Upload presentasi
1
STATISTIK INFERENSIAL
RAGAM ANALISIS UNIVARIAT, BIVARIAT DAN MULTIVARIAT whisnu.t.

2
Metode Analisis Kuantitatif
Metode Analisis berdasarkan variabel dan skala pengukuran: Analisis Univariat: t Test, one way anova Analisis Bivariat: asosiasi, diferensiasi, korelasi dan regresi Analisis Multivariat: elaborasi, multiple regression, path, discriminant, factor dan cluster analysis

3
ANALISIS BIVARIAT: ASOSIASI, DIFERENSIASI, KORELASI DAN REGRESI

4
Variabel 1 Variabel 2 Nominal Ordinal Interval
Chi-square χ2 Cramer’s ν Coefficient contingency φ Lambda λ simetrik Lambda λ asimetrik t- Test (hypothesis of difference) z-test (hypothesis of difference) Eta η Kendall’s τ Spearman гs Gamma γ Sommer’s D asimetrik Pearson’s г Regression Asimetrik
 z-test (hypothesis of difference) Eta η. Kendall’s τ. Spearman гs. Gamma γ. Sommer’s D asimetrik. Pearson’s г. Regression Asimetrik.")
5
ASOSIASI - CHI SQUARE Asosiasi merujuk kepada pengukuran kekuatan hubungan dimana salah satu variabel adalah dikotomi, nominal atau ordinal. Alat ukurnya adalah chi square χ² χ²= Σ Ζ² = Σ (x-µ / σ) atau χ² = (n-1) s² / σ² atau χ²= Σ (Of-Ef)² / Ef Dimana, Of = observed frekuensi dan Ef = expected frekuensi
 atau χ² = (n-1) s² / σ² atau χ²= Σ (Of-Ef)² / Ef Dimana, Of = observed frekuensi dan Ef = expected frekuensi")
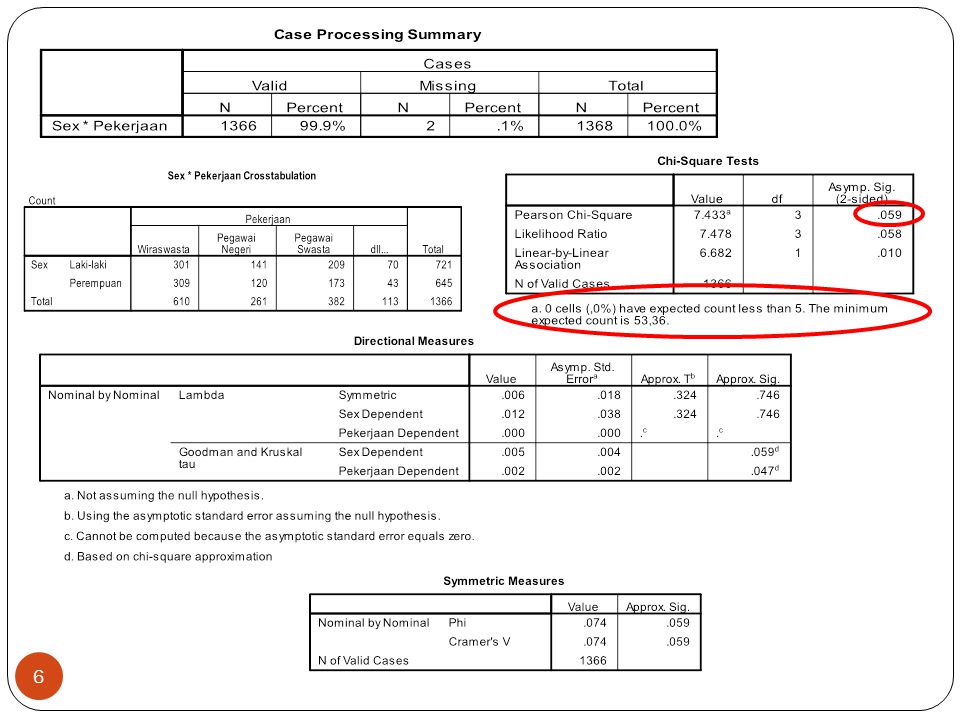
7
Pengambilan keputusan
Lihat hasil chi square test, value dan sig.059. Jgn lupa lihat cells expected count less than 5 tidak boleh lebih dari 20% untuk 2 X 2 Syarat: Nilai chi square hitung > chi square tabel, ingat df=3 dan α=5% Sig hasil < 0.05 Kekuatan hubungan dilihat pada uji pengukuran

8
KEKUATAN HUBUNGAN Interpretasi: < 0.20 lemah sekali, hampir bisa diabaikan lemah cukup kuat/moderat kuat amat kuat ...it is possible to have a relationship which displays strong association but is not significant or a relationship which displays an extremely weak association but is very significant

9
DIFERENSIASI Uji rata-rata dua sampel independen dengan t-test contoh:
Perbedaan tinggi badan antara pria dan wanita Perbedaan penghasilan antara bidang pekerjaan Perbedaan skor job satisfaction antara pegawai swasta dan pemerintah dsb

10
Untuk analisis untuk menguji apakah varians sama/ beda, dan dilihat dari nilai hitung F dan sig, syarat sig < 0.05 untuk memenuhi signifikansi Kemudian lihat t hitung dan sig-nya, syaratnya sama sig < 0.05 atau nilai lower-upper yang tidak boleh melewati (nilai) 1.
 1.")
11
Uji rata-rata dua sampel yang berpasangan
Contoh: pengujian berat badan sebelum dan sesudah mengikuti program diet Skor job satisfaction sebelum dan sesudah mengikuti pelatihan Perbedaan nilai ujian sebelum dan sesudah mengikuti tutorial

12
Lihat sig dan t hitung Syarat, Sig < 0,05 t hitung > t tabel (uji dua sisi)
")
13
KORELASI SEDERHANA Sebuah bentuk asosiasi dimana kedua variabel adalah interval Metode ini adalah yang umum dipakai untuk analisis bivariat Correlation is symmetrical, not providing evidence of which way causation flows Dalam korelasi pada beberapa kasus dapat diterapkan pada variabel yang menggunakan skala ordinal (Spearman’s model)
")
14
Pengukuran korelasi kerap diidentikkan dengan pearson’s correlation (product moment pearson) yang merupakan analisis untuk menelaah kekuatan hubungan antara dua variabel Pearson’s correlation = rxy Coefficient of determination = rxy² ...the percent of the variance in the dependent variable explained by the independent... (Garson, 2002) The proportion of the variability among the y scores that can be accounted for by the variability among the x scores (Sprinthall, 1982) rxy = 0.70 rxy² = 0.49 49% of the information about y is contained in x
 The proportion of the variability among the y scores that can be accounted for by the variability among the x scores (Sprinthall, 1982) rxy = 0.70 rxy² = % of the information about y is contained in x.")
15
Correlations

16
Nonparametrik Correlation

17
Persyaratan penggunaan Pearson’s R (Sprinthall p.193, 1982):
Bila menggunakan sampel dan ingin menarik inferensi ke populasi maka sampel harus dipilih secara acak (random) Variabel yang digunakan menggunakan skala interval Variasi dalam distribusi nilai variabel-variabel yang digunakan bisa diasumsikan serupa (homoscedasticity) Distribusi nilai dari tiap variabel harus unimodal dan cukup simetrik – the pearson’s r can almost never be used on income data since the income distribution in the population is usually skewed – Pearson’s coefficient hanya menunjukkan kemungkinan adanya hubungan linear antar variabel.
 Variabel yang digunakan menggunakan skala interval. Variasi dalam distribusi nilai variabel-variabel yang digunakan bisa diasumsikan serupa (homoscedasticity) Distribusi nilai dari tiap variabel harus unimodal dan cukup simetrik – the pearson’s r can almost never be used on income data since the income distribution in the population is usually skewed – Pearson’s coefficient hanya menunjukkan kemungkinan adanya hubungan linear antar variabel.")
18
REGRESI SEDERHANA Analisis regresi digunakan untuk tujuan peramalan, dan menganalisis bentuk hubungan antara dua variabel dengan mengembangkan estimating equation (persamaan regresi) Analisis regresi = β Banyak diterapkan pada area bisnis, untuk memprediksi hubungan iklan dengan penjualan, tes sikap dengan kinerja karyawan, rasio keuangan dengan harga saham,dsb
 Analisis regresi = β Banyak diterapkan pada area bisnis, untuk memprediksi hubungan iklan dengan penjualan, tes sikap dengan kinerja karyawan, rasio keuangan dengan harga saham,dsb")
19
Analisis: Adanya nilai rata-rata dan standar deviasi serta total sampel Adanya hubungan yang kuat dan nyata antara orientasi politik dan penggunaan media Angka r square .596 adalah 59,6% orientasi politik diprediksi oleh penggunaan media

20
Analisis: Dari hasil uji ANOVA dan nilai F test, dilihat bahwa F = dan tingkat signifikansi .000 jauh lebih kecil dari .050, maka model regresi bisa digunakan untuk memprediksi orientasi politik Persamaan regresi Y = X

21
Bagaimana mengetahui distribusi normal?
Variabel yang akan digunakan bisa dihitung koefisien pearson- nya: Sk = 3( X- Me) / S Sk = Koefisien Pearson X = Rata-rata Me = Median S = Standar deviasi
 / S Sk = Koefisien Pearson X = Rata-rata Me = Median S = Standar deviasi")
22
ANALISIS MULTIVARIAT ELABORASI, REGRESI BERGANDA, ANALISIS JALUR (PATH), DISKRIMINAN, ANALISIS FAKTOR DAN ANALISIS KELOMPOK (CLUSTER)
, DISKRIMINAN, ANALISIS FAKTOR DAN ANALISIS KELOMPOK (CLUSTER)")
23
MULTIVARIATE ANALYSIS
Elaboration Contingency tables Split correlation analysis High order partial analysis Path analysis Multiple regression prediction Differentiation Discriminant analysis Manova Exploration Factor analysis Cluster analysis

24
ELABORATION AND PARTIAL CORRELATION
Partial correlation is the correlation of two variables while controlling for a third or more other variables (maximum 3 controlling variables) The extended model of partial correlation is path analysis or structural equation modeling when data are near or at interval level or use log-linear modeling for lower level data
 The extended model of partial correlation is path analysis or structural equation modeling when data are near or at interval level or use log-linear modeling for lower level data")
25
Statistical requirements for intervening and antecedent variables
Intervening variable All the three variables (intervening, independent and dependent) must be related (theoretically) When intervening variable is controlled, the relationship between independent and dependent variable should vanish When independent variable is controlled, the relationship between intervening and dependent variable should not disappear Antecedent variable When antecedent variable is controlled, the relationship between independent and dependent variable should not vanish When independent variable is controlled, the relationship between antecedent and dependent variable should disappear
 must be related (theoretically) When intervening variable is controlled, the relationship between independent and dependent variable should vanish. When independent variable is controlled, the relationship between intervening and dependent variable should not disappear. Antecedent variable. When antecedent variable is controlled, the relationship between independent and dependent variable should not vanish. When independent variable is controlled, the relationship between antecedent and dependent variable should disappear.")
26
PARTIAL CORRELATION Tingkat liberalisme ekonomi (antiseden)
Proporsi middle class independen (independen) Intensitas tuntutan demokrasi (intervening) Tingkat demokratisasi sistem politik (dependen) Fragmentasi kekuasaan elit politik (control)
 Intensitas tuntutan demokrasi (intervening) Tingkat demokratisasi sistem politik (dependen) Fragmentasi kekuasaan elit politik (control)")
27
PATH ANALYSIS Sociability Intensity Peer group Gratification sought
Gratification obtained Gratification deficiency Socio economic status & Sex Demographic Interactivity Media ownership

28
Kemungkinan suatu hasil elaborasi
Konstan Replikasi variabel ketiga tidak mempengaruhi Melemah Eksplanasi variabel ketiga mempengaruhi sebagai anteseden (menjelaskan) Intepretasi variabel ketiga mempengaruhi sebagai intervening (menafsirkan) Terbelah Spesifikasi variabel ketiga mempengaruhi sebagai merinci variabel Menguat Suppressor/distorter variabel ketiga mempengaruhi sebagai distorter/suppressor
 Intepretasi variabel ketiga mempengaruhi sebagai intervening (menafsirkan) Terbelah. Spesifikasi variabel ketiga mempengaruhi sebagai merinci variabel. Menguat. Suppressor/distorter variabel ketiga mempengaruhi sebagai distorter/suppressor.")
29
Teknik-teknik Elaborasi
CONTINGENCY TABLES Variabel independen dan dependen nominal/ordinal Variabel kontrol nominal/ordinal Kategori nilai variabel kontrol tidak terlalu banyak Semakin banyak variabel kontrol akan semakin besar sampel yang dibutuhkan SPLIT/DIFFERENTIAL ANALYSIS Variabel independen dan dependen interval Kategori nilai variabel kontrol tidak terlalu besar HIGH ORDER PARTIAL ANALYSIS Variabel kontrol interval Jumlah variabel kontrol tidak tergantung besar sampel

30
Pengaruh gaya hidup terhadap orientasi politik pelajar SMA dengan penggunaan media sebagai variabel control Dari hasil terlihat bahwa penggunaan media menjadi intervening atau anteseden

31
MULTIPLE REGRESSION Suatu teknik analisis untuk memprediksi nilai sebuah dependen variabel berdasarkan nilai-nilai sejumlah variabel independen Ada beberapa metode penghitungan regresi berganda: Enter Backward elimination Forward elimination Stepwise method

32
Analisis untuk dua variabel independen model enter,
95,2% orientasi politik dapat dijelaskan oleh variabel gaya hidup dan penggunaan media nilai sig dari tabel anova adalah .000 dimana model regresi yang digunakan dapat memprediksi orientasi politik Y = 11, ,857 X1 + 5,047 X2 sebagai persamaan regresinya

33
Model backward elimination, analisis
Lihat tabel model summary pada adjusted R square (utk >2 variabel bebas) Ada empat model yang dihasilkan, dan model ke 4 yang memiliki hasil terbesar 94,4% penjualan dapat dijelaskan oleh variabel jumlah outlet dan promosi
 Ada empat model yang dihasilkan, dan model ke 4 yang memiliki hasil terbesar. 94,4% penjualan dapat dijelaskan oleh variabel jumlah outlet dan promosi.")
34
Analisis, Model 4 memiliki angka sig .000 (syarat < .005) maka model regresi dapat digunakan
 maka model regresi dapat digunakan")
35
Analisis kolinearitas,
Untuk melihat hubungan diantara variabel-variabel independennya, apakah terjadi kolinearitas Lihat angka tolerance, contoh lihat model 1 pada pendapatan. Diadapat angka tolerance 0,750 yang berarti R² adalah 1 – 0,075 = 0,250. Jadi hanya 25% variabel pendapatan bisa dijelaskan oleh variabel independen lain atau lihat VIF, dimana VIF = 1/Tolerance, angka VIF tidak boleh lebih besar dari 5, karena terjadi multi koleniaritas diantara variabel-variabel bebasnya Y = 54, ,342 X1 + 0,535 X2

36
Model forward elimination
Analisis datanya sama seperti metode backward elimination!

37
Model stepwise Analisis sama seperti model backward, dan metode ini yang paling sering digunakan untuk analisis regresi berganda!

38
PATH ANALYSIS is a causal model to understanding relationship between variables (Babbie, 1973 p.324) is a statistical technique that can be used to find out the differences between two or more group of objects with respect to several variables simultaneously (Klecka, 1980) an explicit hypothesis of cause and effect that is tested using the method of path analysis (Phil Ender, 2002) “However convincing, respectable, dan reasonable a path diagram may appear, any causal inferences extracted are rarely more than a form of statistical fantasy” (Everit and Dunn, 1991)
 is a statistical technique that can be used to find out the differences between two or more group of objects with respect to several variables simultaneously (Klecka, 1980) an explicit hypothesis of cause and effect that is tested using the method of path analysis (Phil Ender, 2002) However convincing, respectable, dan reasonable a path diagram may appear, any causal inferences extracted are rarely more than a form of statistical fantasy (Everit and Dunn, 1991)")
39
DISCRIMINANT ANALYSIS
Discriminant function analysis, known discriminant analysis or DA, is used to classify cases into the values of a categorical dependent, usually a dichotomy. If discriminant function analysis is effecetive for a set of data, classification table of correct and incorrect estimates will yield a high percentage correct. There are several purposes of DA: To investigate differences between groups To determine the most parsimonious way to distinguish between groups To discard variables which are little related to group distinctions To classify cases into groups To test theory by observing whether cases are classified as predicted

40
Discriminant analysis (Garson, 2002)
shares all the usual assumptions of correlation, requiring linear and homoscedastic realtionship, and untruncated interval or near interval data like multiple regression, it also assumes proper model specification (inclusion of all important independents and exclusion of extraneous variables) assumes the dependent variable is a true dichotomy since data which are forced into dichotomous coding are truncated, attenuating correlation is an earliezr alternative to logistic regression,which is now frequently used in place of DA, as it usually involves fewer violations of assumption, is robust, and has coefficients which many find easier to interpret
 assumes the dependent variable is a true dichotomy since data which are forced into dichotomous coding are truncated, attenuating correlation. is an earliezr alternative to logistic regression,which is now frequently used in place of DA, as it usually involves fewer violations of assumption, is robust, and has coefficients which many find easier to interpret.")
41
Assumption for discriminant analysis
Dependent variable are a true dichotomy. One should never dichotomize a continuous variable simply for the purpose of applying discriminant analysis All cases must be independent and must belong to a group formed by the dependent variable. The groups must be mutually exclusive Group sizes of the dependent aren not grossly different Independent variable(s) is interval, and dichotomies, dummy variables and ordinal variables with at least 5 categories are commonly used The maximum number of independent variables is n-2, where n is the sample size Homogeneity of variances (homoscedasticity) within each group formed by dependent, and variance of independent should be similar between groups Absence of perfect multicollinearity, of independent variables will produce tolerance value approaching 0 and the matrix won’t have a unique discriminant solution Low multicollinearity of independent, to the extent independents are correlated, the standardized discriminant function coefficient will not reliablyy assess the realative importance of the predictor variables
 is interval, and dichotomies, dummy variables and ordinal variables with at least 5 categories are commonly used. The maximum number of independent variables is n-2, where n is the sample size. Homogeneity of variances (homoscedasticity) within each group formed by dependent, and variance of independent should be similar between groups. Absence of perfect multicollinearity, of independent variables will produce tolerance value approaching 0 and the matrix won’t have a unique discriminant solution. Low multicollinearity of independent, to the extent independents are correlated, the standardized discriminant function coefficient will not reliablyy assess the realative importance of the predictor variables.")
42
FACTOR ANALYSIS is a statistical technique used to identify a realtive small number of factors that can be used to represent relationship among sets of many interrelated variables (Norusis, 1993 p.47) The goal of factor analysis is to identify the not-directly-observable factors based on a set of observable variables Two models of factor analysis: Exploratory factor analysis (EFA) to uncover the underlying structure of a realtively large set of variables. There’s no prior theory and one uses factor loadings to intuit the factor structure of the data Confirmatory factor analysis (CFA) to determine if the number of factors and the loading if measured (indicator) variables in them conform ti what is expected on the basis of pre-established theory
 The goal of factor analysis is to identify the not-directly-observable factors based on a set of observable variables. Two models of factor analysis: Exploratory factor analysis (EFA) to uncover the underlying structure of a realtively large set of variables. There’s no prior theory and one uses factor loadings to intuit the factor structure of the data. Confirmatory factor analysis (CFA) to determine if the number of factors and the loading if measured (indicator) variables in them conform ti what is expected on the basis of pre-established theory.")
43
The purposes of factor analysis:
To reduce a large number if variables to a smaller number of factors for modelling purposes. Factor analysis is intergrated in structural equation modelling (SEM) To select a subset of variables from a larger set, based on which original variables have the highest correlations with the principal component factors To create a set of factors to be treated as uncorrelated variables as one approach to handling multicollinearity in such procedures as multiple regression To validate a scale or index by demonstrating that its constituent items load on the same factor, and to drop proposed scale items which cross-load on more than one factor To establish that multiple tests measure the same factor, thereby giving justification for administering fewer tests To identify clusters of cases and or outliers
 To select a subset of variables from a larger set, based on which original variables have the highest correlations with the principal component factors. To create a set of factors to be treated as uncorrelated variables as one approach to handling multicollinearity in such procedures as multiple regression. To validate a scale or index by demonstrating that its constituent items load on the same factor, and to drop proposed scale items which cross-load on more than one factor. To establish that multiple tests measure the same factor, thereby giving justification for administering fewer tests. To identify clusters of cases and or outliers.")
44
Menguji konsep liberalism dengan faktor analysis
Concept Dimensions Sub dimensions LIBERALISM ECONOMIC LIBERALISM hapus monopoli zona free trade potong subsidi privatisasi BUMN PERSONAL LIBERALISM aborsi ekstramarital sex kebebasan beragama kesetaraan gender persamaan ras POLITICAL LIBERALISM oposisi kebebasan berserikat kebebasan berpendapat multipartai ekstra parlementer

45
CLUSTER ANALYSIS Also called segementation analysis, classification analysis or numerical taxonomy analysis, is similar in purpose to Q-mode factor analysis – both seek to identify homogenous subgroups of cases in a population. That is cluster analysis seeks to identify a set of groups which both minimize within-group variation and maximize between-group variation Objects in each cluster tend to be similar to each other and dissimilar to objects in the other clusters Suatu teknik statistik untuk mengelompokkan satuan-satuan analisis kedalam sejumlah cluster, berdasarkan kesamaan (similarities/likeness) atas sejumlah karakteristik yang dimiliki satuan analisis
 atas sejumlah karakteristik yang dimiliki satuan analisis")
46
Konsep dasar dan situasi ideal clustering

47
Clustering variabel gaya hidup remaja dengan metode K-Means

48
Ditemukan empat buah cluster dari variable gaya hidup:
demander adalah kelompok remaja yang mempunyai skor gaya hidup yang tinggi, sehingga mereka cenderung sering menjalankan aktivitas, memiliki opini serta minat terhadap semua simensi dalam gaya hidup. anti demander, dimana mereka mempunyai skor yang sangat rendah dalam pengukuran gaya hidup. escapist adalah kelompok individu yang cenderung mempunyai gaya hidup fun, hedonis serta tidak tanggap terhadap lingkungan sosial mereka. pro-social, yang bercirikan cukup responsif dalam meyikapi segala persoalan sosial yang terjadi di lingkungannya.

49
Checks on the quality of clustering results:
Perform cluster analysis on the same data using different measures. Compare the results across measures to determine the stability of the solutions Use different method of clustering and compare the results Split data randomly into halves. Perform clustering separately on each half Delete variables randomly. Perform clustering based on the reduced set of variables. Compare the results with those obtained by clustering based on the entire set of variables In non hierarchical clustering, the solution may depend on the order of cases in the data set. Make multiple runs using different order of cases until the solution stabilizes





>")








>")

.>")




