Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Pemrosesan Teks Klasterisasi Dokumen Teknik Informatika STMIK GI MDP 2013
Shinta P.

2
Klasterisasi Dokumen Organisasi otomatis dokumen ke dalam kelompok tertentu sehingga dokumen dalam klaster /kelompok memiliki kesamaan yang tinggi dibandingkan dengan satu sama lain, tetapi sangat berbeda dengan dokumen dalam klaster lain. Bentuk pembelajaran tak terawasi (unsupervised Learning)
")
3
Ilustrasi klasterisasi

4
Clustering Alhorithm Connectivity Clustering (Hierarcical Clustering)
Single Link Average Link Complete Link Centroid Based Clustering K-Means Etc.

5
Hierarchical clustering
Mengatur kelompok dalam hirarki (subjek) sedemikian rupa sehingga hubungan orangtua-anak antara node dalam hirarki dapat dilihat sebagai topik dan subtopik. agriculture biology physics CS space ... ... ... ... ... dairy botany cell AI courses crops craft magnetism agronomy HCI missions forestry evolution relativity
 sedemikian rupa sehingga hubungan orangtua-anak antara node dalam hirarki dapat dilihat sebagai topik dan subtopik. agriculture. biology. physics. CS. space dairy. botany. cell. AI. courses. crops. craft. magnetism. agronomy. HCI. missions. forestry. evolution. relativity.")
6
Hierarchical clustering
metode analisis cluster yang berusaha untuk membangun sebuah hirarki cluster. Agglomerative: Pendekatan "bottom up“, setiap pengamatan dimulai dalam cluster sendiri, dan pasangan cluster digabung sebagai salah satu hirarki bergerak naik . Devisive: Pendekatan "top down“ , semua pengamatan dimulai dalam satu cluster, dan perpecahan yang dilakukan secara rekursif bergerak ke hirarki bawah.

7
Single Link Clustering
strategi bottom-up: membandingkan setiap titik dengan masing-masing titik. Setiap objek ditempatkan dalam sebuah cluster yang terpisah, dan pada setiap langkah kita menggabungkan pasangan terdekat cluster, sampai kondisi penghentian tertentu dipenuhi kedekatan dua kelompok didefinisikan sebagai minimum jarak antara dua titik dalam dua kelompok. Min { d(a,b) , a A, b B}
 , a A, b B}")
8
MIN C A B D 1 A B C D 1 2 Dendogram - menampilkan informasi yang sama seperti pada grafik di atas, namun batas jarak vertikal, dan poin di bagian bawah (horisontal). Ketinggian di mana dua kelompok digabung dalam dendogram mencerminkan jarak dua kelompok.
. Ketinggian di mana dua kelompok digabung dalam dendogram mencerminkan jarak dua kelompok.")
9
Dendogram A B C D E 1 2 3

10
Contoh: Asumsikan bahwa D database yang diberikan oleh tabel di bawah ini. Ikuti teknik link tunggal untuk menemukan cluster di database berikut. Gunakan ukuran jarak Euclidean! x y p1 0.40 0.53 p2 0.22 0.38 p3 0.35 0.32 p4 0.26 0.19 p5 0.08 0.41 p6 0.45 0.30

11
Langkah 1. Plot benda-benda di ruang n-dimensi (dimana n adalah jumlah atribut). Dalam kasus kami, kami memiliki 2 atribut - x dan y, jadi kami merencanakan obyek p1, p2, ... p6 dalam ruang 2-dimensi: Langkah 2. Hitung jarak dari setiap objek (titik) ke semua titik lain, menggunakan ukuran jarak Euclidean, dan menempatkan angka dalam matriks jarak.
 ke semua titik lain, menggunakan ukuran jarak Euclidean, dan menempatkan angka dalam matriks jarak..")
12
Matrix Jarak

13
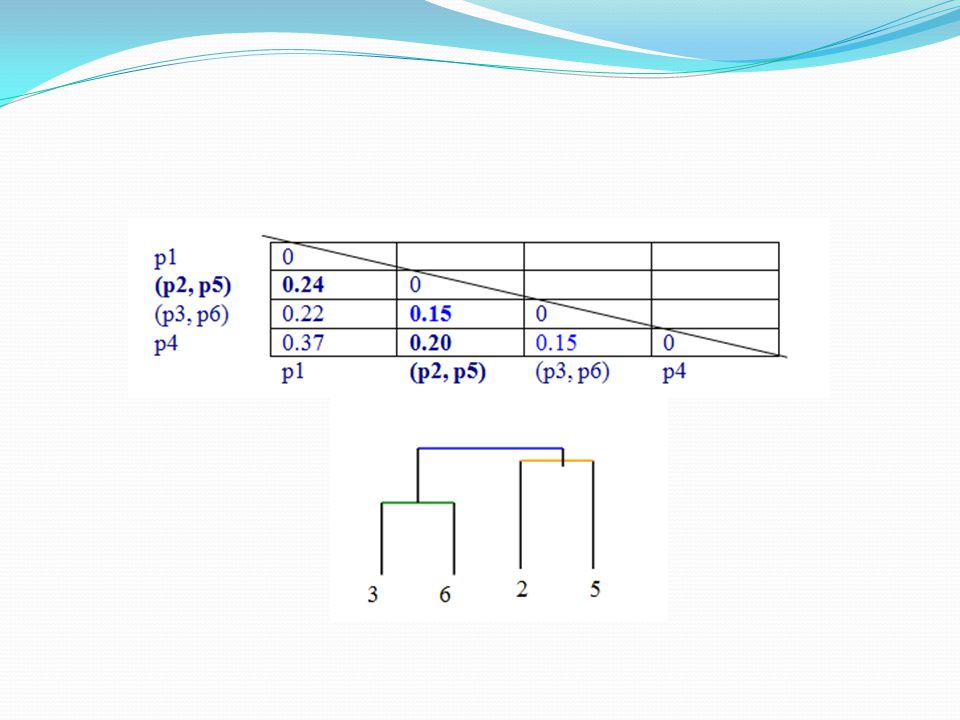
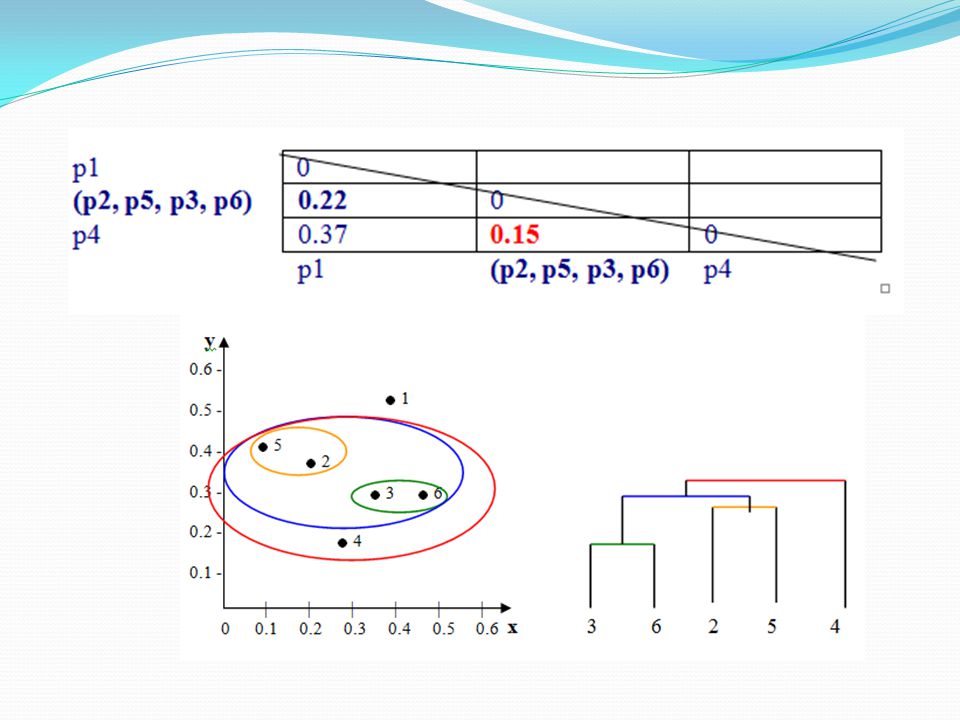
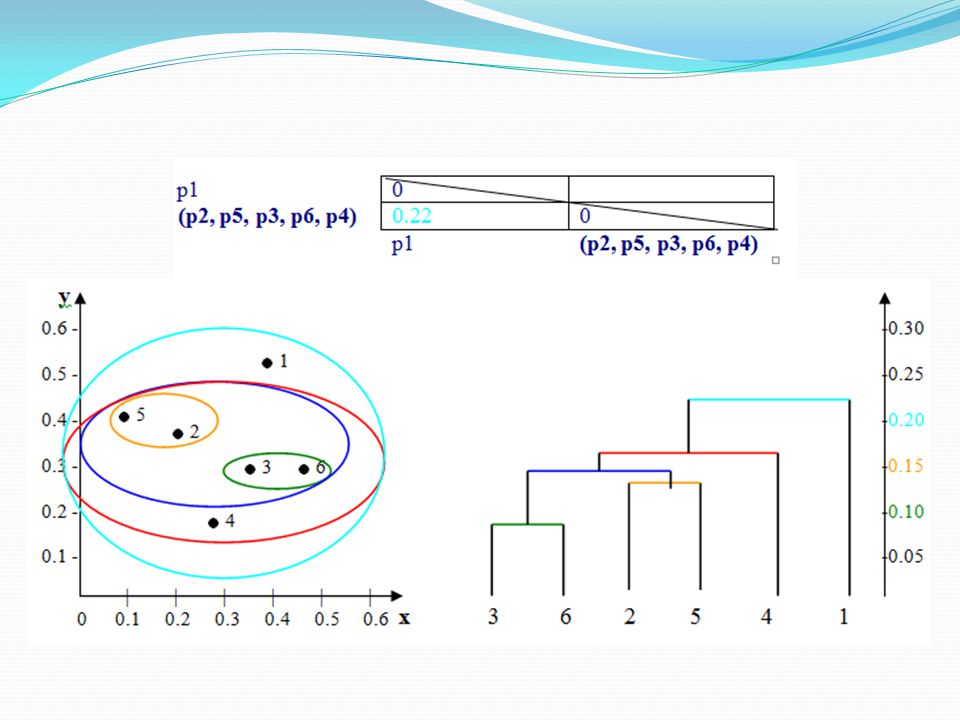
Langkah 3 : Mengidentifikasi dua kelompok dengan jarak terpendek dalam matriks, dan menggabungkan mereka bersama-sama. Re-menghitung matriks jarak, sebagai dua cluster sekarang dalam satu cluster. Dengan melihat matrik jarak di atas, kita melihat bahwa p3 dan p6 memiliki jarak terkecil dari semua Jadi, kita gabungkan kedua dalam satu cluster, dan kembali menghitung matriks jarak.

18
K-Means Pembagian menjadi sejumlah kluster
Setiap Klaster memiliki sebuah pusat (Centroid) menggunakan nilai Mean nilai tiap titik. Nilai Mean dapat berubah dalam tiap iterasi . Tiap titik akan berasosiasi dengan cluster dengan jarak ttik dan centroid terdekat (Euclidean Distance). Jumlah kluster, K, diinisialisasi awal
 menggunakan nilai Mean nilai tiap titik. Nilai Mean dapat berubah dalam tiap iterasi . Tiap titik akan berasosiasi dengan cluster dengan jarak ttik dan centroid terdekat (Euclidean Distance). Jumlah kluster, K, diinisialisasi awal.")
19
Contoh: Berikut delapan titik (dengan (x, y) yang menyatakan lokasi) menjadi tiga kelompok : A1 (2, 10) A2 (2, 5) A3 (8, 4) A4 (5, 8) A5 (7, 5) A6 (6, 4) A7 (1, 2) A8 (4, 9). Pusat klaster awal adalah: A1 (2, 10), A4 (5, 8) dan A7 (1, 2). Fungsi jarak antara dua titik a = (x1, y1) dan b = (x2, y2) didefinisikan sebagai: ρ (a, b) = | x2 - x1 | + | y2 - y1 |. Gunakan K-means untuk menemukan pusat klaster tiga setelah iterasi kedua!
 yang menyatakan lokasi) menjadi tiga kelompok : A1 (2, 10) A2 (2, 5) A3 (8, 4) A4 (5, 8) A5 (7, 5) A6 (6, 4) A7 (1, 2) A8 (4, 9). Pusat klaster awal adalah: A1 (2, 10), A4 (5, 8) dan A7 (1, 2). Fungsi jarak antara dua titik a = (x1, y1) dan b = (x2, y2) didefinisikan sebagai: ρ (a, b) = | x2 - x1 | + | y2 - y1 |. Gunakan K-means untuk menemukan pusat klaster tiga setelah iterasi kedua!")
20
Iterasi-1 :

21
Iterasi-1 (lanjutan):
:")
22
Iterasi-2 : Hitung Centroid baru
Klaster -1 : A1 (2,10) Klaster-2: A3, A4, A5, A6, A8 = ( ( )/5, ( )/5 ) = (6, 6) Klaster-3: A2, A7 = ( (2+1)/2, (5+2)/2 ) = (1.5, 3.5) Ulangi iterasi hingga Mean tiap klaster tidak lagi berubah.
 Klaster-2: A3, A4, A5, A6, A8. = ( ( )/5, ( )/5 ) = (6, 6) Klaster-3: A2, A7 = ( (2+1)/2, (5+2)/2 ) = (1.5, 3.5) Ulangi iterasi hingga Mean tiap klaster tidak lagi berubah.")
Presentasi serupa






![Model Datamining Dr. Sri Kusumadewi, S.Si., MT. Materi Kuliah [10]:](/8/2453557/big_thumb.jpg "Model Datamining Dr. Sri Kusumadewi, S.Si., MT. Materi Kuliah [10]:>")








 Self-Organizing Map>")
 LOGIKA FUZZY>")
 Wahyul Wahidah Maulida, ST., M.Eng.>")
>")
 LOGIKA FUZZY>")
