Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Model Logistik untuk Data Ordinal (Ordinal Regression)
Analisis Data Kategorik Pertemuan X

2
Ordinal Regression Menggunakan variabel ordinal
Bisa mengurutkan nilainya tetapi jarak sebenarnya antar nilai tidak diketahui Model ordinal logistic untuk satu variabel bebas X: ln 𝜃 𝑗 = 𝛼 𝑗 −𝛽𝑋, 𝑗=1,..𝑗𝑢𝑚𝑙𝑎ℎ 𝑘𝑎𝑡𝑒𝑔𝑜𝑟𝑖 Makin tinggi koefisien mengindikasikan asosiasi dengan skor yang tinggi

3
Ordinal Regression When you see a positive coefficient for a dichotomous factor, you know that higher scores are more likely for the first category. A negative coefficient tells you that lower scores are more likely. For a continuous variable, a positive coefficient tells you that as the values of the variable increase, the likelihood of larger scores increases. An association with higher scores means smaller cumulative probabilities for lower scores, since they are less likely to occur.

4
Ordinal Regression Setiap logit memiliki ∝ 𝑗 -nya sendiri (thresholds values) dengan koefisien 𝛽 yang sama, artinya efek dari variabel independen sama untuk fungsi logit yang berbeda (proportional odds model) Contoh: Survei kepuasan responden dengan pilihan jawaban sangat setuju hingga sangat tidak setuju Ordinal variabel sebagai dependen variabel SPSS Ordinal Regression atau PLUM (Polytomous Universal Model)
 dengan koefisien 𝛽 yang sama, artinya efek dari variabel independen sama untuk fungsi logit yang berbeda (proportional odds model) Contoh: Survei kepuasan responden dengan pilihan jawaban sangat setuju hingga sangat tidak setuju. Ordinal variabel sebagai dependen variabel. SPSS Ordinal Regression atau PLUM (Polytomous Universal Model)")
5
Ordinal Regression dengan SPSS
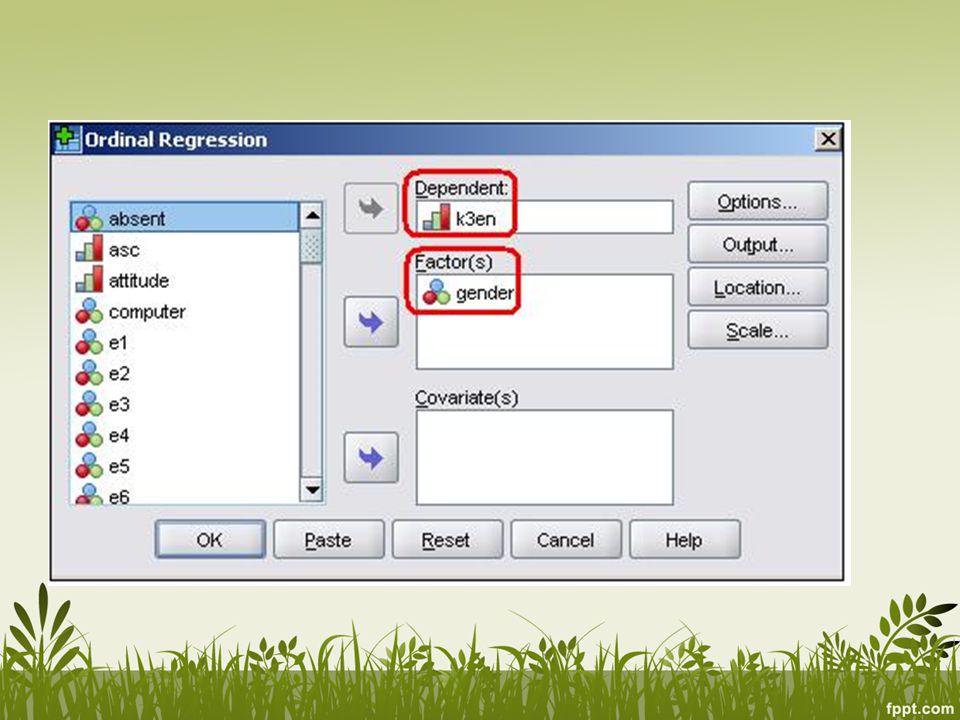
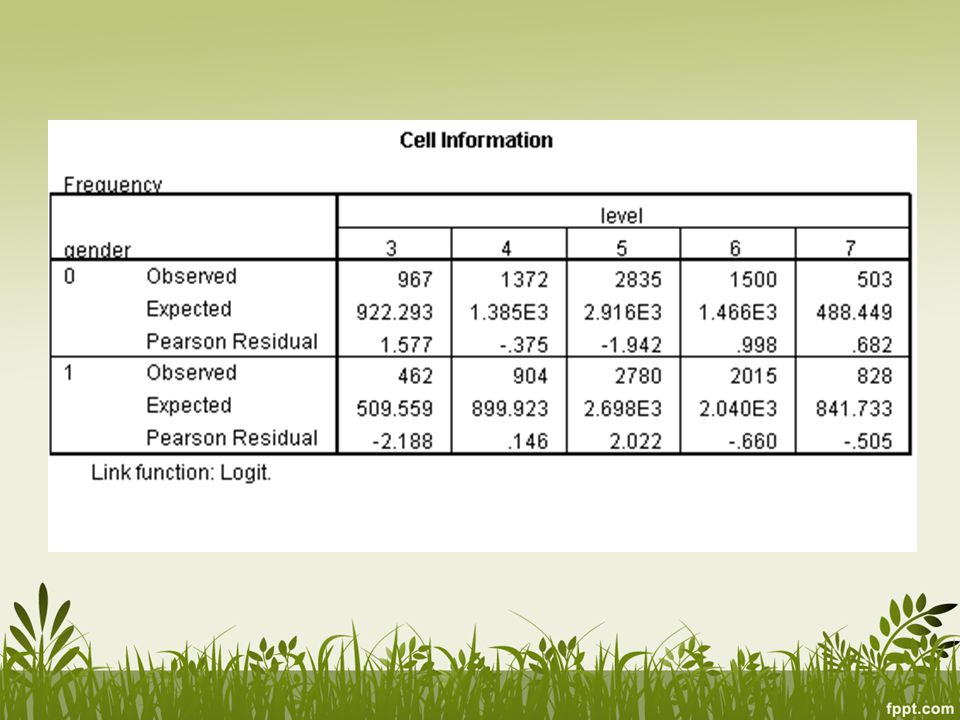
Untuk dependent variabel, SPSS memodelkan probabilitas setiap level atau dibawahnya (bukan setiap level atau di atasnya) Secara otomatis, SPSS mengambil kategori terakhir sebagai reference category Contoh: Level awal kelas bahasa inggris (Y), dengan gender (X; boys = 0, girls = 1). LSYPE.sav Analyses > Regression > Ordinal Gender LEVEL 3 4 5 6 7 Boys 967 1372 2835 1500 503 Girls 462 904 2780 2015 828
 Secara otomatis, SPSS mengambil kategori terakhir sebagai reference category. Contoh: Level awal kelas bahasa inggris (Y), dengan gender (X; boys = 0, girls = 1). LSYPE.sav. Analyses > Regression > Ordinal. Gender. LEVEL Boys Girls")
8
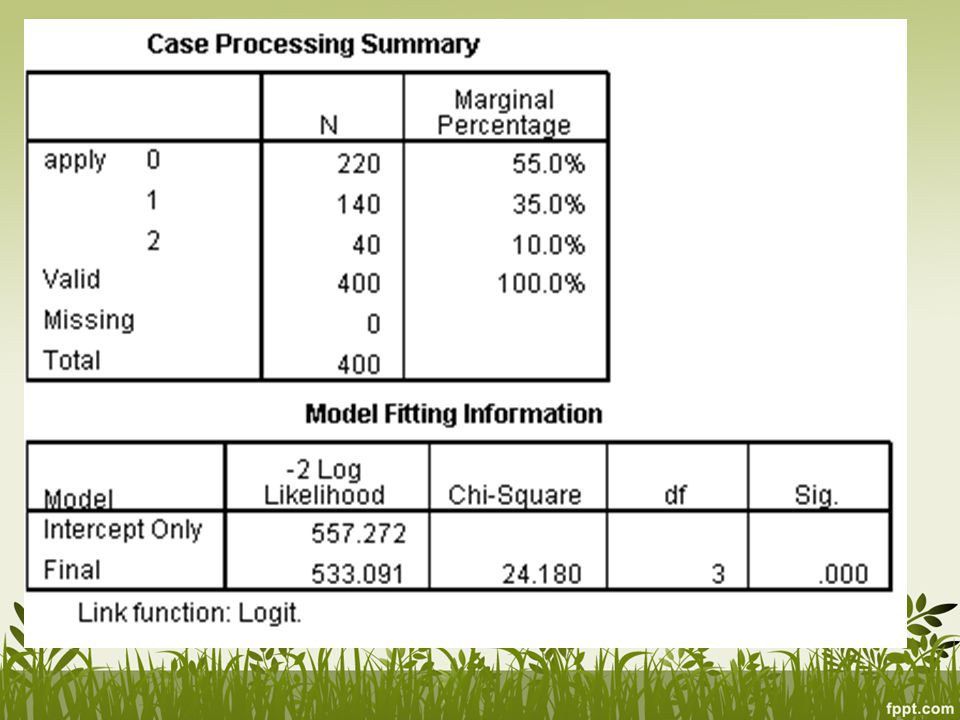
We compare the final model (model with all explanatory variables) against the baseline (model without any explanatory variables) to see whether it has significantly improved the fit to the data. The statistically significant chi-square statistic (p<.0005) indicates that the Final model gives a significant improvement over the baseline intercept-only model.
 indicates that the Final model gives a significant improvement over the baseline intercept-only model.")
9
The Deviance (-2LL) Statistic
Deviance, ukuran seberapa banyak variasi yang tidak dapat dijelaskan oleh model regresi logistik Semakin tinggi nilai deviance semakin kurang akurat modelnya 𝜒 2 = −2𝐿𝐿 𝑏𝑎𝑠𝑒𝑙𝑖𝑛𝑒 − −2𝐿𝐿 𝑛𝑒𝑤 𝑑𝑜𝑓= 𝑘 𝑏𝑎𝑠𝑒𝑙𝑖𝑛𝑒 − 𝑘 𝑛𝑒𝑤, 𝑘=𝑗𝑢𝑚𝑙𝑎ℎ 𝑝𝑎𝑟𝑎𝑚𝑒𝑡𝑒𝑟 𝑑𝑎𝑙𝑎𝑚 𝑚𝑜𝑑𝑒𝑙 Jika model baru lebih baik dalam menjelaskan data daripada baseline maka seharusnya ada pengurangan yang signifikan pada deviance yang bisa di uji pada distribusi chi-square (memberikan p-value)
")
10
Kecenderungan chi-square untuk significant pada sample berukuran besar
Sensitive terhadap sel yang kosong Gunakan p-value yang lebih rendah (misalnya 0.01) Gunakan pseudo 𝑅 2
 Gunakan pseudo 𝑅 2.")
11
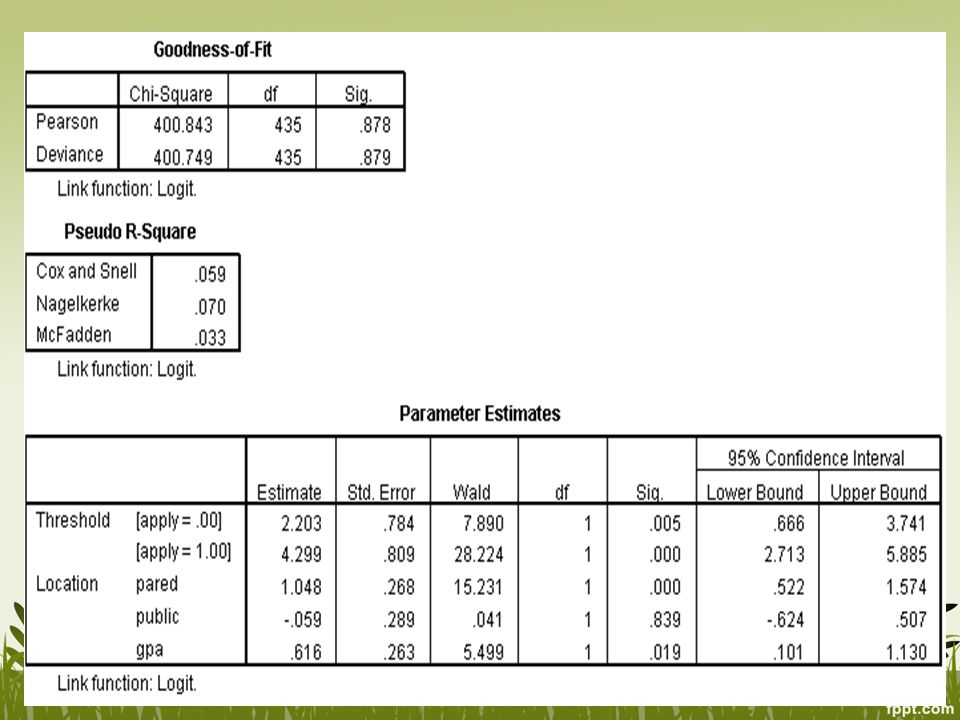
These statistics are intended to test whether the observed data are consistent with the fitted model. We start from the null hypothesis that the fit is good. If we do not reject this hypothesis (i.e. if the p value is large), then you conclude that the data and the model predictions are similar and that you have a good model. Here, the pseudo R2 values (e.g. Nagelkerke = 3.1%) indicates that gender explains a relatively small proportion of the variation between students in their attainment.
 indicates that gender explains a relatively small proportion of the variation between students in their attainment.")
12
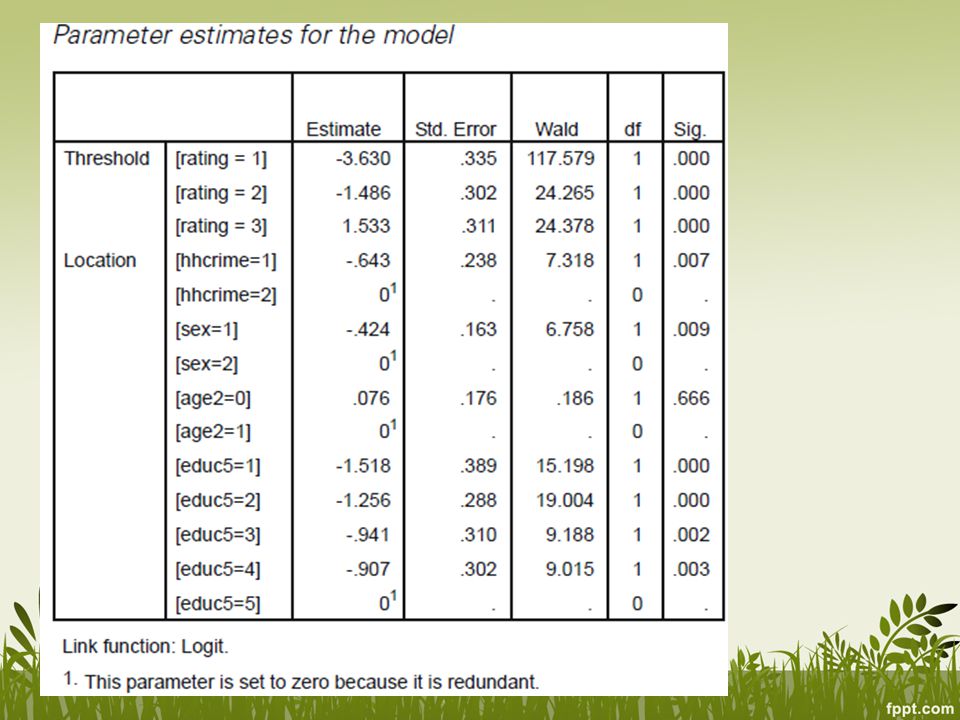
Parameter estimates merupakan tabel inti dimana bisa dilihat hubungan antara variabel penjelas dengan variabel outcome Thresholds tidak diintepretasikan, hanya intercept titik (logit) dimana pelajar diprediksikan ke kategori yang lebih tinggi Odds level 6 atau di bawah level 6 (level = 6) adalah komplemen dari odds berada di level 7, level 5 atau di bawah level 5 (level = 5) adalah komplemen dari odds berada di level 6 ke atas dst
 dimana pelajar diprediksikan ke kategori yang lebih tinggi. Odds level 6 atau di bawah level 6 (level = 6) adalah komplemen dari odds berada di level 7, level 5 atau di bawah level 5 (level = 5) adalah komplemen dari odds berada di level 6 ke atas dst.")
13
Proportional odds principle
Girls = reference category y = a – bx 1/0.53= 1.88, equally 1/1.88=0.53 Proportional odds principle

14
OR (girls as the base) = exp(-.629) = 0.53
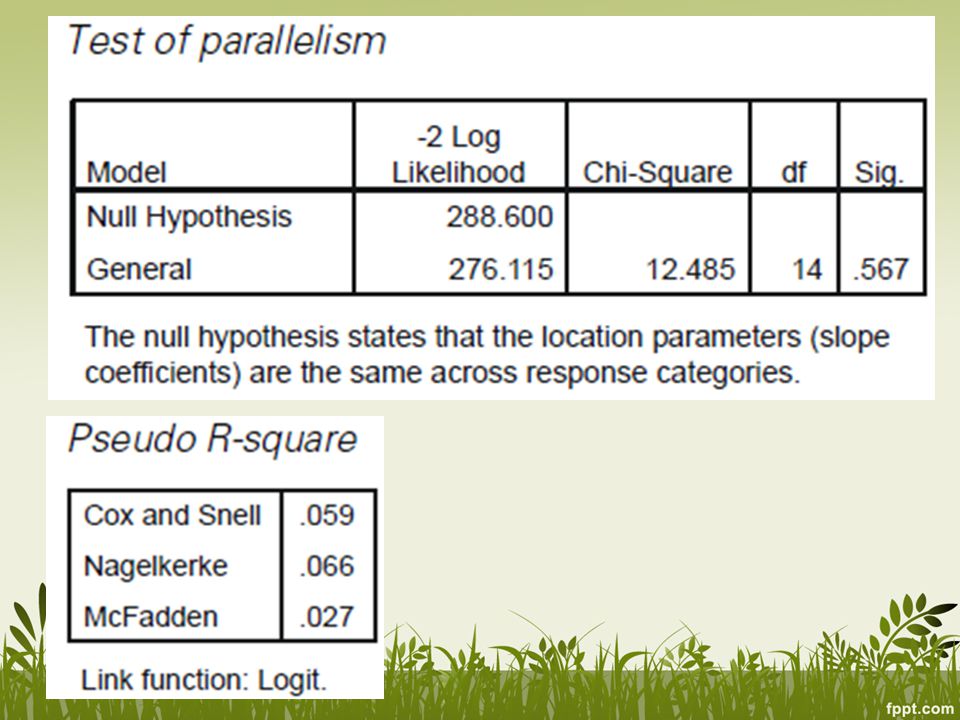
This test compares the ordinal model which has one set of coefficients for all thresholds (labelled Null Hypothesis), to a model with a separate set of coefficients for each threshold (labelled General). If the general model gives a significantly better fit to the data than the ordinal (proportional odds) model (i.e. if p<.05) then we are led to reject the assumption of proportional odds. OR (girls as the base) = exp(-.629) = 0.53 OR (boys as the base) = exp(.629) = 1.88
, to a model with a separate set of coefficients for each threshold (labelled General). If the general model gives a significantly better fit to the data than the ordinal (proportional odds) model (i.e. if p<.05) then we are led to reject the assumption of proportional odds. OR (girls as the base) = exp(-.629) = OR (boys as the base) = exp(.629) =")
15
Asumsi Proportional Odds (PO)
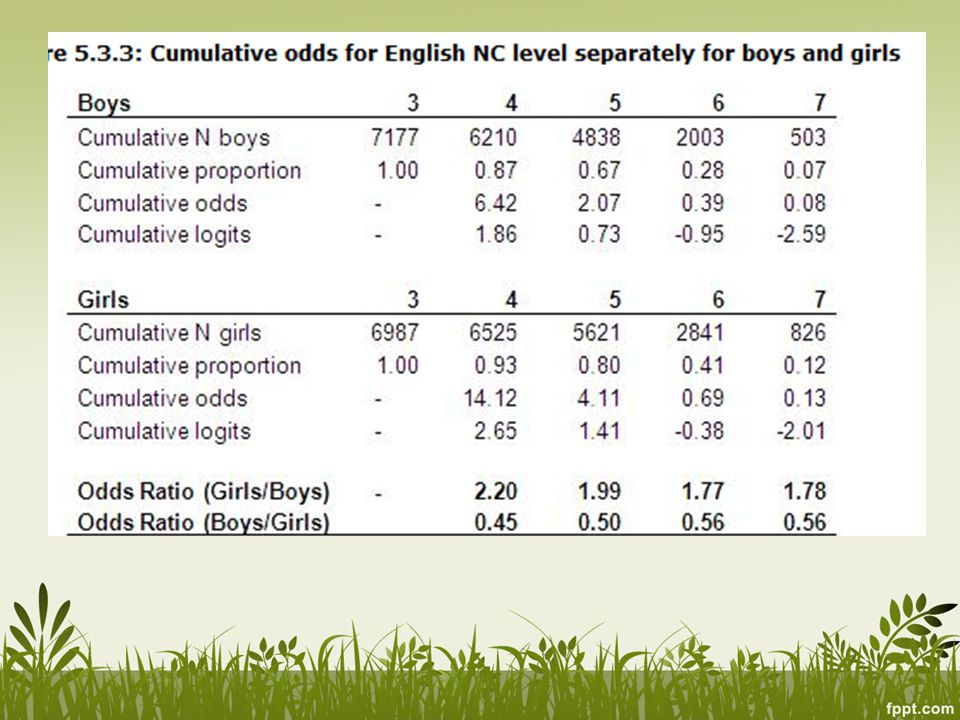
Cumulative proportion = just the percentage Cumulative odds = 1347/( ), odds mencapai level 7, odds berada di level 6 atau ke atas= 4918/9545 = 0.52 atau p/(1-p) Cumulative logits = ln (cumulative odds)
, odds mencapai level 7, odds berada di level 6 atau ke atas= 4918/9545 = 0.52 atau p/(1-p) Cumulative logits = ln (cumulative odds)")
16
Efek dari variabel penjelas adalah konsisten atau proporsional pada thresholds yang berbeda (SPSS,parallel lines assumption)
")
17
Remaja putri cenderung untuk memperoleh level yang lebih tinggi daripada remaja putra

19
Secara umum odds untuk remaja putri selalu lebih tinggi daripada remaja putra
OR bervariasi pada threshold kategori yang berbeda, jika OR ini tidak berbeda secara signifikan maka kita bisa meringkas hubungan antara gender dengan level bahasa inggris dengan OR tunggal dari regresi ordinal

21
Ordinal Regression dengan Beberapa Variabel Bebas
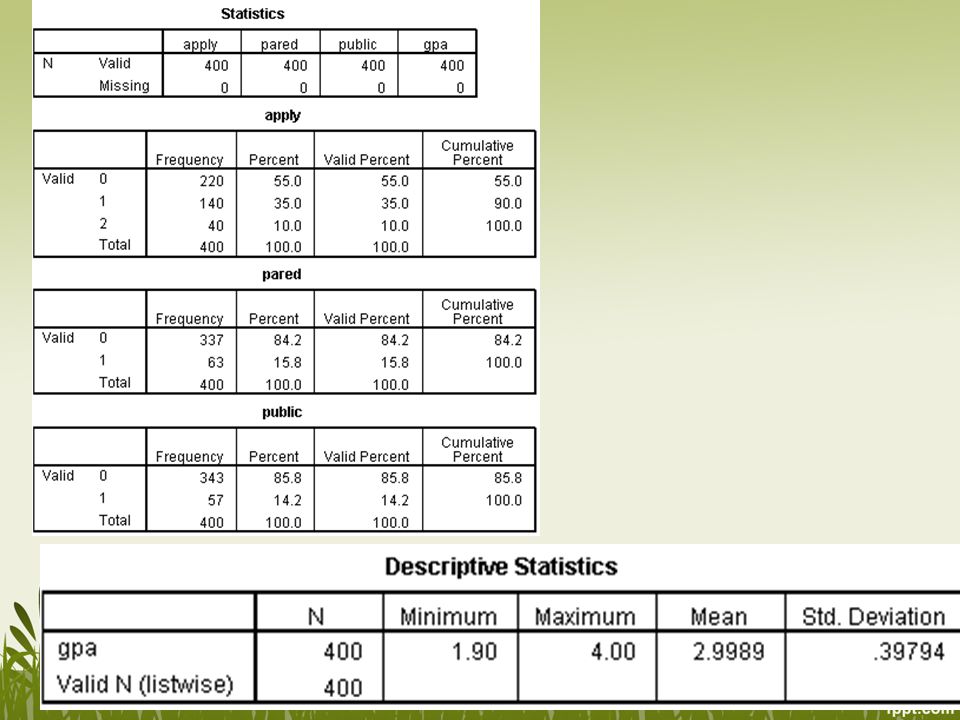
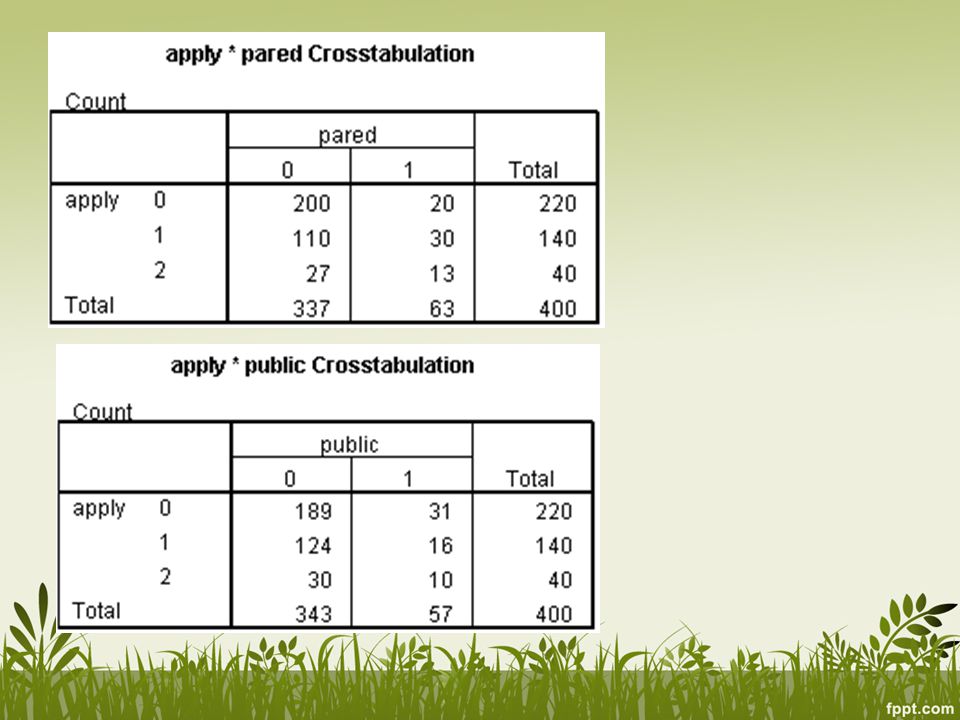
Sebuah study dilakukan untuk melihat faktor-faktor yang mempengaruhi seseorang untuk mendaftar sekolah ke jenjang lebih tinggi Seorang pelajar ditanya apakah mereka: “tidak akan mendaftar”, “tidak tahu”, dan “akan mendaftar” ke jenjang lebih tinggi. Variabel outcome memiliki tiga kategori (0,1,2) Dikumpulkan juga data mengenai pendidikan orang tua (apakah pendidikan terakhir orang tua adalah S1;0,1), jenis institusi pendidikan (public atau private;0,1), dan GPA. ologit.sav
 Dikumpulkan juga data mengenai pendidikan orang tua (apakah pendidikan terakhir orang tua adalah S1;0,1), jenis institusi pendidikan (public atau private;0,1), dan GPA. ologit.sav.")
22
PLUM apply with pared public gpa /LINK=LOGIT /PRINT=FIT PARAMETER SUMMARY TPARALLEL

27
Odds Ratio (ln Estimate)
Threshold biasanya tidak disertakan dalam intepretasi proportional OR Untuk pared, setiap kenaikan satu unit pared (dari 0 ke 1), odds untuk mendaftar 2.85 kali lebih besar daripada tidak tahu dan tidak mendaftar, dengan asumsi semua variabel dalam model konstan Demikian juga, odds antara tidak tahu dan mendaftar 2.85 kali lebih besar daripada tidak mendaftar Setiap kenaikan satu unit GPA, odds tidak mendaftar dan tidak tahu 1.85 kali lebih besar daripada yang mendaftar
, odds untuk mendaftar 2.85 kali lebih besar daripada tidak tahu dan tidak mendaftar, dengan asumsi semua variabel dalam model konstan. Demikian juga, odds antara tidak tahu dan mendaftar 2.85 kali lebih besar daripada tidak mendaftar. Setiap kenaikan satu unit GPA, odds tidak mendaftar dan tidak tahu 1.85 kali lebih besar daripada yang mendaftar.")
28
Pendidikan orang tua dan GPA memiliki asosiasi positif untuk kecenderungan mendaftar ke jenjang sekolah yang lebih tinggi Setiap satu unit kenaikan pada pendidikan orang tua, ekspektasi log odds akan bertambah 1.05 setiap kenaikan kategori apply yang lebih tinggi Setiap kenaikan satu unit GPA diharapkan kenaikan ekspektasi log odds sebesar 0.62 pada setiap kenaikan apply yang lebih tinggi Public tidak memberikan efek yang signifikan pada apply

29
Example: Random sample of Vermont citizens was asked to rate the work of criminal judges in the state. The scale was Poor (1), Only fair (2), Good (3), and Excellent (4). At the same time, they had to report whether somebody of their household had been a crime victim within the last 3 years(1=Yes, 2=No).(vermont.sav) Apakah orang dengan riwayat pernah menjadi korban dan orang yang tidak memiliki riwayat pernah menjadi korban memiliki pandangan yang sama mengenai penegakan keadilan?
, Only fair (2), Good (3), and Excellent (4). At the same time, they had to report whether somebody of their household had been a crime victim within the last 3 years(1=Yes, 2=No).(vermont.sav) Apakah orang dengan riwayat pernah menjadi korban dan orang yang tidak memiliki riwayat pernah menjadi korban memiliki pandangan yang sama mengenai penegakan keadilan")
30
Penambahan variabel baru: sex, age(dua kategori), pendidikan (5 kategori)
, pendidikan (5 kategori)")
33
Regresi Logistik VS Loglinier Model
Regresi logistik adalah model statistika yang digunakan untuk variabel dependen/respon kategorik Loglinier model digunakan jika paling sedikit terdapat dua variabel respon dalam tabel kontingensi. Model akan menjelaskan pola hubungan diantara sekumpulan variabel respon kategorik

34
Loglinier Model dan Regresi Logistik berbeda dalam hal:
Distribusi dari variabel kategorik yaitu Poisson bukan binomial Fungsi link yaitu log, bukan logit Prediksi merupkan estimasi dari sel yang dihitung berdasar tabel kontingensi, bukan nilai logit dari dependen

35
Kesesuaian Model Loglinier dan Model Logit
Model loglinier dan model logit memiliki struktur yang sama untuk asosiasi antara variabel dependen/respon dan variabel-variabel independen/penjelas Mengandung interaksi yang paling umum untuk hubungan-hubungan diantara variabel-variabel penjelas

36
Kesesuaian Model Loglinier dan Model Logit
Kesesuaian antara model logit dengan model log linier pada Tabel I x J x 2, : 𝑙𝑜𝑔 𝑚 𝑖𝑗1 𝑚 𝑖𝑗2 =𝛼+ 𝛽 𝑖 𝐴 + 𝛽 𝑗 𝐵 Respon Y berasosiasi dengan faktor A dan B dengan efek tiap variabel sama pada tiap level dari faktor yang lain Model loglinier mengandung asosiasi antara 𝜆 𝑖𝑘 𝐴𝑌 & 𝜆 𝑗𝑘 𝐵𝑌 dan 𝜆 𝑖𝑗 𝐴𝐵 untuk hubungan antara faktor Hasil akhir model adalah (AB,AY,BY)
")
37
Kesesuaian Model Loglinier dan Model Logit
Model loglinier (AB,AY,BY) menyatakan secara tidak langsung model logit dapat diperlihatkan sebagai berikut: 𝑙𝑜𝑔 𝑚 𝑖𝑗1 𝑚 𝑖𝑗2 = log 𝑚 𝑖𝑗1 −log( 𝑚 𝑖𝑗2 ) = μ+ 𝜆 𝑖 𝐴 + 𝜆 𝑗 𝐵 + 𝜆 1 𝑌 + 𝜆 𝑖𝑗 𝐴𝐵 + 𝜆 𝑖1 𝐴𝑌 + 𝜆 𝑗1 𝐵𝑌 − μ+ 𝜆 𝑖 𝐴 + 𝜆 𝑗 𝐵 + 𝜆 2 𝑌 + 𝜆 𝑖𝑗 𝐴𝐵 + 𝜆 𝑖2 𝐴𝑌 + 𝜆 𝑗2 𝐵𝑌 = 𝜆 1 𝑌 − 𝜆 2 𝑌 + 𝜆 𝑖1 𝐴𝑌 − 𝜆 𝑖2 𝐴𝑌 + 𝜆 𝑗1 𝐵𝑌 − 𝜆 𝑗2 𝐵𝑌 Dengan mengasumsikan bahwa : 𝑘 𝜆 𝑘 𝑌 = 𝑘 𝜆 𝑖𝑘 𝐴𝑌 = 𝑘 𝜆 𝑗𝑘 𝐵𝑌 = 0 𝜆 1 𝑌 =− 𝜆 2 𝑌 , 𝜆 𝑖1 𝐴𝑌 =− 𝜆 𝑖2 𝐴𝑌 , 𝜆 𝑗1 𝐵𝑌 =− 𝜆 𝑗2 𝐵𝑌
 menyatakan secara tidak langsung model logit dapat diperlihatkan sebagai berikut: 𝑙𝑜𝑔 𝑚 𝑖𝑗1 𝑚 𝑖𝑗2 = log 𝑚 𝑖𝑗1 −log( 𝑚 𝑖𝑗2 ) = μ+ 𝜆 𝑖 𝐴 + 𝜆 𝑗 𝐵 + 𝜆 1 𝑌 + 𝜆 𝑖𝑗 𝐴𝐵 + 𝜆 𝑖1 𝐴𝑌 + 𝜆 𝑗1 𝐵𝑌 − μ+ 𝜆 𝑖 𝐴 + 𝜆 𝑗 𝐵 + 𝜆 2 𝑌 + 𝜆 𝑖𝑗 𝐴𝐵 + 𝜆 𝑖2 𝐴𝑌 + 𝜆 𝑗2 𝐵𝑌. = 𝜆 1 𝑌 − 𝜆 2 𝑌 + 𝜆 𝑖1 𝐴𝑌 − 𝜆 𝑖2 𝐴𝑌 + 𝜆 𝑗1 𝐵𝑌 − 𝜆 𝑗2 𝐵𝑌. Dengan mengasumsikan bahwa : 𝑘 𝜆 𝑘 𝑌 = 𝑘 𝜆 𝑖𝑘 𝐴𝑌 = 𝑘 𝜆 𝑗𝑘 𝐵𝑌 = 0. 𝜆 1 𝑌 =− 𝜆 2 𝑌 , 𝜆 𝑖1 𝐴𝑌 =− 𝜆 𝑖2 𝐴𝑌 , 𝜆 𝑗1 𝐵𝑌 =− 𝜆 𝑗2 𝐵𝑌.")
38
Kesesuaian Model Loglinier dan Model Logit
Dengan demikian bentuk sederhana dari model logit adalah: 𝑙𝑜𝑔 𝑚 𝑖𝑗1 𝑚 𝑖𝑗2 =2 𝜆 1 𝑌 + 2𝜆 𝑖1 𝐴𝑌 + 2𝜆 𝑗1 𝐵𝑌

Presentasi serupa
>")






>")










 array stack dan queue>")
