Upload presentasi
1
Pertemuan 11 UJI KENORMALAN

2
Banyak pengujian statistik yang menggunakan asumsi bahwa suatu distribusi peubah acaknya harus mengikuti suatu distribusi tertentu (e.g normal) Test statistik yg tidak terlalu didasarkan /dipengaruhi pada asumsi distribusi peubah acaknya : Non parametrik -> tidak menggunakan asumsi distribusi tertentu Robust -> dapat dipakai untuk berbagai asumsi distribusi Akan tetapi !!! Tehnik Pengujian yg didasarkan pada asumsi distribusi tertentu (parametrik tehnik) adalah “lebih baik”. Tehnik pengujian ini lebih kuat dalam mendeteksi suatu perbedaan dalam observasinya. :. Penting sekali melakukan pengujian untuk mengetahui apakah suatu observasi mengikuti suatu distribusi tertentu untuk membuktikan bahwa asumsi suatu pengujian terpenuhi/tidak.
 adalah lebih baik . Tehnik pengujian ini lebih kuat dalam mendeteksi suatu perbedaan dalam observasinya. :. Penting sekali melakukan pengujian untuk mengetahui apakah suatu observasi mengikuti suatu distribusi tertentu untuk membuktikan bahwa asumsi suatu pengujian terpenuhi/tidak.")
3
1. UJI CHI SQUARE (Dist. Freq)
H0 : data mengikuti distribusi tertentu (e.g Normal, Poisson) H1 : data tidak mengikuti distribusi tertentu Statistikuji : Chi-Square goodness of fit Data dikelompokkan dalam beberapa kelas (k) Uji ini dipengaruhi oleh cara pengelompokkan data tersebut Uji ini memerlukan sampel yang cukup besar (𝑛≥30) oi = Frekuensiobservasi ei = Frekuensi harapan ei= N(F(xu) – F (xL)) F = fungsi distribusi kumulatif N = jumlah sampel Xu = batas atas kelas ke i XL = batas bawah kelas ke i
 H1 : data tidak mengikuti distribusi tertentu. Statistikuji : Chi-Square goodness of fit. Data dikelompokkan dalam beberapa kelas (k) Uji ini dipengaruhi oleh cara pengelompokkan data tersebut. Uji ini memerlukan sampel yang cukup besar (𝑛≥30) oi = Frekuensiobservasi. ei = Frekuensi harapan. ei= N(F(xu) – F (xL)) F = fungsi distribusi kumulatif. N = jumlah sampel. Xu = batas atas kelas ke i. XL = batas bawah kelas ke i.")
4
Wilayah kritis : χ 2ob > χ 2α;(k-b) tolak H0 k = jumlah kelas/kelompok b = banyaknya besaran yg digunakan untuk menghitung frekuensi harapan (ei) contoh : untuk distribusi Normal ei = N(F(xu) – F (xL)) F(x) = X-µ/ :. Ada 3 besaran untuk ei : µ, , N
 contoh : untuk distribusi Normal. ei = N(F(xu) – F (xL)) F(x) = X-µ/ :. Ada 3 besaran untuk ei : µ, , N.")
5
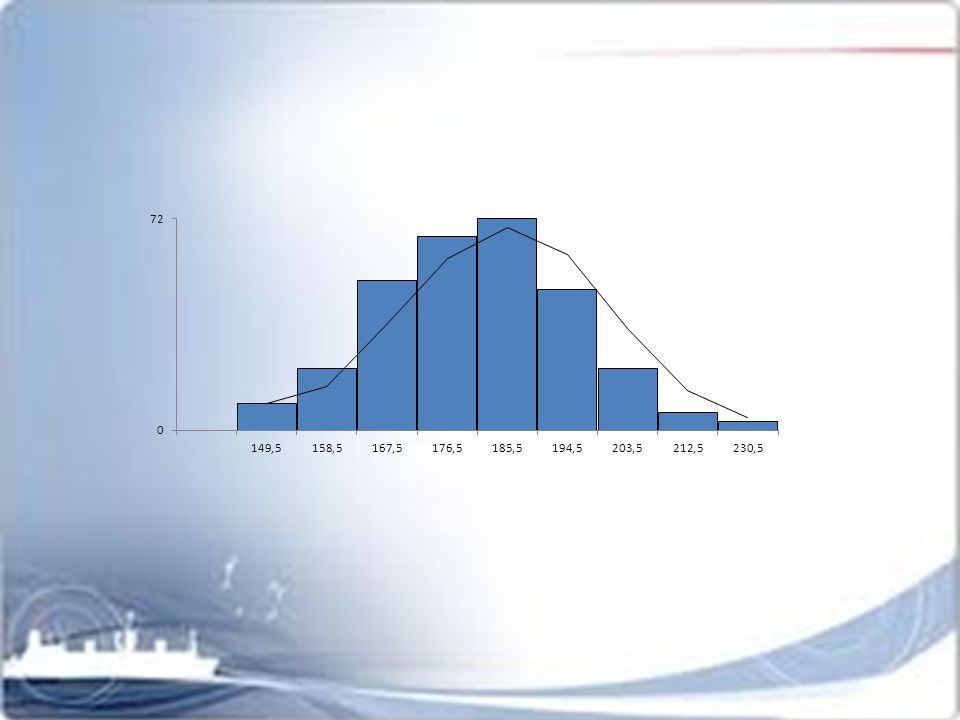
Contoh : Suatu data hasil penelitian dianggap mengikuti fungsi normal. Data dikelompokkan ke dalam 9 kelas dengan α=0,05. Ujilah hipotesis bahwa observasi mengikuti distribusi normal dengan rata-rata 184,3 dan varians 211,4116 Nilai observasi Frekuensi observasi 9 24 51 66 72 48 21 6 3

6
H0 : Distribusi pengamatan mengikuti sebaran normal
Jawab : H0 : Distribusi pengamatan mengikuti sebaran normal H1 : Distribusi pengamatan tidak mengikuti sebaran normal Nilai observasi Frekuensi observasi Oi Peluang Frekuensi harapan Ei 9 0.03 24 0,0846 25,4 51 . 51,5 66 71,2 72 67,8 48 44,6 21 20,2 6 } 9* 6,3 } 7,7* 3 1,4 300 1,0000 *) digabung karena Ei <5
 digabung karena Ei <5.")
8
Untuk mendapatkan peluang dibawah kurva normal :
x ≈ batas kelas sebenarnya : Batas bawah : dikurangi ½ Batas atas : ditambah ½ Contoh untuk batas kelas149,5 -158,5 : 𝑧 1 = 149,5−184,3 14,54 =−2,39 𝑧 2 = 158,5−184,3 14,54 =−1,77 𝑃 −2,39<𝑧<−1,77 =𝑃 𝑧<−1,77 −𝑃 𝑧<−2,39 =0,0384 −0,0084=0,03

9
-2,39 Peluang pada selang A: P(A) = 0,03 eA= P(A). N = 0,03 x 300 = 9
-1,77 A Peluang pada selang A: P(A) = 0,03 eA= P(A). N = 0,03 x 300 = 9 P(B) = P(z<-1,55)-P(z<-1,77) = 0,1230 – 0,0384 = 0,0846 eB = 0,0846 x 300 = 25,4 .
 = 0,03. eA= P(A). N = 0,03 x 300 = 9. P(B) = P(z<-1,55)-P(z<-1,77) = 0,1230 – 0,0384 = 0,0846. eB = 0,0846 x 300 = 25,4. .")
10
Statistik Uji χ 2α;(k-b) k=8 (karena ada yg digabung) b=3 χ 20,05;(5) = 11,07 χ 2ob < χ 2tabel H0 tidak ditolak :. Observasi mengikuti sebaran/fungsi normal atau fungsi normal tepat untuk dipergunakan sebagai pendekatan terhadap hasil observasi tersebut.

11
2. KOLMOGOROV SMIRNOV Diperkenalkan oleh ahli Matematik asal Rusia : A.N Kolmogorov (1933) and Smirnov (1939). Digunakan untuk ukuran sampel yang lebih kecil dan data bersifat kontinyu Intinya dalam pengujian ini, kita melihat dua fungsi distribusi kumulatif ; yaitu fungsi distribusi kumulatif teoritis (Fo(x)) dan fungsi distribusi kumulatif observasi (S(x)) Tujuan: jika perbedaan kedua fungsi kumulatif tersebut kecil, maka hipotesa bisa diterima Asumsi dlm pengujian ini: Data terdiri dari observasi yang saling bebas X1, X2, …..Xn. , yang berasal dari distribusi F(x) yang tidak diketahui
) dan fungsi distribusi kumulatif observasi (S(x)) Tujuan: jika perbedaan kedua fungsi kumulatif tersebut kecil, maka hipotesa bisa diterima. Asumsi dlm pengujian ini: Data terdiri dari observasi yang saling bebas X1, X2, …..Xn. , yang berasal dari distribusi F(x) yang tidak diketahui.")
12
Tahapan Pengujian Hipotesis: Ho : Populasi mengikuti distribusi tertentu H1: Populasi tidak mengikuti distribusi tertentu 2. Nilai statistik; n; α 3. Uji Statistik mis S(x) fungsi distribusi dari sampel (observasi); S(x) = proporsi dari observasi sampel yang lebih kecil atau sama dengan x = jumlah dari observasi sampel kurang dari atau sama dengan x n D = maks I F(x) – S(x) I D = nilai tertinggi dari perbedaan antara S(x) dan F(x) 4. Wilayah Kritis D > D tabel (Tabel Kolmogorov Smirnov)
 fungsi distribusi dari sampel (observasi); S(x) = proporsi dari observasi sampel yang lebih kecil atau sama dengan x. = jumlah dari observasi sampel kurang dari atau sama dengan x. n. D = maks I F(x) – S(x) I. D = nilai tertinggi dari perbedaan antara S(x) dan F(x) 4. Wilayah Kritis. D > D tabel (Tabel Kolmogorov Smirnov)")
13
5. Penghitungan Stat. 6. Keputusan Tolak Ho pada suatu taraf nyata tertentu jika uji stat D, melebihi 1-α yg ditunjukkan pada tabel A.18 (Applied non Parametriks Stat, (Wayne Daniel, hal 571) Jika data sampel yang diambil berasal dari distribusi yang dihipotesakan, maka perbedaan antara S(x) dan F(x) tidak terlalu besar. Contoh: Grundmann et al. melaporkan berat dari 36 ginjal kelinci sebelum mereka melakukan eksperiment. Ujilah apakah sampel berasal dari distribusi normal dengan rata-rata 85 gram dan standar deviasi 15 gram (taraf nyata 5%) Data:
 Jika data sampel yang diambil berasal dari distribusi yang dihipotesakan, maka perbedaan antara S(x) dan F(x) tidak terlalu besar. Contoh: Grundmann et al. melaporkan berat dari 36 ginjal kelinci sebelum mereka melakukan eksperiment. Ujilah apakah sampel berasal dari distribusi normal dengan rata-rata 85 gram dan standar deviasi 15 gram (taraf nyata 5%) Data:")
14
Penyelesaian: Hipotesa Ho : distribusi sampel mengkuti distribusi normal H1 : distribusi sampel tidak mengikuti distribusi normal 2. Nilai stat: α = 0,05 µ = 85 σ = 15 3. Uji stat : D= Maks IF(x) – S(x) I 4. Daerah kritis : D > 0,221 5. Stat hitung: Menghitung S(x)
 – S(x) I. 4. Daerah kritis : D > 0, Stat hitung: Menghitung S(x)")
15
x f(x) S(x) 58 1 1/36 =0,0278 78 92 59 2/36 =0,0556 80 2 93 67 3/36 = 0,0833 82 94 68 3 6/36 = 0,1667 83 97 70 4 …… 84 98 74 ……. 86 104 75 88 110 76 90 112 1,000

16
Menghitung F(x) x Z=(x-85)/15 P(0≤Z≤x) F(x)=P(z<value) 58 -1,80
0,4641 0,0359 = 0,5-0,4641 59 -1,73 0,4582 0,0418 .. 84 -0,07 0,0279 0,4721 = 0,5 – 0,0279 86 0,07 0,5279 = 0,5 + 0,0279 ….. … 104 1,27 0,3980 0,8980 110 1,67 0,4525 0,9525 112 1,80 0,9641

17
Menghitung I F(x) – S(x)I
58 0,0278 0,0359 0,0081 59 0,0556 0,0418 0,0138 .. 84 0,6111 0,4721 0,1390 86 0,6389 0,5279 0,1110 ….. … 104 0,9444 0,8980 0,0464 110 0,9722 0,9525 0,0197 112 1,000 0,9641

18
D = Maks IF(x) – S(x) I = 0,1390 = 0,14 Keputusan : tidak tolak Ho, karena D < 0,221 (Tabel Kolmogorov Smirnov) Kesimpulan : data sampel berasal dari distribusi normal dengan µ = 85 dan σ= 15 NOTE: Ketika KS digunakan untuk menguji hipotesa bahwa sampel diambil dari suatu populasi dengan paramater yang tidak diketahui, maka KS kurang baik hasilnya. Untuk alasan tersebut Tabel KS telah dibangun untuk memberikan hasil yang lebih baik dalam pengujian tersebut, salah satunya Liliefors. Asumsi : data terdiri dari observasi yang saling bebas, X1, X2, …, Xn yang berasal dari suatu distribusi yang tidak diketahui rata-rata (µ) dan variannya (σ). Untuk itu perlu dilakukan estimasi dari data sampel.
 dan variannya (σ). Untuk itu perlu dilakukan estimasi dari data sampel.")
19
3. LILIEFORS TEST Uji kenormalan untuk sampel kecil
Jika terdapat sampel berukuran n, ; x1, x2, … , xn apakah sampel tersebut menyebar normal ? uji kenormalan Tahapan pengujian Liliefors sama dengan KS Hipotesis : H0 : Populasi mengikuti sebaran normal H1 : Populasi tidak mengikuti sebaran normal Statistik uji L = maks IF(x) - S(x)| Daerah ktitik Tolak H0 jika L > Lα(n) lihat tabel Liliefors
 - S(x)| Daerah ktitik. Tolak H0 jika L > Lα(n) lihat tabel Liliefors.")
20
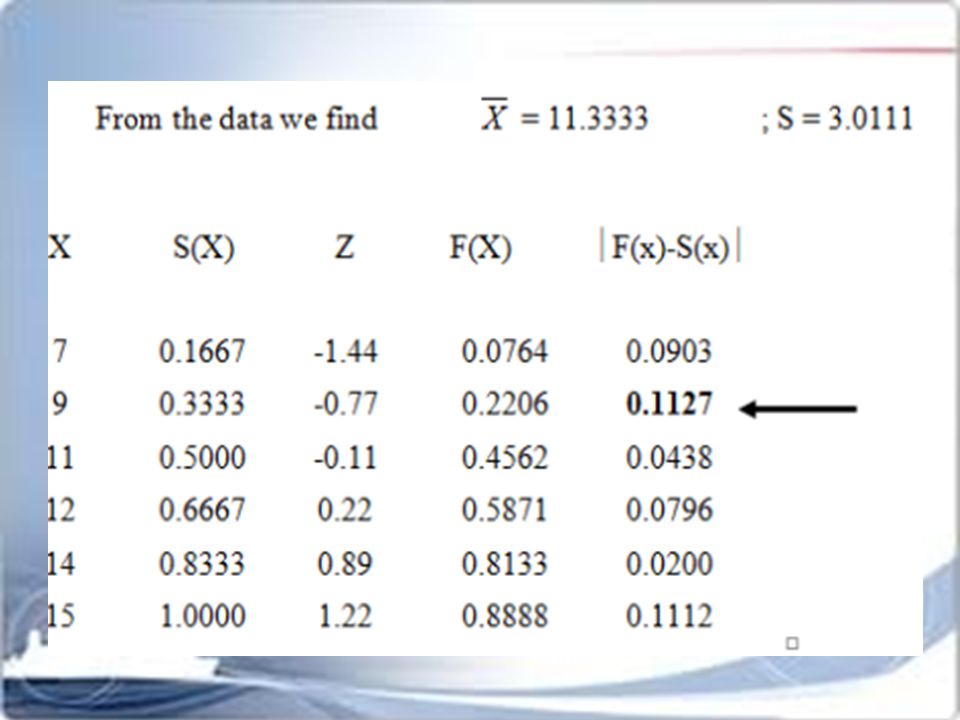
Contoh : Contoh acak berukuran n= 6 dengan nilai pengamatan 7, 9, 11, 12, 14, 15. Apakah populasi sampel tersebut menyebar normal ? Jawab : H0 : Populasi mengikuti sebaran normal H1 : Populasi tidak mengikuti sebaran normal

23
Lα(n) = L0,05(6) 0,319 L = maks IF(x) – S(x) I = 0,1127 Karena L < L0,05(6) tidak ditolak H0 :. Populasi dapat dianggap mengikuti distribusi normal

24
Latihan soal: 1. Sampel acak berukuran 7 dengan pengamatan 4, 7, 10, 4, 8, 12 dan 9. Ujilah apakah pengamatan tersebut berdistribusi normal? 2. Data berikut menunjukkan waktu yang digunakan oleh 16 pegawai perakitan dalam mengoperasikan suatu proses tertentu 5,8 7,3 8,9 7,1 8,6 6,4 7,2 5,2 10,1 8,6 9,0 9,3 6,4 7,1 9,9 6,8 Dapatkah kita menyimpulkan bahwa waktu yang diperlukan tersebut mengikuti/berasal dari distribusi normal? Gunakan taraf nyata = 0,05






>")
>")
 Stat Mat II 8/06/2011Rahma Fitriani, S.Si., M.Sc.>")










>")


