Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
APLIKASI KOMPUTER LANJUTAN TEORI DAN PRAKTEK
Zaenal Wafa |

2
Silabus Kuliah Pengenalan SPSS
Tipe Data Statistik dan Statistik Deskriptif One Sample T. Test Independent T.Test One Way Anova Regresi Regresi Berganda Korelasi Validitas & Realibilitas Uji Asumsi Klasik Analisis Jalur MRA

3
Penilaian Variabel Penilaian : 1. Tugas 2. Quiz 3. UTS 4. UAS 5. Tugas Akhir

4
Kontrak Belajar Batas keterlambatan saudara 15 menit
Berpakaian Rapi dan Sopan Selama Perkuliahan berlangsung di harapkan tidak kelur masuk kelas

5
Tipe Data Statistik dan Statistik Deskriptif
PERTEMUA KE - 1 Tipe Data Statistik dan Statistik Deskriptif

6
Cont.. Dalam melakukan analysis data , kita harus memahami terlebih dahulu konsep dari jenis data statistik yaitu numeric dan kategorik. Data numeric adalah data yang berbentuk angka ( kombinasi dari 0,1,2..9 ) dan merupakan gambaran hasil mengukur atau menghitung. Data Kategorik merupakan data yang berbentuk peryataan, kualitas, atau pengelompokan misal (laki/perempuan, baik/buruk, setuju/tidak, SD/SMP/SMA/PT/, dls)
 dan merupakan gambaran hasil mengukur atau menghitung. Data Kategorik merupakan data yang berbentuk peryataan, kualitas, atau pengelompokan misal (laki/perempuan, baik/buruk, setuju/tidak, SD/SMP/SMA/PT/, dls)")
7
Statistik deskriptif Statistik deskriptif berupa frekuensi dan nilai-nilai pusat (central tendency). Frekuensi biasanya dimunculkan dalam bentuk proporsi atau persentase untuk data atau variabel kategorik. Sedangkan nilai pusat berupa nilai tengah dan nilai sebaran (mean, median, dll) untuk data atau variabel numerik.
 untuk data atau variabel numerik.")
8
Cont.. Analysis data numeric akan berbeda dengan analysis data kategorik, termasuk termasuk penyajian dan interprestasinya. Data numeric biasanya disajikan dalam bentuk nilai tengah dan nilai sebaran ( misal rata-rata dan standart deviasi ) sedangkan nilai kategorik ditampilkan dalam bentuk persen.
 sedangkan nilai kategorik ditampilkan dalam bentuk persen.")
9
LATIHAN : Berikut ini adalah Buku Kode yang memuat variabel, keterangan dan value yang mempengaruhi berat bayi lahir. Instruksi : simpan file saudara dengan nama Pertemuan1.

10
BUKU KODE

11
VARIABEL VIEW SPSS

12
DATA VIEW SPSS

13
ANALYSIS DESKRIPTIF DATA KATEGORIK
Cara yang paling sering digunakan adalah dengan mengunakan tabel frekuensi. Langkahnya : Pada Menu Bar, Klik ANALYZE > DESCRIPTIVE > FREQUENCIES … Pada sehingga akan ditampuilkan layar sebagai berikut :

14
2 1

15
3

16
RESULT :

17
Cont.. Pada kolom Frequency menunjukkan jumlah kasus dengan nilai yang sesuai, jadi pada contoh diatas, terdapat 3 ibu yang berpendidikan SD dari 12 Ibu yang ada, Proporsi yang dapat dilihat dari kolom Percent pada kolom diatas adalah 25,0% ibu yang berpendidikan SD Kolom Valid Percen menampilkan proporsi jika missing cases tidak diikutsertakan yaitu 25,0% Kolom Comulative Percen menjelaskan tetang persen komulatif, jadi pada contoh diatas ada 75,0% ibu yang perpendidikan SD – SMP ( 25,0% + 50 ,0%)
")
18
PENYAJIAN DATA KATEGORIK
Penyajian data mempunyai prinsip efisiensi, Sajikan hanya informasi Penting saja. Contoh :

19
LATIHAN ANALYSIS DATA KATEGORIK
Buatlah tabel distribusi frekuensi untuk variabel HT , ROKOK dan bblr Diminta : a. Sajikan, b. Interpretasikan

20
ANALYSIS DESKRIPTIF DATA NUMERIK
Pertemuan ke-2 ANALYSIS DESKRIPTIF DATA NUMERIK

21
ANALYSIS DESKRIPTIF DATA NUMERIK
Pada data numerik atau kontinyu, peringkasan data dapat dilakukan dengan melaporkan ukuran tengah dan sebarannya. Ukuran tengah yang dapat digunakan adalah : rata-rata, median dan modus. Sedangkan ukuran sebaran yang dapat digunakan adalah : nilai minimum, maksimum, range, standar deviasi dan persentil. Dari ukuran-ukuran tersebut, yang paling sering digunakan adalah rata-rata dan standar deviasi.

22
Pada file SPSS bayi2015 diatas, lakukan langkah berikut ini :
Analyze Descriptive Statistic Descriptive … sehingga akan ditampilkan kotak dialog sbb :

23
Result Nilai rata-rata dapat dilihat pada kolom Mean, sedangkan nilai standar deviasi dapat dilihat pada Std Devation. Pada contoh di atas, rata-rata umur ibu adalah 25 tahun dengan standar deviasi 4,178 umur minimun 19 tahun serta umur maksimum 34 tahun. Dengan cara di atas, kita dapat memperoleh nilai rata-rata, minimum, maksimum serta standar deviasi. Tetapi kita tidak memperoleh nilai standar error, padahal nilai ini diperlukan untuk melakukan estimasi inteval pada parameter populasi.

24
Analyze Descriptive Statistic Descriptive … sehingga akan ditampilkan kotak dialog deskriptive sbb, kemudian klik OPTION

25
Result + Dari hasil tersebut kita dapat melakukan estimasi interval dari berat bayi. Kita dapat menghitung 95% confidence interval berat bayi, yaitu 1559,00 + 1,96 x 129,326 (mean + SE mean). Jadi kita 95% yakin bahwa rata-rata berat bayi di populasi berada pada selang sampai 1812 gram. *1,96 nilai interval standart devisiasi
. Jadi kita 95% yakin bahwa rata-rata berat bayi di populasi berada pada selang 1305 sampai 1812 gram. *1,96 nilai interval standart devisiasi.")
26
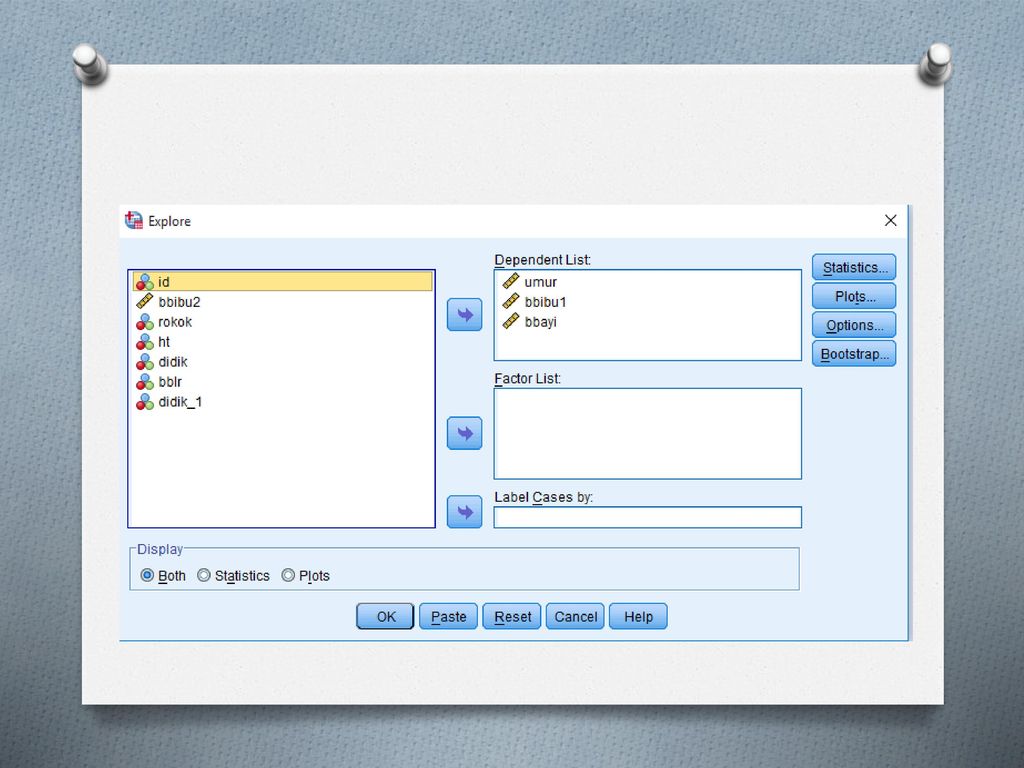
Cara yang lain untuk mengeluarkan nilai statistik deskriptif dari data numerik (nilai rata-rata/mean std. Dev) beserta 95% confidence interval adalah sebagai berikut: Dari menu utama, pilihlah: Analyze Descriptive Statistic Explore sehingga akan ditampilkan kotak dialog Explorer sebagai berikut :

29
Dari hasil tersebut kita mendapatkan estimasi titik dan estimasi interval dari variabel numerik yang diukur. Kita dapat melihat nilai rata-rata dan 95% confidence interval dari BBAYI yaitu gram ( — ), kita 95% yakin bahwa rata-rata berat bayi di populasi berada pada selang sampai gram. Nilai ini tidak jauh berbeda dengan nilai yang dihitung dari output yang didapat pada langkah slide 25 sebelumnya.
, kita 95% yakin bahwa rata-rata berat bayi di populasi berada pada selang sampai gram. Nilai ini tidak jauh berbeda dengan nilai yang dihitung dari output yang didapat pada langkah slide 25 sebelumnya..")
30
GRAFIK HISTOGRAM PADA DATA NUMERIK
Langkahnya : Klik Graph > Klik Legacy Dialog > Klik Histogram

31
Result

32
UJI NORMALITAS DISTRIBUSI DATA NUMERIK
Pengujian normalitas adalah pengujian tentang kenormalan distribusi data. Uji ini merupakan pengujian yang paling banyak dilakukan untuk analisis statistik parametrik. Karena data yang berdistribusi normal merupakan syarat dilakukannya tes parametrik. Sedangkan untuk data yang tidak mempunyai distribusi normal, maka analisisnya menggunakan tes non parametric.

33
Statistik Parametrik Parametrik dalam arti harfiah yaitu asumsi tentang parameter dari distribusi data populasi yang digunakan untuk menguji hipotesis mendekati normal atau mendekati distribusi normal setelah teorema limit sentral. Statistik Nonparametrik Non-parametrik adalah metode yang tidak mendasarkan pada asumsi distribusi populasi. Dalam arti sempit non-parametrik adalah sebuah kategori nol karena hampir semua uji statistik mengasumsikan satu atau lain hal tentang sifat-sifat populasi.

34
Klik Analyze > klik Descriptive Statistic > kemudian klik Explore…
Pada kotak dialog tersebut, pilih variabel UMUR dan BBAYI, Kemudian klik tanda panah ke kanan >, untuk memasukkannya ke kotak Dependent list berikutnya klik Plot lalu klik Histogram dan Normality plot with

35
result Tests of Normality Kolmogorov-Smirnova Shapiro-Wilk
Statistic df Sig. Statistic df Sig. umur * bbayi * * This is a lower bound of the true significance. a Lilliefors Significance Correction

36
Dengan uji Kolmogorov-Smirnov, disimpulkan bahwa pada alpha 0
Dengan uji Kolmogorov-Smirnov, disimpulkan bahwa pada alpha 0.05 distribusi data umur ibu adalah normal (nilai-p = 0.780) begitu juga dengan distribusi data berat bayi normal (nilai-p = 0.395). Apabila diperhatikan grafik HISTOGRAM maka terlihat bahwa data umur ibu memang terlihat normal, dengan grafik distribusi tidak miring ke kanan (miring positif +)
 begitu juga dengan distribusi data berat bayi normal (nilai-p = 0.395). Apabila diperhatikan grafik HISTOGRAM maka terlihat bahwa data umur ibu memang terlihat normal, dengan grafik distribusi tidak miring ke kanan (miring positif +)")
38
TRANSFORMASI DATA & T - TEST
PERTEMUAN KE 3 TRANSFORMASI DATA & T - TEST

39
Independen sample T-TEST
Uji-t untuk data independen dilakukan terhadap dua kelompok data yang tidak saling berkaitan antara satu dengan lainnya. Misalnya membandingkan kelompok intervensi dengan kelompok kontrol atau kelompok ibu-ibu perokok dengan ibu-ibu bukan perokok adalah dua kelompok yang tidak saling berkaitan. Pada analisis ini kita akan melihat apakah ada perbedaan berat bayi yang lahir dari ibu perokok dengan bayi yang lahir dari ibu bukan perokok. Kita akan melakukan uji hipotesis apakah ada perbedaan rata-rata berat bayi yang lahir dari ibu bukan perokok dengan rata-rata berat bayi yang lahir dari ibu perokok

40
Klik Pada option dan tentukan derajat kepercayaan yang diinginkan

41
Hasil tersebut memperlihatkan bahwa ada 10 ibu yang tidak perokok dan
mereka mempunyai rata-rata berat bayi sebesar gram. Sedangkan 2 ibu yang perokok melahirkan bayi yang lebih rendah beratnya daripada kelompok sebelumnya yakni dengan rata-rata gram. Uji-t independen menyajikan dua buah uji statistik. Pertama adalah uji Levene’s untuk melihat apakah ada perbedaan varians antara kedua kelompok atau tidak. Kedua adalah uji-t untuk melihat apakah ada perbedaan rata-rata kedua kelompok atau tidak. Jika p-value (Sig.) dari uji Levene’s besar dari nilai α (0.05), hal ini berarti varians kedua kelompok adalah sama, maka signifikansi uji-t yang dibaca adalah pada baris pertama (Equal variances assumed). Tetapi jika p-value dari uji Levene’s kecil atau sama dengan nilai α (0.05), hal ini berarti bahwa varians kedua kelompok adalah tidak sama, maka signifikansi uji-t yang dibaca adalah pada baris kedua (Equal variances not assumed).
 dari uji Levene’s besar. dari nilai α (0.05), hal ini berarti varians kedua kelompok adalah sama, maka signifikansi uji-t yang dibaca adalah pada baris pertama. (Equal variances assumed). Tetapi jika p-value dari uji Levene’s kecil atau. sama dengan nilai α (0.05), hal ini berarti bahwa varians kedua kelompok. adalah tidak sama, maka signifikansi uji-t yang dibaca adalah pada baris. kedua (Equal variances not assumed).")
42
Pada contoh diatas signifikansi uji Levene’s adalah 0
Pada contoh diatas signifikansi uji Levene’s adalah 0.611, berarti varians kedua kelompok adalah sama, maka hasil uji-t pada baris pertama memperlihatkan p-value (sig.) adalah untuk uji 2-sisi. (Jika uji yang kita lakukan adalah uji 1-sisi maka nilai p-value harus dikalikan 2 sehingga menjadi 0.036). Dapat kita simpulkan bahwa secara statistik rata-rata berat bayi yang lahir dari populasi ibu yang tidak perokok lebih tinggi dari populasi ibu perokok.
 adalah untuk uji 2-sisi. (Jika uji yang kita lakukan adalah uji 1-sisi maka nilai p-value harus dikalikan 2 sehingga menjadi 0.036). Dapat kita simpulkan bahwa secara statistik rata-rata berat bayi yang lahir dari populasi ibu yang tidak perokok lebih tinggi dari populasi ibu perokok.")
43
PAIRED SAMPLE T TEST (UJI BEDA DUA SAMPEL BERPASANGAN)
Paired sample t test merupakan uji beda dua sampel berpasangan. Sampel berpasangan merupakan subjek yang sama namun mengalami perlakuan yang berbeda.

44
Akan diteliti mengenai perbedaan penjualan sepeda motor merk A
CONTOH KASUS Akan diteliti mengenai perbedaan penjualan sepeda motor merk A disebuah Kabupaten sebelum dan sesudah kenaikan harga BBM. Data diambil dari 15 dealer. Data yang diperoleh adalah sebagai berikut : No Sebelum Sesudah 1 67 68 2 75 76 3 81 80 4 60 63 5 82 6 74 7 71 70 8 9 10 78 79 11 12 77 13 65 69 14 57 15

45
Klik ANALYZE > COMPARE MEANS > PAIRED SAMPLES t Tes

46
Bagian pertama. Paired Samples Statistic
Menunjukkan bahwa rata-rata penjualan pada sebelum dan sesudah kenaikan BBM. Sebelum kenaikan BBM rata-rata penjualan dari 15 dealer adalah sebanyak 72.4, sementara setelah kenaikan BBM jumlah penjualan rata-rata adalah sebesar 73.6 unit Bagian Dua. Paired samples Correlatian Hasil uji menunjukkan bahwa korelasi antara dua variabel adalah sebesar dengan sig sebesar Hal ini menunjukkan bahwa korelasi antara dua rata-rata penjualan sebelum dan sesudah kenaikan adalah kuat dan signifikan.

47
Hipotesis Hipotesis yang diajukan adalah : Ho : rata-rata penjualan adalah sama H1 : rata-rata penjualan adalah berbeda Nilai t hitung adalah sebesar degan sig Karena sig > 0.05 maka dapat disimpulkan bahwa Ho diterima, artinya rata-rata penjualan sebelum dan sesudah kenaikan BBM adalah sama (tidak berbeda). dengan demikian dapat dinyatakan bahwa kenaikan harga BBM tidak mempengaruhi jumlah penjualan sepeda motor di kabupaten A.
. dengan demikian dapat dinyatakan bahwa kenaikan harga BBM tidak mempengaruhi jumlah penjualan sepeda motor di kabupaten A.")
48
Kasus : independet sample t-test
Kasus 1 : Suatu tes dilakukan untuk melihat tingkat stress pada karyawan yang ditempatkan di ruangan berarsitektur tradisional dan ruang berarsitekstur modern dengan data sebagai berikut :

49
Paired Sample t-test Dilakukan beberapa sample data sebelum dan sesudah dilakukan pengetesan dengan hasil sebagai berikut : Sajikan dan interpretasikan

50
Variabel view : 1 id, 2.arsitektur (value :1.modern, 2. tradisional)
Sajikan dan interpretasikan ( soal dan jawaban di buat di microsft word Variabel view : 1 id, 2.arsitektur (value :1.modern, 2. tradisional) Hipotesa untuk menjawab kasus diatas. H0 : tidak ada perbedaan stres karyawan ketika berada di ruang tradisional dengan ketika berada di ruang modern H1 : Ada perbedaan stress karyawan ketika berada di ruang tradisional dengan ketika berada di ruang modern
 Hipotesa untuk menjawab kasus diatas. H0 : tidak ada perbedaan stres karyawan ketika berada di ruang tradisional dengan ketika berada di ruang modern. H1 : Ada perbedaan stress karyawan ketika berada di ruang tradisional dengan ketika berada di ruang modern.")
51
Question ? Jelaskan perbedaan paired sample t test dan independet sample t test Kapan saudara akan mengunakan alat uji paired sample t- test dan independet sample t test

52
Uji-Anova digunakan untuk melihat perbedaan rata-rata dari dua atau lebih kelompok independen (data yang tidak saling berkaitan antara satu dengan lainnya). contoh analisis ini kita akan melihat apakah ada perbedaan berat bayi yang lahir dari ibu yang berpendidikan SD, ibu yang berpendidikan SMP, dengan ibu yang berpendidikan SMA. Kita akan melakukan uji hipotesis apakah ada perbedaan rata-rata berat bayi yang lahir dari ibu dari jenis pendidikan yang berbeda

53
Untuk melakukan uji Anova, harus dipenuhi beberapa asumsi, yaitu:
Sampel berasal dari kelompok yang independen (nilai pada satu kelompok tidak tergantung pada nilai di kelompok lain ) Varian antar kelompok harus homogen Data masing-masing kelompok berdistribusi normal
 Varian antar kelompok harus homogen. Data masing-masing kelompok berdistribusi normal.")
54
Langkah Uji Anova 1. Bukalah file BAYI95.SAV sampai tampak pada Data editor window. 2. Klik Analyze > Compare Means > One-way ANOVA

55
Kemudian Klik Option > Klik Descriptive dan Homogeneity of …
Kemudian Klik Option > Klik Descriptive dan Homogeneity of …. Kemudian klik Continue dan Klik Ok

56
RESULT

57
ANALISIS DATA Pada hasil di atas terlihat bahwa rata-rata berat bayi pada ibu dengan pendidikan SD adalah gram, pada ibu dengan pendidikan SMP adalah gram, dan pada ibu berpendidikan SMA adalah gram. Standar deviasi, nilai minimum-maximun, dan interval 95% tingkat kepercayaan juga diperlihatkan

58
Salah satu asumsi dari uji Anova adalah varians masing-masing kelompok harus sama. Untuk itu dilakukan uji homogenitas varians yang hasilnya memperlihatkan bahwa p-value (sig.) lebih besar dari nilai α=0.05, berarti varians antar kelompok adalah sama
 lebih besar dari nilai α=0.05, berarti varians antar kelompok adalah sama.")
59
Pada hasil di atas diperoleh nilai ANOVA F = 1. 091 dengan p-value=0
Pada hasil di atas diperoleh nilai ANOVA F = dengan p-value=0.000 (dalam keadaan ini boleh juga ditulis p < 0.001). Hipotesis nol pada uji ANOVA adalah tidak ada perbedaan rata-rata berat bayi antara kelompok ibu dengan pendidikan SD, SMP, dan SMA. Sedangkan hipotesis alternatifnya adalah salah satu nilai rata-rata berat bayi berbeda dengan lainnya. Dengan menggunakan α=0.05, dari hasil di atas kita menolak hipotesis nol. Sehingga kita menyimpulkan ada perbedaan berat badan bayi dari ke tiga kelompok ibu tersebut (setidaknya salah satu nilai mean berbeda dengan lainnya). Namun, kita belum tahu kelompok mana yang berbeda antara satu dengan yang lainnya untuk mengetahui perbedaan kelompok bisa mengunakan Post Hock Test
. Hipotesis nol pada uji ANOVA adalah tidak ada perbedaan rata-rata berat bayi antara kelompok ibu dengan pendidikan SD, SMP, dan SMA. Sedangkan hipotesis alternatifnya adalah salah satu nilai rata-rata berat bayi berbeda dengan lainnya. Dengan menggunakan α=0.05, dari hasil di atas kita menolak hipotesis nol. Sehingga kita menyimpulkan ada perbedaan berat badan bayi dari ke tiga kelompok ibu tersebut (setidaknya salah satu nilai mean berbeda dengan lainnya). Namun, kita belum tahu kelompok mana yang berbeda antara satu dengan yang lainnya untuk mengetahui perbedaan kelompok bisa mengunakan Post Hock Test.")
60
Analisi Regresi

61
Syarat Pengujian Analisis Regresi
Asumsi Normalitas Kenormalan data diperlukan dalam analisis regresi, salah satu metode yang digunakan dalam menguji normalitas adalah metode Kolmogorov Smirnov (KS), dalam metode KS penerimaan H0 mengindikasikan bahwa data yang dianalisis tersebut tersebar normal Jika nilai Sig value > 0,05 maka data regresi mengikuti sebaran normal, dan jika sebaliknya nilai Sig value < 0,05 maka dinyatakan bahwa sebaran data tidak normal
, dalam metode KS penerimaan H0 mengindikasikan bahwa data yang dianalisis tersebut tersebar normal. Jika nilai Sig value > 0,05 maka data regresi mengikuti sebaran normal, dan jika sebaliknya nilai Sig value < 0,05 maka dinyatakan bahwa sebaran data tidak normal.")
62
2. Asumsi Homogenitas / Heteroskedastisitas
Salah satu metode yang digunakan dalam menganalisa homogen atau tidaknya suatu data dalam regresi adalah Uji Levene ( levene test) Jika Sig Value > 0.05 maka H0 diterima, artinya data bersifat homogen sebaliknya Jika Sig Value <0.05 H0 di tolak, artinya data bersifat tidak homogen
 Jika Sig Value > 0.05 maka H0 diterima, artinya data bersifat homogen sebaliknya. Jika Sig Value <0.05 H0 di tolak, artinya data bersifat tidak homogen.")
63
3. Asumsi tidak terjadi Multikolinier
Kolinier Ganda merupakan hubungan linier yang sama kuat antara variabel-variabel bebas dalam persamaan regresi berganda. - Adanya kolinier berganda ini menyebabkan pendugaan koefisien menjadi tidak stabil. Sebagai catatan tidak multikolinier hanya terjadi pada regresi berganda saja, untuk regresi sederhana tidak terjadi kr variabel bebasnya hanya satu.

64
Asumsi tidak terjadi autokorelasi
Uji korelasi digunakan untuk melihat kebebas data, kebebasan disini dimaksudkan bahwa data suatu observasi tertentu tidak dipengaruhi data observasi sebelumnya. Salah satu metode yang digunakan dalam menguji autokorelasi adalah metode Durbin Watson (DW)
")
65
Latihan : Regresi Sederhana

66
Klik Analyze > Regression > Linier sehingga akan ditampilkan tampilan pada gambar berikut :

67
Output

69
Interpretasi Pada Uji Anova terlihat bahwa terdapat pengaruh yang significant antara Variabel Promosi (X1) terhadap variabel sales(Y) dimana: Nilai Sig < Alpha 5% ( 0,000 < 0,05) Atau pada uji-t terlihat nilai t hitung > t tabel (6,384) atau nilai alpha < 0.05 (0,000 < 0,05)
 Atau pada uji-t terlihat nilai t hitung > t tabel (6,384) atau nilai alpha < 0.05 (0,000 < 0,05)")
70
Dari data tersebut diatas juga terlihat adanya korelasi yang kuat antara variabel Promosi(X1) terhadap variabel Sales(Y) hal ini dibuktikan dengan nilai korelasi(R) sebesar 0.612, sedangkan pada koefisien determinasinya (R Square) yaitu kemampuan untuk mempengaruhi antar variabel Promosi terhadap Sales sebesar dan masih terdapat 62.5% (100%-37,5%) varibel lain yang mempengaruhi Sales (selain variabel promosi tersebut)
 yaitu kemampuan untuk mempengaruhi antar variabel Promosi terhadap Sales sebesar dan masih terdapat 62.5% (100%-37,5%) varibel lain yang mempengaruhi Sales (selain variabel promosi tersebut)")
71
Nilai Konstanta sebesar 214
Nilai Konstanta sebesar menunjukkan bahwa jika tidak ada aktivitas Promosi(X1=0) maka nilai sales/penjualan hanya sebesar Nilai Slop menunjukkan bahwa setiap kenaikan kegiatan promosi 1 juta Rupiah, maka hal tersebut akan meningkatkan sales/penjualan sebesar juta rupiah.
 maka nilai sales/penjualan hanya sebesar Nilai Slop menunjukkan bahwa setiap kenaikan kegiatan promosi 1 juta Rupiah, maka hal tersebut akan meningkatkan sales/penjualan sebesar juta rupiah.")
72
Take Home Sajikan dan Interpretasikan No Kunjungan Kepuasan 1 47098
6754 2 56847 7925 3 36984 5687 4 87489 9483 5 23346 3514 6 38660 6642 7 41835 7411 8 60149 9935 9 25524 3543 10 55911 7634 11 47683 7603

Presentasi serupa



>")


>")




>")





>")




