukti E terjadi akan memengaruhi hipotesis H P(E) = Probabilitas awal (priori) bukti E terjadi tanpa memandang hipotesis/bukti yang lain")
11
Contoh Masalah Data uji berupa hewan musang dgn fitur kulit = rambut , melahirkan =ya, berat =15. masuk kelas manakah ? Nama Hewan Kulit Melahirkan Berat Kelas Ular Sisik Ya 10 Reptil Tikus Bulu 0,8 Mamalia Kambing Rambut 21 Sapi 120 Kadal Tidak 0,4 Kucing 1,5 Bekicot Harimau Rusa Kura-kura Cangkang 0,3 43 45 7 Reptil Mamalia

12
Untuk menyelesaikannya pertama kita harus mengetahui nilai probabilitas setia fitur pada setiap kelasnya Mencari mean sample Xi (¯x) dan sample (s)
 dan sample (s)")
13
Setelah dapat sample dan varian sample , selanjutnya kita menghitung nilai probabilitas musang .

14
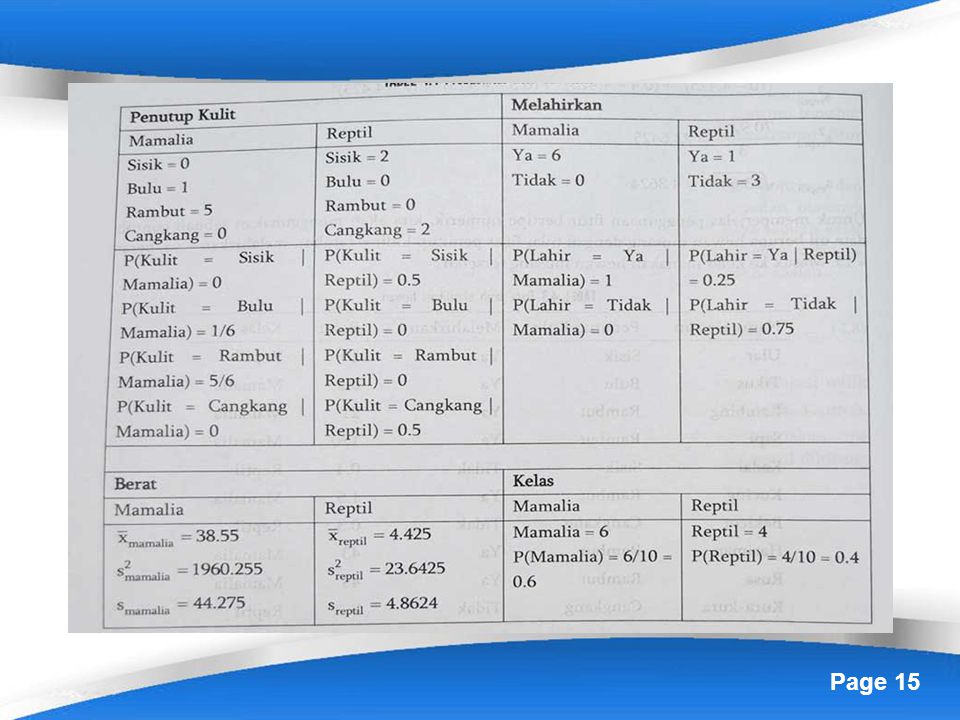
Setelah itu kita membuat tabel probabilitas fitur dan kelas , seperti gambar di bawah ini

16
Dari tabel diatas barulah kemudian menghitung probabilitas akhir setiap kelas
P(X|mamalia) = P(Rambut|mamalia) x P(Lahir=Ya| mamalia) x P(Berat=15|mamalia) = 5/6 x 1 x 0,0104 = 0,0087 P(X|Reptil) = P(kulit=Rambut| reptil) x P(Lahir=Ya| reptil) x P(Berat=15|reptil) = 0 x 0,25 x = 0 Selanjutnya nilai tersebut dimasukkan untuk memndapat kan probablitias akhir.
 = P(Rambut|mamalia) x P(Lahir=Ya| mamalia) x P(Berat=15|mamalia) = 5/6 x 1 x 0,0104 = 0,0087. P(X|Reptil) = P(kulit=Rambut| reptil) x P(Lahir=Ya| reptil) x P(Berat=15|reptil) = 0 x 0,25 x = 0. Selanjutnya nilai tersebut dimasukkan untuk memndapat kan probablitias akhir.")
17
P(Mamalia| X) = α x 0,6 x 0,0087 = 0,0052α P(Reptil|X) = α x 0 x 0,4 = 0 α= 1/P(x) nilainya konstan sehingga tidak perlu diketahui karena yang terbesar dari dua kelas tersebut tidak dapat dipengaruhi P(X). Karena nilai probabilitas akhir terbesar ada dikelas mamalia, data uji musang di prediksi sebagai kelas mamalia.

18
Karakteristik Naive bayes
Metode naive bayes teguh (robust) terhadap data-data yang terisolasi yang biasanya merupakan data dengan karakteristik berbeda (outlier). Naive bayes juga bisa menangani nilai atribut yang salah dengan mengabaikan data latih selama proses pembangunan model dan prediksi Tangguh menghadapai atribut yang tidak relevan Attribut yang mempunyai korelasi bisa mendegradasi kinerja klasifikasi Naive Bayes karena asumsi independensi atribut tersebut sudah tidak ada.
 terhadap data-data yang terisolasi yang biasanya merupakan data dengan karakteristik berbeda (outlier). Naive bayes juga bisa menangani nilai atribut yang salah dengan mengabaikan data latih selama proses pembangunan model dan prediksi. Tangguh menghadapai atribut yang tidak relevan. Attribut yang mempunyai korelasi bisa mendegradasi kinerja klasifikasi Naive Bayes karena asumsi independensi atribut tersebut sudah tidak ada.")
19
KESIMPULAN Dengan metode navie bayes kita bisa memecahkan masalah / data yang sudah di klasifikasikan terlebih dahulu, walaupun dalam metode navie bayes untuk memecahkan prediksi kelas untuk musang menurut saya sangat tepat karena kita melakukan perhitungan dengan contoh yang ada.

20
Saran Pada metode navie bayes ini untuk memudahkan pengerjaan nya sebaiknya di gabungkan dengan metode Discovery Model, karena navie bayes hanya bisa digunakan untuk persoalan klasifikasi data yang telah terkategori, sedangkan dalam suatu database belum tentu data tersebut langsung terkategori.

21
Dari maka itu kita memerlukan suatu model yang dapat mengolah data di dalam database / mengelompokkan data berdasarkan karakterisktik atau kategori secara otomatis. Serta menggunakan suatu model decision tree yang bertujuan untuk membagi ruang pencarian masalah menjadi himpunan masalah.

22
SEKIAN TERIMA KASIH




 © 2006 Prentice-Hall, Inc.>")










>")





