Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Statistika Non Parametrik
Kasus k Sampel Independen Tes X2 untuk k Sampel Independen Perluasan Tes Median Analisis Rangking Satu Arah Kruskal-Wallis

2
Analisis Varian Ranking Satu Arah Kruskal - Wallis
Fungsi :untuk menentukan apakah k sampel independen berasal dari populasi-populasi yang berbeda. Teknik Kruskal – Wallis menguji hipotesis-nol bahwa k sampel berasal dari populasi yang sama atau populasi identik, dalam hal harga rata-rata. Tes ini membuat anggapan bahwa variabel yang dipelajari mempunyai distribusi kontinou. Tes ini, menuntut pengukuran variabelnya paling lemah dalam skala ordinal

3
Langkah – langkah : Berilah ranking-ranking observasi untuk kelompok itu dalam suatu urutan dari 1 hingga N Tentukan harga R (jumlah ranking) untuk masing-masing k kelompok. Jika suatu propoprsi yang besar diantara observasi-observasi itu berangka sama, hitunglah harga H dari rumus 8.3. jika tidak, gunakan rumus 8.1 Metode untuk menilai signifikansi harga observasi H bergantung pada ukuran k dan pada ukuran kelompok itu.
 untuk masing-masing k kelompok. Jika suatu propoprsi yang besar diantara observasi-observasi itu berangka sama, hitunglah harga H dari rumus 8.3. jika tidak, gunakan rumus 8.1. Metode untuk menilai signifikansi harga observasi H bergantung pada ukuran k dan pada ukuran kelompok itu.")
4
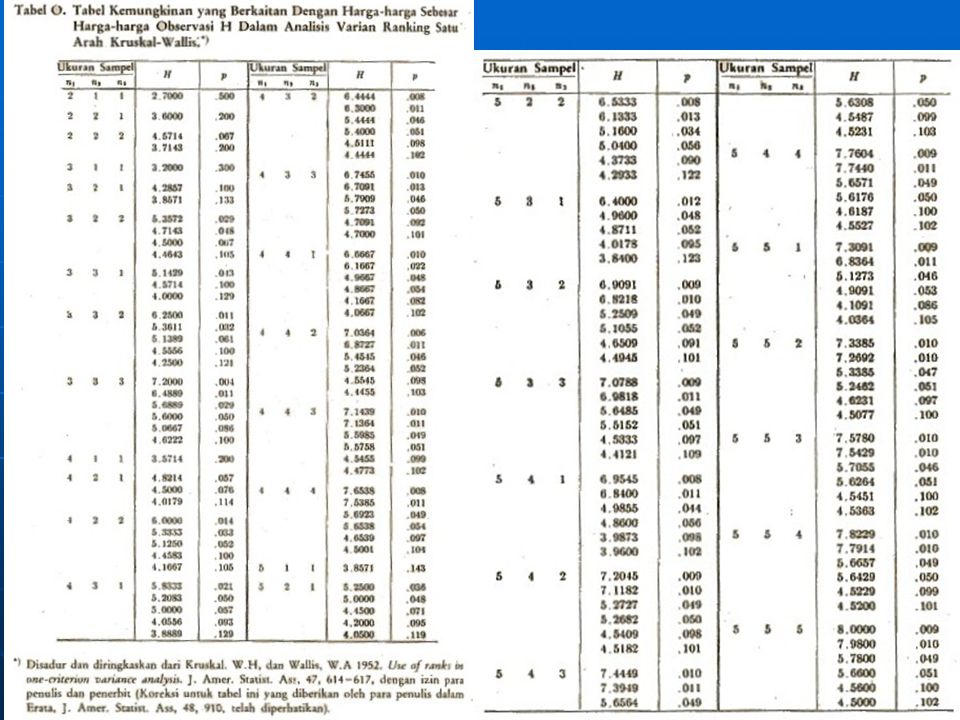
jika k=3 dan n1, n2 dan n3 5 Tabel 0
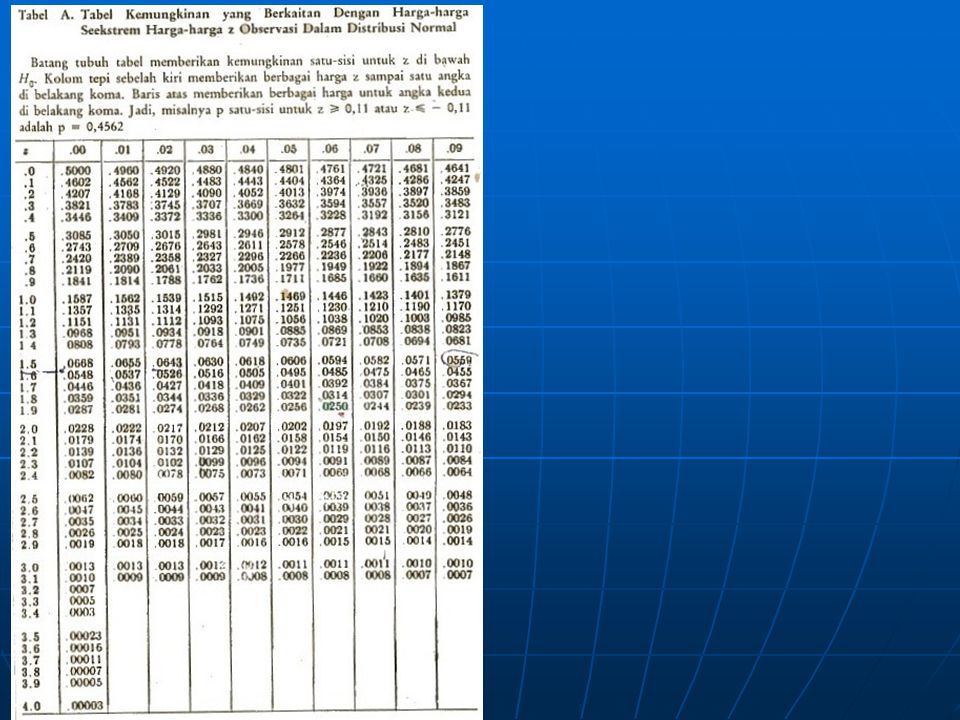
dalam kasus lain, signifikansi uatu harga sebesar harga H dapat ditaksir dengan menggunakan Tabel C Jika kemungkinan yang berkaitan dengan harga observasi H adalah sama dengan atau kurang dari , tolaklah H0. Statistik yang digunakan dalam tes Kruskal–Wallis didefinisikan dengan rumus 8.1 berdistribusi Chi–Kuadrat dengan db = k – 1, dengan syarat bahwa ukuran k sampel itu tidak terlalu kecil.

5
12 k Rj2 H = - 3 ( N+1)………….8.1 N(N+1) j=1 nj
k = banyak sampel nj = banyak kasus dalam sampel ke–j N = nj = banyak kasus dalam semua sampel k = menunjukkuan kita harus menjumlahkan J=1 seluruh k sampel (kolom-kolom) mendekati distribusi chikuadrat dengan db = k -1 untuk ukuran sampel (harga nj) yang cukup besar.
 mendekati. distribusi chikuadrat dengan db = k -1 untuk. ukuran sampel (harga nj) yang cukup besar.")
6
Observasi - observasi berangka sama
Kalau terjadi angka sama antara dua skor atau lebih, tiap-tiap skor mendapatkan ranking yang sama, yaitu rata-rata rankingnya perlu koreksi dibagi dengan T 1 - …………………………… 8.2 N3 – N Dimana : T = t2-1 (kalau t adalah banyak observasi-observasi berangka sama ) N = banyaj observasi dlm seluruh k sampel bersama- sama, yakni N = nj T= menunjukkan kita untuk menjumlahkan semua kelompok berangka sama.
 N = banyaj observasi dlm seluruh k sampel bersama- sama, yakni N = nj. T= menunjukkan kita untuk menjumlahkan semua. kelompok berangka sama.")
7
Rumus umum untuk H yang sudah dikoreksi : k Rj - 3 ( N+1) N(N+1 ) j=i nj H = …………………… T N3 – N

8
Dengan koreksi yg dilakukan utk angka sama ini, harga H ditingkatkan dan dengan demikian hasilnya lebih signifikan dibandingkan dengan tanpa koreksi. Oleh karena itu, jika kita dapat menolak Ho tanpa koreksi (yakni dg rms 8.1 utk menghitung H) maka dg menggunakan rms koreksi tsb kita akan menolak Ho bahkan pd tingkat signifikansi yg lebih meyakinkan. Dalam kebanyakan kasus, akibat koreksi itu dapat diabaikan jika yg terlibat dlm angka sama tidak lebih dari 25% observasi, kemungkinan yg berkaitan dg suatu H yg dihitung tanpa koreksi angka sama (yakni kalau digunakan rms 8.1), jarang sekali berubah dengan lebih dari 10% bila dilakukan koreksi angka sama itu, yakni jika H dihitung dngan rumus 8.3.
 maka dg menggunakan rms koreksi tsb kita akan menolak Ho bahkan pd tingkat signifikansi yg lebih meyakinkan. Dalam kebanyakan kasus, akibat koreksi itu dapat diabaikan jika yg terlibat dlm angka sama tidak lebih dari 25% observasi, kemungkinan yg berkaitan dg suatu H yg dihitung tanpa koreksi angka sama (yakni kalau digunakan rms 8.1), jarang sekali berubah dengan lebih dari 10% bila dilakukan koreksi angka sama itu, yakni jika H dihitung dngan rumus 8.3.")
9
Contoh untuk sampel kecil
Misalkan seorang peneliti bidang pendidikan hendak menguji hipotesis bahwa para administrator sekolah biasanya lebih bersifat otoriter dari pada guru kelas. Sungguhpun demikian, peneliti itu tahu bahwa data yang dipakai untuk menguji hipotesis ini mungkin “dikotori” oleh kenyataan bahwa banyak guru kelas yang memiliki orientasi administratif dalam aspirasi-aspirasi profesional mereka. Artinya banyak guru yang menganggap para administrator sebagai reference group.

10
Contoh untuk sampel kecil (lanjutan)
Untuk menghindari pengotoran itu dia merencanakan untuk membagi 14 subyeknya ke dalam tiga kelompok. Para guru yang mempunyai orintasi pengajaran (para guru yang ingin tetap dalam posisinya selaku guru); Para guru yang mempunyai orientasi administratif (para guru kelas yang mempunyai cita-cita menjadi adsministrator); dan Administrator (penyelenggara) sekolah. Peneliti menerapkan skala F1 (suatu pengukuran terhadap keotoriteran) pada masing-masing pada 14 subyek itu. Hipotesisnya ialah bahwa ketiga kelompok tadi akan berbeda dalam harga rata-rata pada skala F itu. Disajikan dalam Adorno,TW, et al., The Authoritarian Personality. New York: Harper
; Para guru yang mempunyai orientasi administratif (para guru kelas yang mempunyai cita-cita menjadi adsministrator); dan. Administrator (penyelenggara) sekolah. Peneliti menerapkan skala F1 (suatu pengukuran terhadap keotoriteran) pada masing-masing pada 14 subyek itu. Hipotesisnya ialah bahwa ketiga kelompok tadi akan berbeda dalam harga rata-rata pada skala F itu. Disajikan dalam Adorno,TW, et al., The Authoritarian Personality. New York: Harper.")
11
Tabel 8.5 Skor Keotoriteran Ketiga Kelompok Pendidik
(bukan data sejati) Guru yang berorientasi pada pengajaran Guru yang berorientasi adsministratif Administrator Skor Rangking 96 4 82 2 115 7 128 9 124 8 149 13 83 3 132 10 155 14 61 1 135 11 147 12 101 5 109 6 R1 = 22 R2 = 37 R3 = 46
 Guru yang berorientasi pada pengajaran. Guru yang berorientasi adsministratif. Administrator. Skor. Rangking R1 = 22. R2 = 37. R3 = 46.")
12
12 k Rj2 H = - 3 (N + 1) ……………………………. (8
k Rj2 H = - 3 (N + 1) ……………………………. (8.1) N(N+1 ) j-I nj (22)2 (37)2 (46) = + + - 3 ( ) (14+1 ) = 6,4 Dengan Tabel O untuk nilai nj adalah 5, 5 dan H 6,4 mempunyai mempunyai kemunculan dibawah Ho sebesar p < 0, H0 ditolak Kesimpulan : tiga kelompok pendidik yang ditunjuk itu berbeda dalam tingkat keotoriteran mereka
 ……………………………. (8.1) N(N+1 ) j-I nj 12 (22)2 (37)2 (46)2 = + + - 3 ( ) 14(14+1 ) = 6,4 Dengan Tabel O untuk nilai nj adalah 5, 5 dan 4 H 6,4 mempunyai mempunyai kemunculan dibawah Ho sebesar p < 0,049 H0 ditolak Kesimpulan : tiga kelompok pendidik yang ditunjuk itu berbeda dalam tingkat keotoriteran mereka.")
13
Contoh untuk sampel besar
Seorang penyelidik mencatat berat ketika lahir anak-anak babi yang merupakan anggota 8 kelompok seinduk yang banyak anggotanya berlain-lainan. Peneliti itu ingin menentukan apakah berat badan waktu lahir dipengaruhi oleh ukuran banyak anak babi dari satu persatu kehamilan. Hipotesis nol. H0 : tidak terdapat perbedaan dalam rata-rata berat ketika lahir pada babi-babi yang berasal dari ukuran besar keturunan yang berbeda-beda dari satu kehamilan. H1 : rata-rata berat ketika lahir itu tidak sama antara babi-babi yang berasal dari ukuran besar keturunan yang berbeda-beda.

14
Tes statistik. Karena kedelapan “kelompok keturunan” itu independent cocok dipakai. Sungguhpun pengukuran berat dalam pon adalah pengukuran dalam skala rasio, kita menggunakan analisis varian satu arah non parametrik, dan bukannya tes parametrik yang ekuivalen. Ini ditempuh, agar kita terhindar dari keharusan membuat anggapan normalitas dan homogenitas varian yang berkaitan dengan tes F parametrik, agar generalitas penemuan kita dapat ditingkatkan. Tingkat signifikansi. Tetapkan = 0,05. N = 56 = banyaknya semua bayi babi yang telah dipelajari.

15
Distribusi sampling. Sebagai yang dihitung dari rumus(8. 1)
Distribusi sampling. Sebagai yang dihitung dari rumus(8.1). H mendekati distribusi chi-kuadrat denagn db= k-1. jadi kemungkinan yang berkaaitan dengan terjadinya, dibawah H0 harga-harga yang sebesar harga H observasi dapat diketahui dengan memakai tabel C sebagai acuan. Daerah penolakan. Daerah penolakannterdiri fdari semua harga H yang sedemikian besar, sehingga kemungkinan yang berkaitan dengan terjadinya harga-harga itu dibawah H0 untuk db = k-1 = 7 adalah sama dengan atau kurang dari = 0.05
. H mendekati distribusi chi-kuadrat denagn db= k-1. jadi kemungkinan yang berkaaitan dengan terjadinya, dibawah H0 harga-harga yang sebesar harga H observasi dapat diketahui dengan memakai tabel C sebagai acuan. Daerah penolakan. Daerah penolakannterdiri fdari semua harga H yang sedemikian besar, sehingga kemungkinan yang berkaitan dengan terjadinya harga-harga itu dibawah H0 untuk db = k-1 = 7 adalah sama dengan atau kurang dari =")
16
Keputusan. Berat badan 56 bayi babi yang termasuk dalam kedelapan “kelompok keturunan seinduk” disajikan dalam tabel 8.7. jika kita mengurutkan 56 berat badan ini, kita dapatkan harga ranking yang disajkikan dalam tabel 8.8. perhatikanlah bahwa kita telah memberikan ranking 56 skor itu dalam satu rangkaian tunggal, sebagai yang diminta oleh tes ini. Bayi babi terkecil, yakni anggota terakhir kelompok turunan pertama, berat 1.1 pon, diberi ranking 1. bayi babi yang terberat, juga dalam kelompok turunan pertama, berat 4,4 pon; berat badan ini mendapatkan ranking 56. dalam tabel 8.8 juga ditunjukkan jumlah ranking masing-masing kolom, yakni R1.

17
Kelompok turunan seinduk
Tabel berat badan waktu lahir: delapan kelompok turunan seinduk babi poland china, musim semi 1919 (dalam pon) Kelompok turunan seinduk 1 2 3 4 5 6 7 8 2.0 3.5 3.3 3.2 2.6 3.1 2.5 2.8 3.6 2.9 2.2 2.4 3.0 1.5 4.4 2.3 1.2 2.1 1.9 1.6 3.4 1.1
 Kelompok turunan seinduk")
18
Tabel 8.8. Ranking Berat Badan Waktu Lahir Delapan Kelompok Turunan Babi
1 2 3 4 5 6 7 8 8.5 27.5 47.5 41.0 56.0 54.5 6.0 1.0 52.5 14.5 15.5 5.0 23.0 36.0 31.5 51.0 18.5 11.0 12.5 2.5 34.0 4.0 R1=317,0 R2=216,5 R3=414,0 R4=277,5 R5=105,5 R6=122,0 R7=71,5 R8=72,0

19
Dengan data dalam Tabel 8
Dengan data dalam Tabel 8.8, kita dapat menghitung harga H tanpa koreksi untuk angka sama, dengan rumus (8.1) :
 :")
20
Tabel C menunjukkan bahwa suatu H 18,464 dengan dk = k - 1 = 7 mempunyai kemungkinan kemunculan dibawah H0 sebesar p < 0,02. Untuk mengadakan koreksi angka sama, pertama harus kita ketahui ada berapa kelompok angka sama yang terjadi, dan berapa banyak skor yang berangka sama dalam tiap-tiap kelompok. Angka sama pertama yang terjadi antara dua babi dalam kelompok turunan 7 (yang keduanya mempunyai berat 1,2 pon). Untuk keduanya diberikan harga ranking 2,5. disini t = t3 - t = = 6. Angka sama berikutnya terjadi antara empat babi yang diberi harga ranking berangka sama 8,5. disini t = 4, dan T = t2 - t = 64 – 4 = 60.
. Untuk keduanya diberikan harga ranking 2,5. disini t = t3 - t = = 6. Angka sama berikutnya terjadi antara empat babi yang diberi harga ranking berangka sama 8,5. disini t = 4, dan T = t2 - t = 64 – 4 = 60.")
21
Dengan terus memeriksa data dalam Tabel 8
Dengan terus memeriksa data dalam Tabel 8.8 secara demikian, kita ketahui bahwa terdapat 13 kelompok angka sama. Kita dapat menghitung banyaknya observasi dalam tiap-tiap kelompok berangka sama menentukan berbagai harga t, dan kita dapat menghitung harga T = t -1 dalam setiap kasus. Penghitungan ini akan menghasilkan hasil hitungan sebagai berikut: t 2 4 5 3 7 6 T 60 120 24 336 210

22
Amatilah bahwa untuk tiap harga t tertentu, harga T adalah suatu konstan. Kini, dengan menggunakan rumus (8.2) kita dapat menghitung koreksi total untuk angka yang sama : T 1 - …………………………… 8.2 (tr 23) N3 – N ( ) = 1- (56)3 – 56 = 0,9945
 N3 – N. ( ) = 1- (56)3 – 56. = 0,9945.")
23
Sekarang, harga itu menjadi penyebut pada rumus (8
Sekarang, harga itu menjadi penyebut pada rumus (8.3), dan harga yang telah kita dapatkan dari rumus (8.1) sebagai pembilangnya. Dengan demikian, kita hanya perlu melakukan satu langkah tambahan untuk menghitung harga H yang dikoreksi untuk angka sama:
, dan harga yang telah kita dapatkan dari rumus (8.1) sebagai pembilangnya. Dengan demikian, kita hanya perlu melakukan satu langkah tambahan untuk menghitung harga H yang dikoreksi untuk angka sama:")
24
Tabel C menunjukkan bahwa kemungkinan yang berkaitan dengan terjadinya, dibawah H0;
suatu harga yang sebesar H = 18,566, db = 7, adalah p < 0,01. karena kemungkinan ini lebih kecil daripada tingkat signifikansi = 0,05 yang kita tetapkan sebelumnya, keputusan kita adalah menolak H0. kita simpulkan bahwa berat badan waktu lahir babi-babi berbeda secara signifikan sehubungan dengan ukuran (besar) kelompok keturunan.
 kelompok keturunan.")
25
0,01>p>0,001 p<0,01 =0,01 18,566 Ho ditolak

28
Contoh-contoh Summarize n Perlakuan A Ra B Rb C Rc D Rd E Re 1 2,00 2
2,00 2 19,50 8,50 3 4 5 Mean 0,6 5,9 1,2 11,6 1,6 15,1 1,8 17,3

29
NPar Tests Kruskal-Wallis Test

30
Post Hoc Tests

32
Contoh-contoh

33
NPar Tests Kruskal-Wallis Test

34
Contoh-contoh

35
Contoh uji Kruskal Wallis (Daniel, terj. PT. Gramedia, hal 260)
")
36
Contoh uji Kruskal Wallis (Daniel, terj. PT. Gramedia, hal 260)
k Rj2 H = - 3 ( N+1)………….8.1 N(N+1) j=1 nj k = banyak sampel nj = banyak kasus dalam sampel ke–j N = nj = banyak kasus dalam semua sampel k = menunjukkuan kita harus menjumlahkan seluruh k sampel (kolom-kolom) j=1 mendekati distribusi chikuadrat dengan db = k -1 untuk ukuran sampel (harga nj) yang cukup besar. Rumus umum untuk H yang sudah dikoreksi : k Rj - 3 ( N+1) N(N+1 ) j=i nj H = …………………… T N3 – N
………….8.1. N(N+1) j=1 nj. k = banyak sampel. nj = banyak kasus dalam sampel ke–j. N = nj = banyak kasus dalam semua sampel. k. = menunjukkuan kita harus menjumlahkan seluruh k sampel (kolom-kolom) j=1 mendekati distribusi chikuadrat dengan db = k -1 untuk ukuran sampel (harga. nj) yang cukup besar. Rumus umum untuk H yang sudah dikoreksi : 12 k Rj2 - 3 ( N+1) N(N+1 ) j=i nj H = …………………… T 1 - N3 – N.")
38
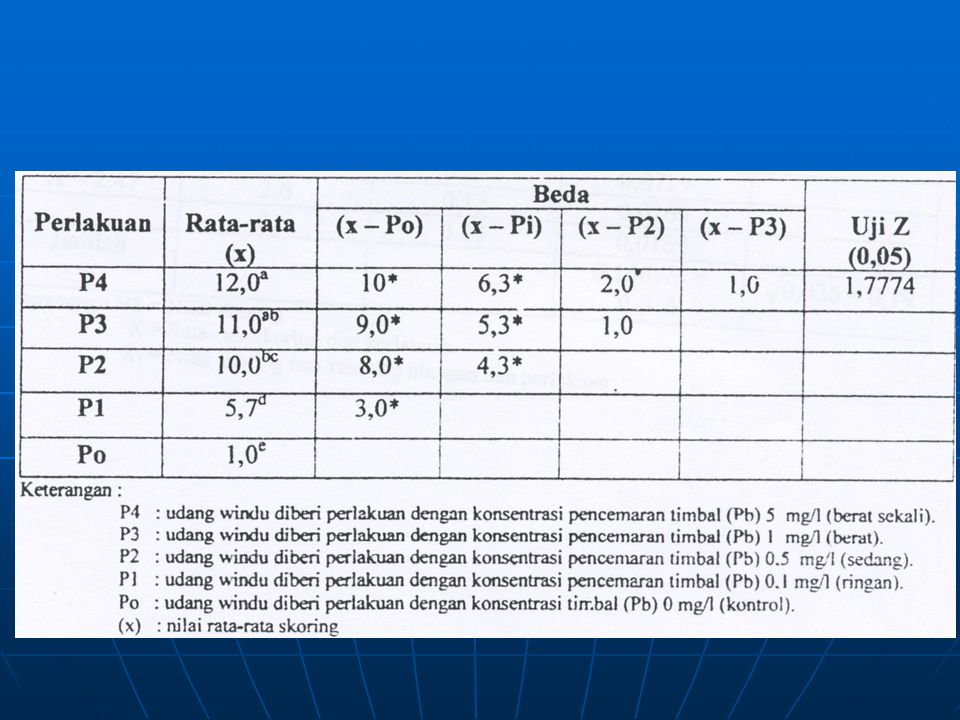
Uji Perbandingan Berganda Sesudah Penerapan Uji Kruskal-Wallis
Sumber: Daniel WW Aplied Nonparametric Statistics. Hougton Miffiin Co. Gerogia State University Pertidaksamaan untuk mencari nilai z: N adalah banyaknya hasil pengamatan dalam semua sampel yang digabungkan. Apabila ke-k sampel memiliki ukuran yang sama, pertidaksamaam tsb berubah menjadi:

39
Uji Perbandingan Berganda Sesudah Penerapan Uji Kruskal-Wallis
Apabila cukup banyak angka sama, perlu koreksi pertidaksamaan tsb agar memberikan hasil yg teliti Pertidaksamaan yang sesuai untuk ukuran sampel yang sama adalah:

40
HITUNGAN Perbandingan Berganda (uji z)
Agar dpt melakukan semua pembandingan yg mungkin dlm upaya menentukan di mana sesungguhnya perbedaan terjadi, maka digunakan =0,15. Karena banyaknya sampel yg harus dikaji adalah 3, maka kita hrs melakukan 3(2)/2=3 buah pembandingan. /k (k-1) = 0,15/3(2) = 0,025 Tabel A nilai z yg daerah sebelah kanannya memiliki luas 0,025 adalah 1,96. Rata2 (mean) untuk ketiga sampel tsb adalah 1 = 69/10 = 6,9; 2 = 90/6 = 15; 3 = 94/6 = 15,67 Untuk membandingkan kel-1 dan kel-2, kita menghitung ruas kanan pd pertidaksamaan berikut: Karena |6,9-15| = 8,1 > 6,57 pembandingan ini nyata Dari data tsb dapat disimpulkan bahwa subyek2 dari kel-1 cenderung memiliki kadar kortisol lbh rendah dibanding subyek2 dari kel-2.
/2=3 buah pembandingan. /k (k-1) = 0,15/3(2) = 0,025 Tabel A nilai z yg daerah sebelah kanannya memiliki luas 0,025 adalah 1,96. Rata2 (mean) untuk ketiga sampel tsb adalah 1 = 69/10 = 6,9; 2 = 90/6 = 15; 3 = 94/6 = 15,67. Untuk membandingkan kel-1 dan kel-2, kita menghitung ruas kanan pd pertidaksamaan berikut: Karena |6,9-15| = 8,1 > 6,57 pembandingan ini nyata. Dari data tsb dapat disimpulkan bahwa subyek2 dari kel-1 cenderung memiliki kadar kortisol lbh rendah dibanding subyek2 dari kel-2.")
41
0,06 1,9 0,0250

42
HITUNGAN Perbandingan Berganda (uji z)
Untuk membandingkan kel-1 dan kel-3, sekali lagi kita menghitung ruas kanan pd pertidaksamaan berikut: Karena |6,9-15,67| = 8,77 > 6,57 dapat disimpulkan bahwa subyek2 dari kel-1 juga cenderung memiliki kadar kortisol lbh rendah dibanding subyek2 dari kel-3. Untuk membandingkan kel-2 dan kel-3, kita menghitung ruas kanan pd pertidaksamaan di atas =, yaitu sebagai berikut: Karena |15,0-15,67| = 0,67 < 7,35 dapat disimpulkan bahwa subyek2 dari kel-2 memiliki kadar kortisol yang tidak berbeda dengan subyek2 dari kel-3.

43
Contoh Uji Kruskal Wallis yang Dilanjutkan dg Uji Perbandingan Berganda (Uji z)
")
44
Contoh uji Kruskal Wallis (Daniel, terj. PT. Gramedia, hal 260)
k Rj2 H = - 3 ( N+1)………….8.1 N(N+1) j=1 nj Rumus umum untuk H yang sudah dikoreksi : k Rj - 3 ( N+1) N(N+1 ) j=i nj H = …………………… T N3 – N
………….8.1. N(N+1) j=1 nj. Rumus umum untuk H yang sudah dikoreksi : 12 k Rj2 - 3 ( N+1) N(N+1 ) j=i nj H = …………………… T 1 - N3 – N.")
45
Ti = t3 - t T 1 - …………… 8.2 N3 – N

47
df 0.05 4 9.49

50
Penelitian dengan judul: “Prevalensi penyakit white spot pada tambak udang di Jawa Timur”
Ketentuan: Penelitian tersebut termasuk jenis penelitian Diskriptif analitik Agar mewakili wilayah Jawa Timur, sampel diambil dari tambak di daerah: Buduran, Gresik dan Kediri Data yang diperoleh termasuk skala data Nominal atau binomial atau dichotomic Analisis statistik yang digunakan adalah chi square dari SPSS rel. 13 for Windows, dengan hasil sebagai berikut:

51
Pertanyaan: Buatlah interpretasi hasil dari analisis statistik tersebut
Jawab: Interpretasi hasil analisis statistik: ; sehingga Ho:……………………………; dan Ha: …………………………... Artinya kejadian penyakit white spot di Jawa Timur (Buduran, Gresik dan Kediri) adalah: ………………………………………………………….
 adalah: ………………………………………………………….")
52
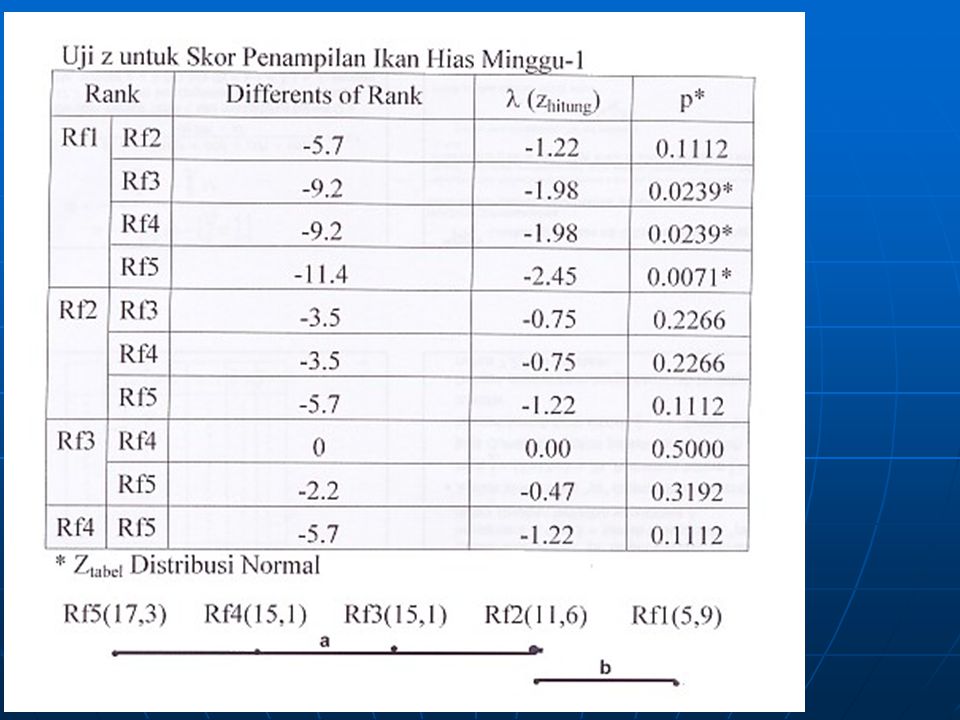
Tuan Sartoyo ingin mengetahui apakah ada perbedaan efek dari 4 perlakuan (P0, PI, PII dan PIII) masing2 terdiri dari 6 ulangan terhadap performan ikan hias, di samping itu juga ingin diketahui perlakuan mana yang dapat menyebabkan peningkatan performan ikan hias terbaik. Data hasil penelitian berupa skor kualitas penampilan ikan hias, telah selesai dianalisis dengan menggunakan program statistik SPSS rel 13.0 for Windows dengan hasil (Output) seperti tampak pada Lampiran 1.
 seperti tampak pada Lampiran 1..")
53
Lampiran 1. Analisis Statistik Skor Performan Ikan Hias Akibat Berbagai Perlakuan
NPar Tests Kruskal-Wallis Test Ranks 6 4,50 13,50 14,83 17,17 24 Perlakuan P 0 P I P II P III Total A, hari ke-5 N Mean Rank Pertanyaan: Buatlah intepretasi hasil analisis statistik tersebut, dan tentukan serta lakukan langkah lanjutnya untuk membuat kesimpulan dari penelitian yang dilakukan! Test Statistics a,b 12,052 3 ,007 Chi-Square df Asymp. Sig. A, hari ke-5 Kruskal Wallis Test a. Grouping Variable: Perlakuan b.

54
Pertanyaan: Buatlah intepretasi hasil analisis statistik tersebut, dan tentukan serta lakukan langkah lanjutnya untuk membuat kesimpulan dari penelitian yang dilakukan!

Presentasi serupa




>")











>")





>")