Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Gambar Kerangka dari sistem temu-kembali informasi sederhana

2
Metodologi Indexing Teks
Weighting Gambar. Metodologi Indexing Text

3
Tokenization adalah tugas memisahkan deretan kata di dalam kalimat,
Tokenizing Tokenization adalah tugas memisahkan deretan kata di dalam kalimat, paragraf atau halaman menjadi token atau potongan kata tunggal atau termmed word. Tahapan ini juga menghilangkan karakter-karakter tertentu seperti tanda baca dan mengubah semua token ke bentuk huruf kecil (lower case). Gambar. Flowchart Tokenization
. Gambar. Flowchart Tokenization.")
4
Untuk pemisahan kalimat ke bentuk kata menggunakan fungsi PHP
explode(). Pseudocode : explode(“ “, “Dua layanan populer milik Google”);
. Pseudocode : explode( , Dua layanan populer milik Google );")
5
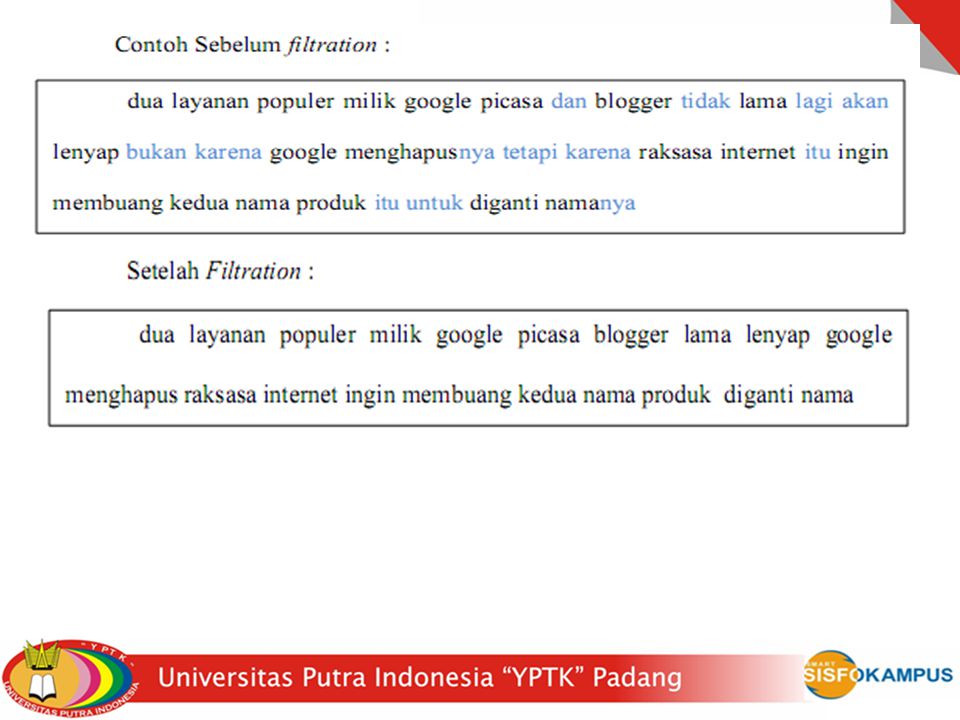
B. Filtering Tahap filtering adalah tahap pengambilan kata-kata yang penting dari hasil tokenizing. Tahap filtering ini menggunakan daftar stoplist atau wordlist. Tahap filtering adalah proses penghapusan kata buang yaitu kata sambung, kata depan, kata ganti, dll. Contoh stop words dalam bahasa Indonesia : yang, juga, dari, dia, kami, kamu, aku, saya, ini, itu, atau, dan, tersebut, pada, dengan, adalah, yaitu, ke, tak, tidak, di, pada, jika, maka, ada, pun, lain, saja, hanya, namun, seperti, kemudian, karena, untuk, dll. Proses filtration menggunakan fungsi PHP : str_replace(). Dibawah ini adalah array stopword yang telah di inputkan beserta contoh penggunaan fungsi str_replace() :
. Dibawah ini adalah array stopword yang telah di inputkan beserta contoh penggunaan fungsi str_replace() :")
7
Data array akan dibaca oleh fungsi foreach :
$teks adalah dokumen berita yana akan diproses oleh filtration. Dibawah ini flowchart proses filtration : Gambar. Flowchart Filtration

9
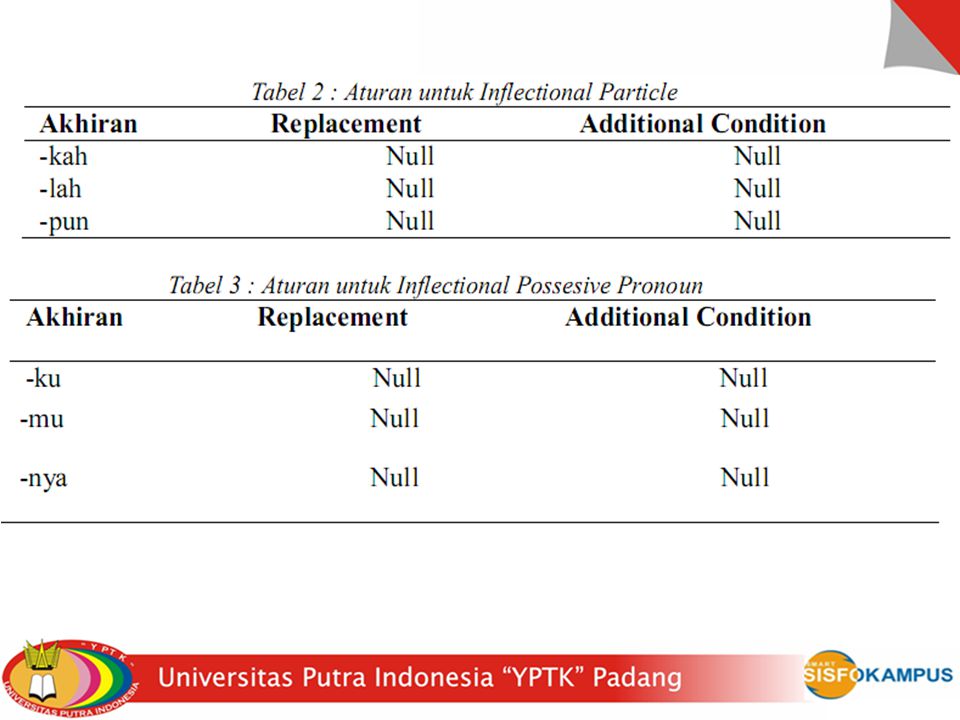
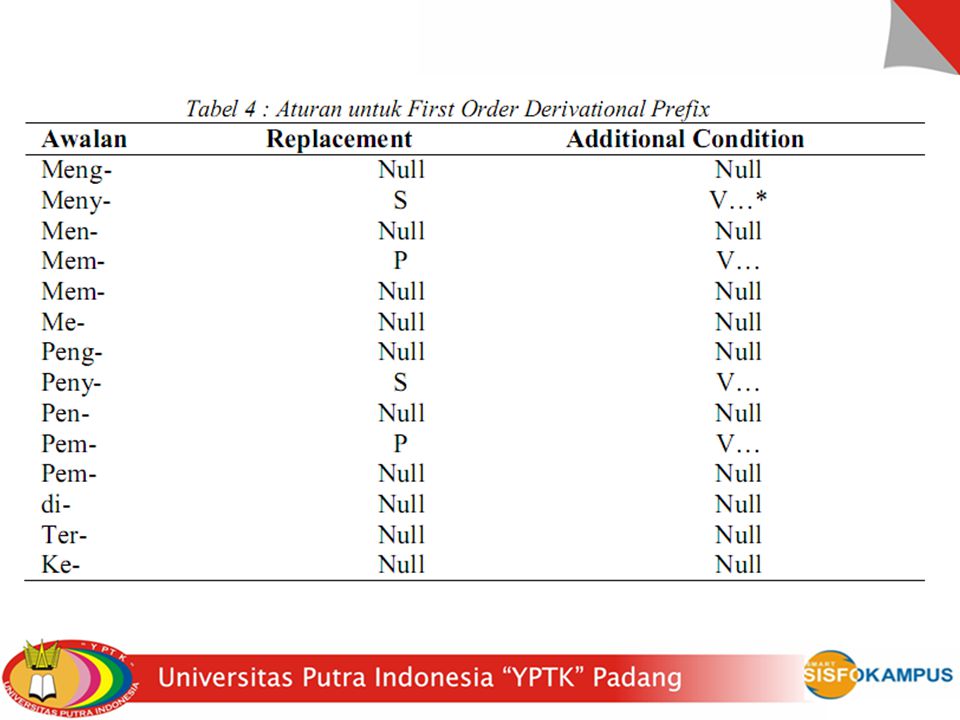
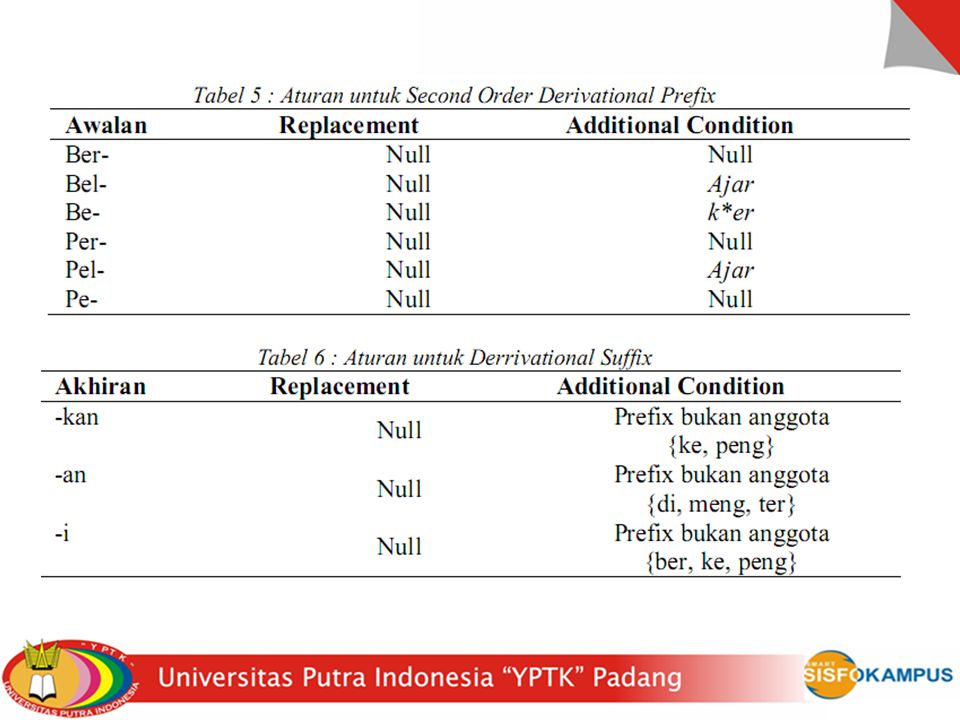
C. Stemming Stemming adalah proses mengubah kata menjadi kata dasarnya dengan menghilangkan imbuhan-imbuhan pada kata dalam dokumen. Stemming disini menggunakan kamus daftar kata berimbuhan yang mempunyai kata dasarnya dengan cara membandingkan kata-kata yang ada dalam dokumen berita dengan daftar kamus stem. Proses stemming menggunakan fungsi PHP str_replace. Berikut ini adalah contoh penggunaanya :

10
Gambar Flowchart Stemming

11
Contoh kamus stemming :
Tabel. Kamus Stem

16
D. Indexing Teks dokumen yang telah melalui proses tokenizing, filtering, dan stemming, kemudian di-indeks ke dalam database.

17
Weighting Pembobotan kata sangat berpengaruh dalam menentukan kemiripan antara dokumen dengan query. Apabila bobot tiap kata dapat ditentukan dengan tepat, diharapkan hasil perhitungan kemiripan teks akan menghasilkan perangkingan dokumen yang baik. Bobot term di dalam Information Retrieval System (W) dihitung menggunakan tf-idf yang didefinisikan sebagai berikut.
 dihitung menggunakan tf-idf yang didefinisikan sebagai berikut.")
18
t = kata ke-t dari kata kunci
Algoritma TF/IDF (Term Frequency – Inversed Document Frequency) Pada algoritma TF/IDF digunakan rumus untuk menghitung bobot (W) masing - masing dokumen terhadap kata kunci dengan rumus yaitu Dimana: d = dokumen ke-d t = kata ke-t dari kata kunci W = bobot dokumen ke-d terhadap kata ke-t tf = banyaknya kata yang dicari pada sebuah dokumen IDF = Inversed Document Frequency IDF = log10(D/df) D = total dokumen df = banyak dokumen yang mengandung kata yang dicari
 Pada algoritma TF/IDF digunakan rumus untuk menghitung bobot (W) masing - masing dokumen terhadap kata kunci dengan rumus yaitu. Dimana: d = dokumen ke-d. t = kata ke-t dari kata kunci. W = bobot dokumen ke-d terhadap kata ke-t. tf = banyaknya kata yang dicari pada sebuah dokumen. IDF = Inversed Document Frequency. IDF = log10(D/df) D = total dokumen. df = banyak dokumen yang mengandung kata yang dicari.")
19
Kata kunci (kk) = pengetahuan logistik
Setelah bobot (W) masing-masing dokumen diketahui, maka dilakukan proses sorting/pengurutan dimana semakin besar nilai W, semakin besar tingkat similaritas dokumen tersebut terhadap kata kunci, demikian sebaliknya. Contoh implementasi sederhana dari TF-IDF adalah sebagai berikut: Kata kunci (kk) = pengetahuan logistik Dokumen 1 (D1) = manajemen transaksi logistik Dokumen 2 (D2) = pengetahuan antar individu Dokumen 3 (D3) = dalam manajemen pengetahuan terdapat transfer pengetahuan logistik Jadi jumlah dokumen (D) = 3 Setelah dilakukan tahap tokenizing dan proses filtering, maka kata antar pada dokumen 2 serta kata dalam dan terdapat pada dokumen 3 dihapus. Berikut ini adalah tabel perhitungan TF/IDF
 masing-masing dokumen diketahui, maka dilakukan proses sorting/pengurutan dimana semakin besar nilai W, semakin besar tingkat similaritas dokumen tersebut terhadap kata kunci, demikian sebaliknya. Contoh implementasi sederhana dari TF-IDF adalah sebagai berikut: Kata kunci (kk) = pengetahuan logistik. Dokumen 1 (D1) = manajemen transaksi logistik. Dokumen 2 (D2) = pengetahuan antar individu. Dokumen 3 (D3) = dalam manajemen pengetahuan terdapat transfer pengetahuan. logistik. Jadi jumlah dokumen (D) = 3. Setelah dilakukan tahap tokenizing dan proses filtering, maka kata antar pada dokumen 2 serta kata dalam dan terdapat pada dokumen 3 dihapus. Berikut ini adalah tabel perhitungan TF/IDF.")
20
bobot (W) untuk D1 = ? bobot (W) untuk D2 = ? bobot (W) untuk D3 = ?
 untuk D1 = bobot (W) untuk D2 = bobot (W) untuk D3 =")
21
Dari contoh studi kasus di atas, dapat diketahui bahwa nila i bobot (W) dari D1 dan
D3 adalah sama. Apabila hasil pengurutan bobot dokumen tidak dapat mengurutkan secara tepat, karena nilai W keduanya sama, maka diperlukan proses perhitungan dengan algoritma vector-space model. Ide dari metode ini adalah dengan menghitung nilai cosinus sudut dari dua vektor, yaitu W dari tiap dokumen dan W dari kata kunci.

22
StopList dan Stemming

23
Sistem Temu-Balik Informasi
Sistem temu-balik informasi pada prinsipnya adalah suatu sistem yang sederhana. Misalkan ada sebuah kumpulan dokumen dan seorang user yang memformulasikan sebuah pertanyaan (request atau query). Jawaban dari pertanyaan tersebut adalah sekumpulan dokumen yang relevan dan membuang dokumen yang tidak relevan. Secara matematis hal tersebut dapat dituliskan sebagai berikut :
. Jawaban dari pertanyaan tersebut adalah sekumpulan dokumen yang relevan dan membuang dokumen yang tidak relevan. Secara matematis hal tersebut dapat dituliskan sebagai berikut :")
24
Prinsip Sistem Temu kembali Informasi
C. Matcher Machine (Sistem Temu kembali informasi) A. Document B. Query MATCH (SESUAI) Dokumen (Relevan or not Relevan) Representasi Representasi (Kata kunci) (Kata kunci)
 A. Document. B. Query. MATCH. (SESUAI) Dokumen (Relevan or not Relevan) Representasi. Representasi. (Kata kunci) (Kata kunci)")
25
Sistem Temu Kembali Informasi
Prinsip Sistem Temu kembali Informasi Pertanyaan Pengguna Document Query Document Pustakawan Analisis Query Analisis Dokumen Seperangkat Istilah (terkontrol atau bebas) Sistem Temu kembali Informasi Seperangkat Istilah (terkontrol atau bebas) Basisdata/Metadata (Record)` (E-book, E-journal, OPAC etc (E-book, E-journal, OPAC etc
 Sistem Temu. kembali Informasi. Seperangkat Istilah (terkontrol atau bebas) Basisdata/Metadata. (Record)` (E-book, E-journal, OPAC etc. (E-book, E-journal, OPAC etc.")
26
Kesesuaian (Matching)
Perbandingan istilah query dan Dokumen Exact match : sesuai antara Query dan Dokumen Library automation {query} Library automation {Dokumen} Partial Match : sebagian sesuai antara Query dan Dokumen (trancation. +, *) lib+ and auto+ atau lib* and auto* Dokumen paling mirip dengan query ditempatkan paling atas dan probabilitas relevansinya cukup tinggi dengan query
 lib+ and auto+ atau lib* and auto* Dokumen paling mirip dengan query ditempatkan paling atas dan probabilitas relevansinya cukup tinggi dengan query.")
27
Efektifitas Sistem Temu Kembali
Penyimpanan dokumen dlm bentuk terstruktur dan tidak terstruktur Bahasa Pengindekan (terkendali & bebas) Kebutuhan Informasi pengguna (Query) Strategi penelusuran (Search Profile) Kumpulan dokumen yang Ditemukan (sedikit & banyak) Evaluasi Relevansi (Relevant judment) : Penilaian individu Berbeda
 Kebutuhan Informasi pengguna (Query) Strategi penelusuran (Search Profile) Kumpulan dokumen yang Ditemukan (sedikit & banyak) Evaluasi Relevansi (Relevant judment) : Penilaian individu Berbeda.")
28
indexing Sistem temu-kembali informasi pada dasarnya dibagi dalam dua komponen utama yaitu sistem pengindeksan (indexing) yang menghasilkan basis data sistem dan temukembali yang merupakan gabungan dari user interface dan look-up-table. Indexing merupakan sebuah proses untuk melakukan pengindeksan terhadap kumpulan dokumen yang akan disediakan sebagai informasi kepada pemakai. Proses pengindeksan bisa secara manual ataupun secara otomatis.
 yang menghasilkan basis data sistem dan temukembali yang merupakan gabungan dari user interface dan look-up-table. Indexing merupakan sebuah proses untuk melakukan pengindeksan terhadap kumpulan dokumen yang akan disediakan sebagai informasi kepada pemakai. Proses pengindeksan bisa secara manual ataupun secara otomatis.")
29
Tahapan Pengindeksan Parsing Dokumen yaitu proses pengambilan kata-kata dari kumpulan dokumen. Stoplist yaitu proses pembuangan kata buang seperti: tetapi, yaitu, sedangkan, dan sebagainya. Stemming yaitu proses penghilangan/ pemotongan dari suatu kata menjadi bentuk dasar. Kata “diadaptasikan” atau “beradaptasi” mejadi kata “adaptasi” sebagai istilah. Term Weighting dan Inverted File yaitu proses pemberian bobot pada istilah.

30
Teknik pembobotan 1. Teknik pembobotan berdasarkan frekuensi kemunculan istilah pada satu dokumen. Teknik pembobotan ini cukup sederhana dimana bobot suatu istilah pada sebuah dokumen berdasarkan jumlah kemunculannya pada dokumen tersebut. 2. Teknik pembobotan berdasarkan rumus yaitu:

31
.....Teknik pembobotan Dimana :
Wik adalah bobot istilah k pada dokumen i. tfik merupakan frekuensi dari istilah k dalam dokumen i. n adalah jumlah dokumen dalam kumpulan dokumen. dfk adalah jumlah dokumen yang mengandung istilah k. Max j tf ij adalah frekuensi istilah terbesar pada satu dokumen.

32
teknik temu-kembali informasi
Ada beberapa teknik temu-kembali informasi yang telah dikembangkan yaitu teknik Boolean sederhana dan teknik Boolean berperingkat serta teknik Extended Boolean

33
Teknik Boolean Teknik Boolean merupakan suatu cara dalam mengekspresikan keinginan pemakai ke sebuah kueri dengan mamakai operator-operator Boolean yaitu : “and”, “or”, dan “not”. Adapun maksud dari operator “and” adalah untuk menggabungkan istilah-istilah kedalam sebuah ungkapan, dan operator “or” adalah untuk memperlakukan istilah-istilah sebagai sinonim, sedangkan operator “not” merupakan sebuah pembatasan. Teknik Boolean sederhana, kueri diproses sesuai dengan operator yang digunakan dan menampilkan dokumen berdasarkan urutan dokumen ditemukan. Teknik Boolean berperingkat, dokumen diperingkat berdasarkan bobot dari dokumen. Adapun pembobotan dari masing-masing dokumen berdasarkan aturan sebagai berikut :

34
...Komponen Sistem IR Dimana dA menyatakan bobot istilah A pada dokumen D. Bobot istilah ini didapat dari hasil proses Indexing. Min(dA,dB) berarti bahwa sebuah dokumen di retrieve dengan bobot sebesar nilai terkecil dari bobot-bobot istilah yang dipunyainya. Max(dA,dB) berarti bahwa sebuah dokumen di retrieve dengan bobot sebesar nilai terbesar dari bobot-bobot istilah yang dipunyainya.
 berarti bahwa sebuah dokumen di retrieve dengan bobot sebesar nilai terkecil dari bobot-bobot istilah yang dipunyainya. Max(dA,dB) berarti bahwa sebuah dokumen di retrieve dengan. bobot sebesar nilai terbesar dari bobot-bobot istilah yang dipunyainya.")
35
Teknik Extended Boolean
Teknik Extended Boolean berdasarkan p-norm model merupakan pengembangan lebih lanjut dari model Boolean. Teknik ini memakai operator yangdikomputasi berdasarkan rumus Savoy, sebagai berikut :

36
Sistem Pencarian Web

37
Area Terkait • Manajemen Basis Data • Ilmu Perpustakaan dan Informasi
• Kecerdasan Buatan • Pemrosesan bahasa alamai • Pembelajaran Mesin

38
Relevansi Relevansi merupakan suatu judgment (keputusan) subyektif dan dapat didasarkan pada: – topik yang tepat. – waktu (informasi terbaru). – otoritatif (dari suatu sumber terpercaya). – kebutuhan informasi dari pengguna. Kriteria relevansi utama: suatu sistem IR sebaiknya (harus) memenuhi kebutuhan informasi pengguna.
. – otoritatif (dari suatu sumber terpercaya). – kebutuhan informasi dari pengguna. Kriteria relevansi utama: suatu sistem IR sebaiknya (harus) memenuhi kebutuhan informasi pengguna.")
39
Pencarian Keyword Ide paling sederhana dari relevansi: apakah string query ada di dalam dokumen (kata demi kata, verbatim)? Ide yang lebih fleksibel: Berapa sering kata-kata di dalam query muncul di dalam dokumen, tanpa melihat urutannya (bag of words)?
")
40
Masalah dengan Keyword
Mungkin tidak meretrieve dokumen relevan yang menyertakan synonymous terms. – “restaurant” vs. “café” – “NDHU” vs. “National Dong Hwa University” Mungkin meretrieve dokumen tak-relevan yang menyertakan ambiguous terms. – “bat” (baseball vs. mamalia) – “Apple” (perusahaan vs. buah-buahan) – “bit” (unit data vs. perilaku menggigit)
 – Apple (perusahaan vs. buah-buahan) – bit (unit data vs. perilaku menggigit)")
41
Bukan Sekedar Keyword Kita akan mendiskusikan dasar-dasar IR berbasis keyword, tetapi… – Fokus pada perluasan dan pengembangan terakhir untuk mendapatkan hasil terbaik. Kita akan membahas dasar-dasar pembangunan sistem IR yang efisien, tetapi… – Fokus pada algoritma dan kemampuan dasar, bukan masalah sistem yang memungkinkan pengembangan ke database ukuran industri.

42
IR Cerdas Memanfaatkan pengertian atau makna dari kata yang digunakan.
Melibatkan urutan kata di dalam query. Beradaptasi dengan pengguna berdasarkan pada feedback, langsung atau tidak langsung. Memperluas pencarian dengan term terkait. Mengerjakan pemeriksaan ejaaan/perbaikan tanda pengenal otomatis. Memanfaatkan Otoritas dari sumber informasi.

43
Indeks Sistem IR jarang mencari koleksi dokumen secara langsung. Berdasarkan pada koleksi dokumen, dibangun sebuah index. Pengguna mencari index tersebut.

44
Indexing Otomatis Tujuan dari automatic indexing adalah membangun index dan meretrieve informasi tanpa intervensi manusia. Ketika informasi yang dicari adalah teks, metode automatic indexing akan sangat efektif. Penelitian automatic indexing fundamental dimulai oleh Gerald Salton, Professor of Computer Science di Cornell & mahasiswa Pasca-Sarjananya (Sistem SMART).
.")
45
IR dari Koleksi Besar Information retrieval dari koleksi sangat besar bersandar pada: – Jumlah computer power yang besar untuk mengerjakan algoritma sederhana terhadap jumlah data yang sangat banyak. komputasi kinerja-tinggi – Pemahaman pengguna terhadap informasi dan kemampuan dari sistem. Interaksi manusia - komputer Machine-learning banyak digunakan untuk mendapatkan kinerja terbaik.

46
Searching & Browsing • Orang dalam perulangan

47
IR dari Koleksi Dokumen Teks
Kategori utama dari metode: – Ranking kemiripan terhadap query (vector space model). – Pencocokan exact (Boolean). – Ranking berdasarkan tingkat kepentingan dokumen (PageRank) – Kombinasi beberapa metode Contoh: Web search engine, seperti Google & Yahoo, menggunakan metode kombinasi, berdasarkan pada pendekatan pertama dan ketiga, dengan kombinasi exact dipilih menggunakan machine learning
. – Pencocokan exact (Boolean). – Ranking berdasarkan tingkat kepentingan dokumen (PageRank) – Kombinasi beberapa metode. Contoh: Web search engine, seperti Google & Yahoo, menggunakan metode kombinasi, berdasarkan pada pendekatan pertama dan ketiga, dengan kombinasi exact dipilih menggunakan machine learning.")
48
Istilah Penting Information retrieval: sub-bidang ilmu komputer yang berurusan dengan penemuan kembali dokumen (khususnya teks) terotomatis berdasarkan pada content dan contextnya. Searching: Pencarian informasi spesifik di dalam badan informasi. Hasilnya adalah sehimpunan hit. Browsing: Eksplorasi tak-terstruktur dari badan informasi. Linking: Berpindah dari satu item ke item lain mengikuti link (sambungan) seperti rujukan (referensi).
 terotomatis berdasarkan pada content dan contextnya. Searching: Pencarian informasi spesifik di dalam badan informasi. Hasilnya adalah sehimpunan hit. Browsing: Eksplorasi tak-terstruktur dari badan informasi. Linking: Berpindah dari satu item ke item lain mengikuti link (sambungan) seperti rujukan (referensi).")
49
...Istilah Query: Suatu string teks, menggambarkan informasi yang sedang dicari pengguna. Setiap kata dari query dinamakan search term. Query dapat berupa search term tunggal, string dari term, frase atau ekspresi tertentu menggunakan simbol khusus, misalnya regular expression. Pencarian Full text: Metode yang membandingkan query dengan setiap kata di dalam teks, tanpa membedakan fungsi dari berbagai kata. Pencarian Bidang : Metode pencarian pada bidang struktural atau bibliografis spesifik, seperti penulis atau judul.

50
...Istilah Corpus: Koleksi dokumen yang diindeks dan dijadikan target pencarian. Daftar kata: Himpunan semua term yang digunakan dalam indeks untuk suatu corpus (dikenal sebagai vocabulary file). Pada pencarian full text, word list adalah semua term di dalam corpus, stop words dihapus. Term- term terkait dikombinasi dengan stemming. Controlled vocabulary: Metode indexing dimana word list bersifat tetap. Term-term dari vocabulary tersebut dipilih untuk mendeskripsikan setiap dokumen. Keyword: Nama untuk term-term dalam word list, terutama dengan controlled vocabulary
. Pada pencarian full text, word list adalah semua term di dalam corpus, stop words dihapus. Term- term terkait dikombinasi dengan stemming. Controlled vocabulary: Metode indexing dimana word list bersifat tetap. Term-term dari vocabulary tersebut dipilih untuk mendeskripsikan setiap dokumen. Keyword: Nama untuk term-term dalam word list, terutama dengan controlled vocabulary.")
51
Mengurutan & Ranking Hit
Ketika pengguna men-submit suatu query ke sistem IR, sistem mengembalikan sehimpunan hit. Pada koleksi dokumen besar, himpunan hit akan sangat besar. Nilai untuk pengguna sering tergantung pada urutan hit ditampilkan. Tiga metode utama: – Mengurutkan hit, misal berdasarkan tanggal – Meranking hit berdasarkan kemiripan antara query dan dokumen – Meranking hit berdasarkan kepentingan dari dokumen

52
IR Berbasis Teks Sebagian besar metode ranking didasarkan pada model ruang vektor (vector space model). Sebagian besar metode pencocokan (matching) didasarkan ada operator Boolean. Metode Web search mengkombinasikan model ruang vektor dengan ranking berdasarkan pada tingkat kepentingan dokumen. Banyak sistem (dalam praktek) menggabungkan fitur- fitur dari beberapa pendekatan. Pada bentuk dasar, semua pendekatan menganggap kata sebagai token terpisah, dengan usaha minimal untuk memahami kata-kata secara linguistik.
 didasarkan ada operator Boolean. Metode Web search mengkombinasikan model ruang vektor dengan ranking berdasarkan pada tingkat kepentingan dokumen. Banyak sistem (dalam praktek) menggabungkan fitur- fitur dari beberapa pendekatan. Pada bentuk dasar, semua pendekatan menganggap kata sebagai token terpisah, dengan usaha minimal untuk memahami kata-kata secara linguistik.")
53
Frekuensi Kata Observasi: Beberapa kata lebih umum daripada yang lain.
Statistika: Koleksi sangat besar dari dokumen teks tak-terstruktur mempunyai karakteristik statistik serupa. Statistik ini: – Mempengaruhi efektifitas dan efisiensi dari struktur data yang digunakan untuk mengindeks dokumen – Banyak model retrieval memanfaatkannya

54
...Frekuensi Kata Contoh: Contoh berikut ini diambil dari :
– Jamie Callan, Characteristics of Text, 1997 – 19 Juta kata sampel – Slide berikut memperlihatkan 50 kata yang paling umum, diranking (r) berdasarkan frekuensinya (f).
 berdasarkan frekuensinya (f).")
55
...Frekuensi Kata

56
Distribusi Ranking Frekuensi
Untuk semua kata di dalam suatu dokumen, untuk setiap kata w – f adalah frekuensi munculnya w – r ranking dari w disusun menurut frekuensi. (kata yang paling umum muncul mempunyai rank =1)
")
57
Contoh Frekuensi Rank Slide berikut memperlihatkan kata-kata di dalam data Callan yang telah dinormalisasi. Dalam contoh ini: – r adalah ranking dari kata w dalam sampel. – f adalah frekuensi kata w di dalam sampel. – n adalah jumlah total kemunculan kata di dalam sampel.

58
...Contoh Ranking Frekuensi

Presentasi serupa











 Modul 11 Muslech, Dipl.Lib, MSi 3 Desember 2012.>")
 Syafri Arlis, S.Kom, M.Kom>")







>")
