Upload presentasi
Presentasi sedang didownload. Silahkan tunggu

1
Chapter 9 ALGORITME Cluster dan WEKA
Clustering K-Means Case Definition Sulidar Fitri, M.Sc

2
REFERENCES Jiawei Han and Micheline Kamber. Data Mining: Concepts and Techniques Department of Computer Science University of Illinois at Urbana-Champaign. Ian H. Witten, Eibe Frank, Mark A. Hall. Data Mining Practical Machine Learning Tools and Techniques Third Edition Elsevier Kusrini dan Luthfi, E., 2009, Algoritma Data Mining, Penerbit Andi Kusrini, Pattern Recognition. WEKA

3
Clustering Introduction
The previous data mining task of classification deals with partitioning data based on a pre-classified training sample Clustering is an automated process to group related records together. Related records are grouped together on the basis of having similar values for attributes The groups are usually disjoint

4
Via (Yohana, 2011)
")
5
(Larose, 2005)
")
6
Contoh Kasus: Proses pendeskritan kelas kontinyu
Input Data awal, berupa data kontinyu atau data diskret Delta, yaitu nilai yang digunakan untuk menentukan selisih centroid dan mean yang diijinkan Output: tabel pemetaan yang berisi kelas diskret beserta nilai centroidnya

7
Langkah Proses: Tentukan jumlah cluster
Alokasikan data ke dalam cluster secara random Hitung centroid/rata-rata dari data yang ada di masing-masing cluster Alokasikan masing-masing data ke centroid/rata-rata terdekat Kembali ke Step 3, apabila masih ada data yang berpindah cluster atau apabila perubahan nilai centroid, ada yang di atas nilai threshold yang ditentukan atau apabila perubahan nilai pada objective function yang digunakan di atas nilai threshold yang ditentukan

8
Penentuan centroid: acak atau ditentukan dengan rumus

9
Input: 79, 85, 83, 90, 82, 81, 85, 87, 89 dan 84 Jumlah kelas target: 3 delta : 0,01 Proses: Min: 79 Max : 90 Toleransi error: 0.01 * (90-79) : 0.11
 :")
10
Min: 79, max: 90 Centroid awal C2 dan C3?

11
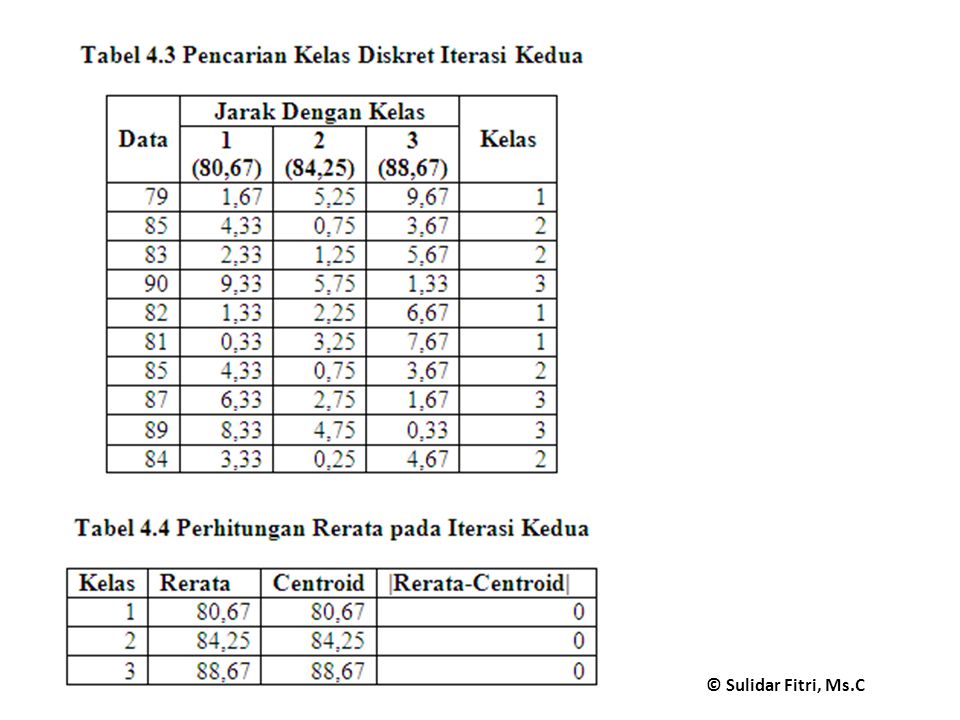
0,92 > error (0.11) Rerata menjadi centroid baru
 Rerata menjadi centroid baru")
13
WEKA PRACTICE

14
Clustering Buka weka dan input data .arff Pilih tab Cluster
Choose algoritma kMeans Pilih Cluster/kelompok yang diinginkan berapa Start Baca outputnya

15
GET STARTED

16
Any Queries ?

Presentasi serupa


>")





![Model Datamining Dr. Sri Kusumadewi, S.Si., MT. Materi Kuliah [10]:](/8/2453557/big_thumb.jpg "Model Datamining Dr. Sri Kusumadewi, S.Si., MT. Materi Kuliah [10]:>")

>")





>")


